

Javascript引擎是单线程机制,首先我们要了解Javascript语言为什么是单线程
JavaScript的主要用途主要是用户互动,和操作DOM。如果JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时这两个节点会有很大冲突,为了避免这个冲突,所以决定了它只能是单线程,否则会带来很复杂的同步问题。此外HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程(UI线程, 异步HTTP请求线程, 定时触发器线程...),但是子线程完全受主线程控制,这个新标准并没有改变JavaScript单线程的本质。
在了解event loop之前,我们先了解一下什么是栈和队列,他们有什么特点?请先看两张图。
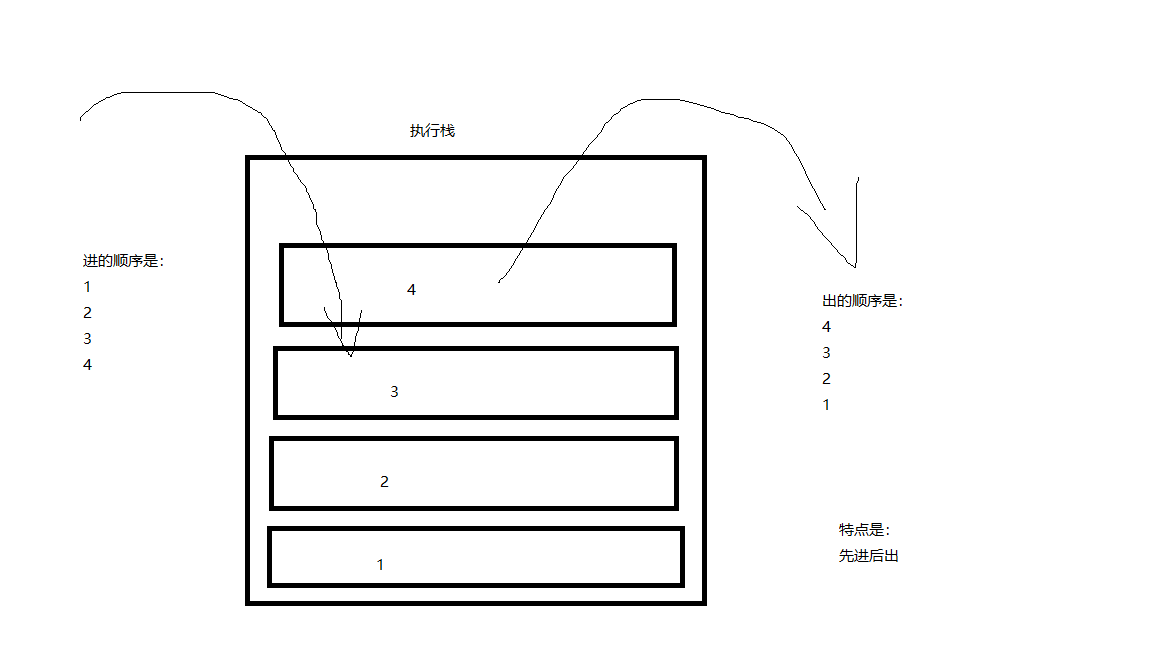
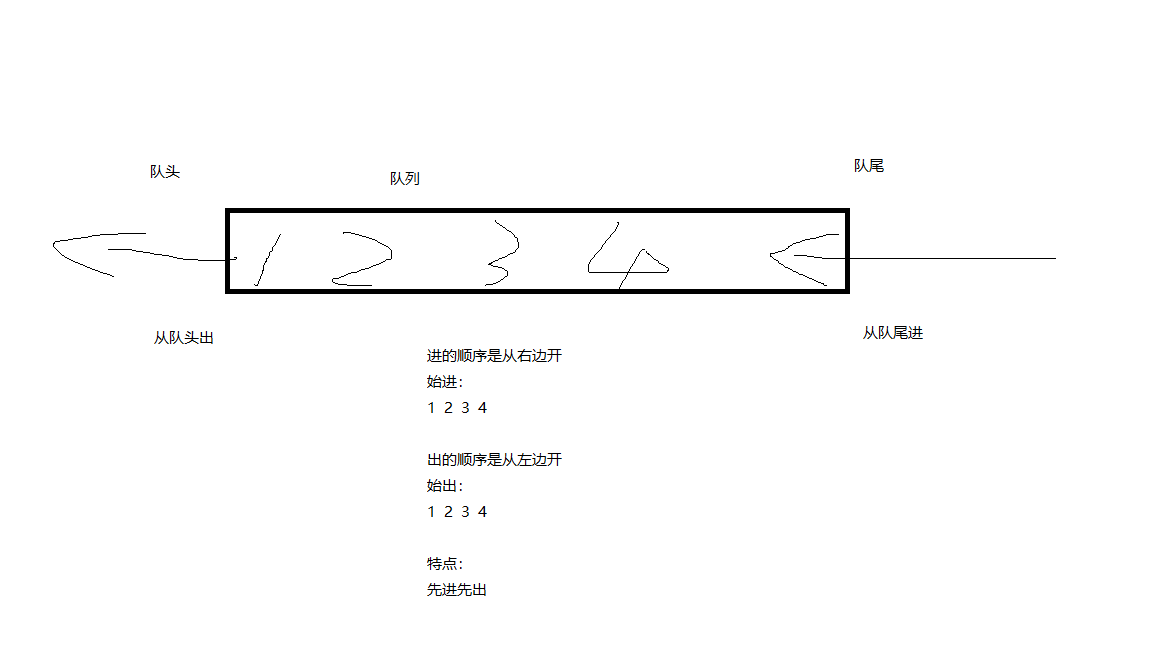
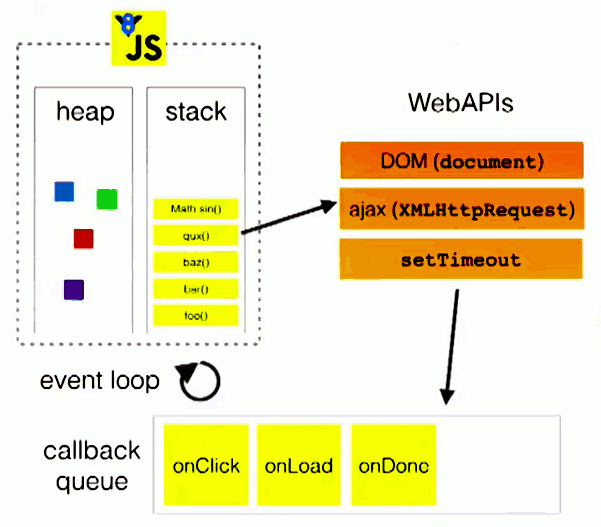
console.log(1);
setTimeout(function(){
console.log(2)
},0)
setTimeout(function(){
console.log(3)
},0)
console.log('ok');
这段代码中,会先把setTimeout的方法移到队列中,当栈里的代码执行完之后,会把队列里方法取出来放到栈中执行,所以执行结果是:
1
ok
2
3
再对这串代码进行扩展
console.log(1);
//A
setTimeout(function(){
console.log(2);
//C
setTimeout(function(){
console.log(4);
//D
setTimeout(function(){
console.log(5);
})
})
},0)
//B
setTimeout(function(){
console.log(3);
//E
setTimeout(function(){
console.log(6);
