

Get Started 相当于是入门指南。本来我是准备直接从 API 入手,先学高级 API,然后慢慢向底层学习的。不过,因为要安装 TensorFlow 看到了 Get Started,感觉可以获得一些总体上的感受,所以就放下高级 API 的学习,先看一下这个文档。
程序栈
Get Started 前面写了要做的准备工作,就是安装 TensorFlow 和 pandas,然后就是 clone 样例代码,运行样例。这样就可以知道我的工作环境是可以使用的。不过,因为我之前已经尝试过一些简单的模型了,所以这睦步骤直接略过了。不过,原来我是使用 conda 来安装 TensorFlow 的,现在换成了使用 pip 来安装,这样就可以安装到 1.6 版,而不是 conda 的 1。5 版。于是,就来到了这个部分:程序栈。