})
},0)
console.log('ok');
这串代码中,栈的代码执行的时候,当触发回调函数时,会将回调函数放到队列中,所以,先输出1和ok。栈里的代码执行完之后,会先读取第一个setTimeout,输出2,这时发现里面还有一个setTimeout(既C行下的setTimeout),这个setTimeout又会放到队列中去。然后执行B行下的setTimeout,输出3,这时E行下还有个setTimeout,这个setTimeout又会放到队列中。当栈里代码执行完之后,又会在队列中读取代码,这时读取的是C行下的setTimeout,放到栈执行,输出4,紧接着又发现D行下有setTimeout,这个setTimeout又放到队列中排队。栈的代码执行完了,又在队列中读取E行下的setTimeout,输出6。执行完之后,又在队列里读取D行下的setTimeout,输出5。所以输出结果是:
1
ok
2
3
4
6
5
附图讲解:
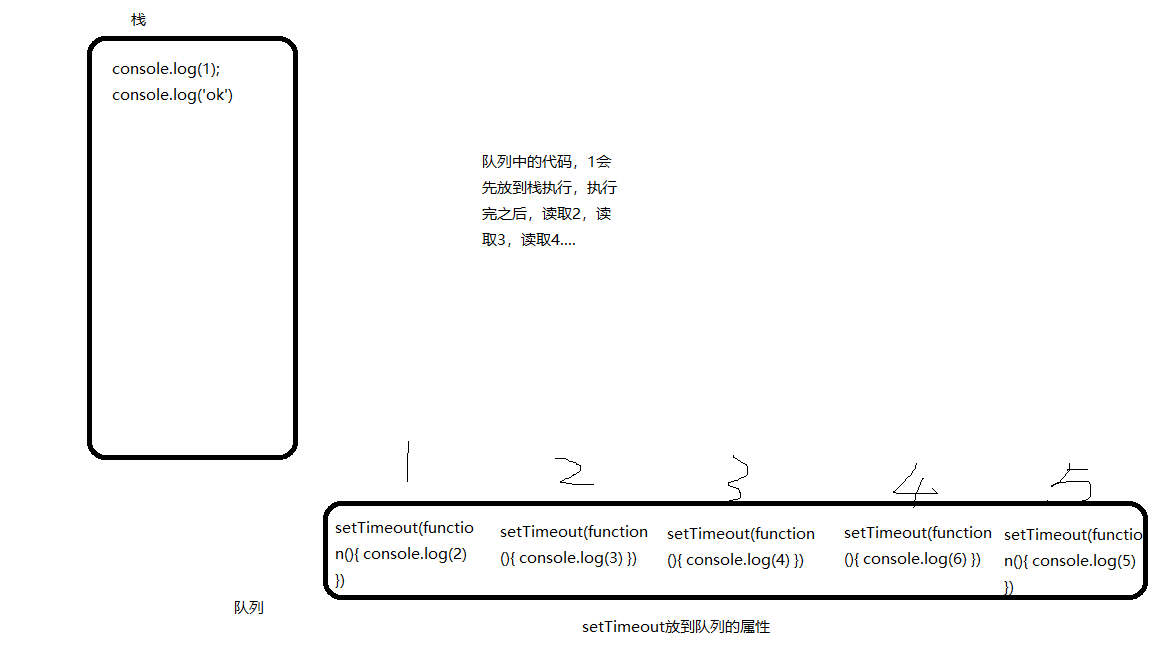
setTiemout(function(){
console.log(1)
},0)
for(var i = 0;i<1000;i++){
console.log(i)
}
在当前队列里看到setTimeout,它会等着看事件什么时候成功。所以它会先往下走,走完以后,再把setTimeout里的回调函数放到队列中。即使for循环的代码走了10s,回调函数也会等到10s后再执行。 所以,浏览器的机制永远是:先走完栈里代码,才会到队列里去。
宏任务和微任务
任务可分为宏任务和微任务 宏任务:setTimeout,setInterval,setImmediate,I/O 微任务:process.nextTick,Promise.then 队列可以看成是一个宏任务。
微任务是怎么执行的? 同步代码先在栈中执行的,执行完之后,微任务会先执行,再执行宏任务。 先看一个例子:
console.log(1)
setTimeout(function(){
console.log('setTimeout')
},0)
let promise = new Promise(function(resolve,reject){
console.log(3);
resolve(100);
}).then(function(data){
console.log(200)
})
console.log(2)
想一想会输出什么? 代码由上到下执行,所以肯定先输出1。setTimeout是宏任务,会先放到队列中。而new Promise是立即执行的,它是同步的,所以会先输出3。因为then是异步的,所以会先输出2。因为then是微任务,微任务走完,才会走宏任务。所以最终输出的结果是:1 3 2 200 setTimeout。 **注意:**浏览器的机制是把then方法放到微任务中。 浏览器机制:
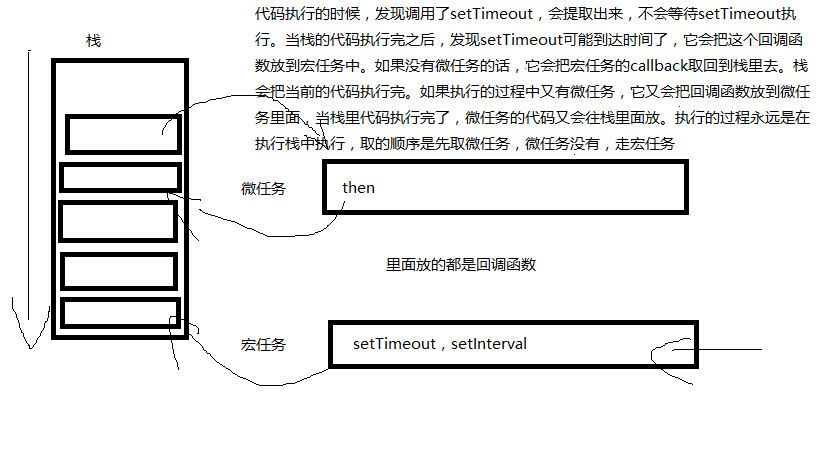
猜猜看:
console.log(1);
setTimeout(function(){
console.log(2);
Promise.resolve(1).then(function(){
console.log('ok')
})
})
setTimeout(function(){
console.log(3)
})
你猜输出什么~ 分析:先默认走栈,输出1。此时并没有微任务,所以微任务不会执行。先走第一个setTimeout,输出2,同时将微任务放到队列中,执行微任务,输出ok,微任务执行完,再走宏任务,输出3。
**注意:**浏览器和node环境输出是不一样的哦~
---------此处是分割线------------
node的event loop
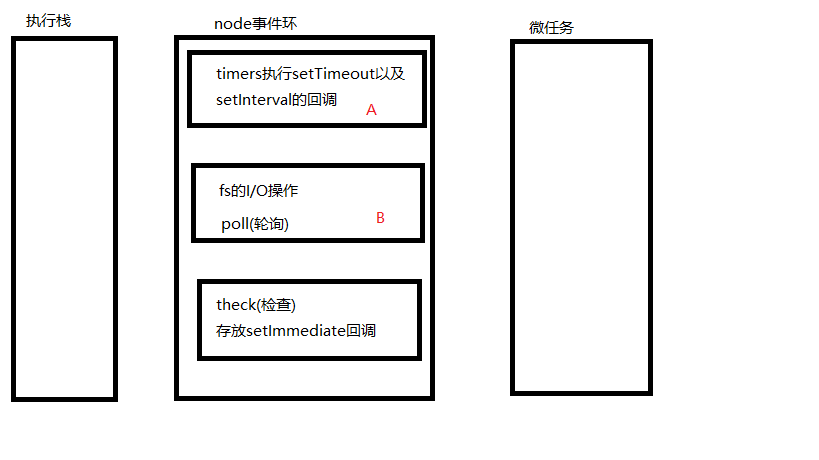
接下来说说node的事件环。 先画张图吧
console.log(1);
setTimeout(function(){
console.log(2);
Promise.resolve(1).then(function(){
console.log('ok')
})
})
setTimeout(function(){
console.log(3)
})
先将2个定时器放到A中,先输出1;这时候栈里走完了,该走事件环了。在走事件环之前,会先将微任务清空,第一次微任务没有东西,就滤过了。之后该走事件环了,这时候先走timers。这时候setTimeout不一定到达时间,如果到达时间,就直接执行了。如果时间没到达,这时候可能先略过,接着往下走,走到poll轮询阶段,发现没有读文件之类的操作,然后它会等着,等到setTimeout的时间到达。如果时间到达了,它会把到达时间的定时器全部执行。比如先走第一个setTimeout,并且把then方法放到微任务中。它会把到达时间的setTimeout队列全部清掉(全部执行完),再走微任务。假如poll轮询有很多个I/O操作,它会把I/O操作都走完,再走timers。它是一个队列一个队列的清空,而不是取出一个,执行一下,取出一个,执行一下。所以它会把2个setTimeout都走完,再走then。所以在node的输出结果是:
1
2
3
ok
再来个进阶的栗子:
process.nextTick(function(){
console.log(1)
})
setImmediate(function(){
console.log(2)
})
它会先走栈的内容,栈啥都没有。当它要走事件环的时候,会将微任务清空。发现微任务有nextTick,它会把nextTick执行完,再走事件环。发现timers和poll都没有东西,它就会走theck阶段。 nextTick 和 then都是在阶段转化时才调用。所谓的阶段转化,就是刚开始走当前栈,在当前栈转到timers的时候,清空微任务。
事件循环的顺序,决定js代码的执行顺序。进入整体代码(宏任务)后,开始第一次循环。接着执行所有的微任务。然后再次从宏任务开始,找到其中一个任务队列执行完毕,再执行所有的微任务。
Node.js的Event Loop
- V8引擎解析JavaScript脚本。
- 解析后的代码,调用Node API。
- libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户。
先说到这里吧,有欠缺的后续再补充。
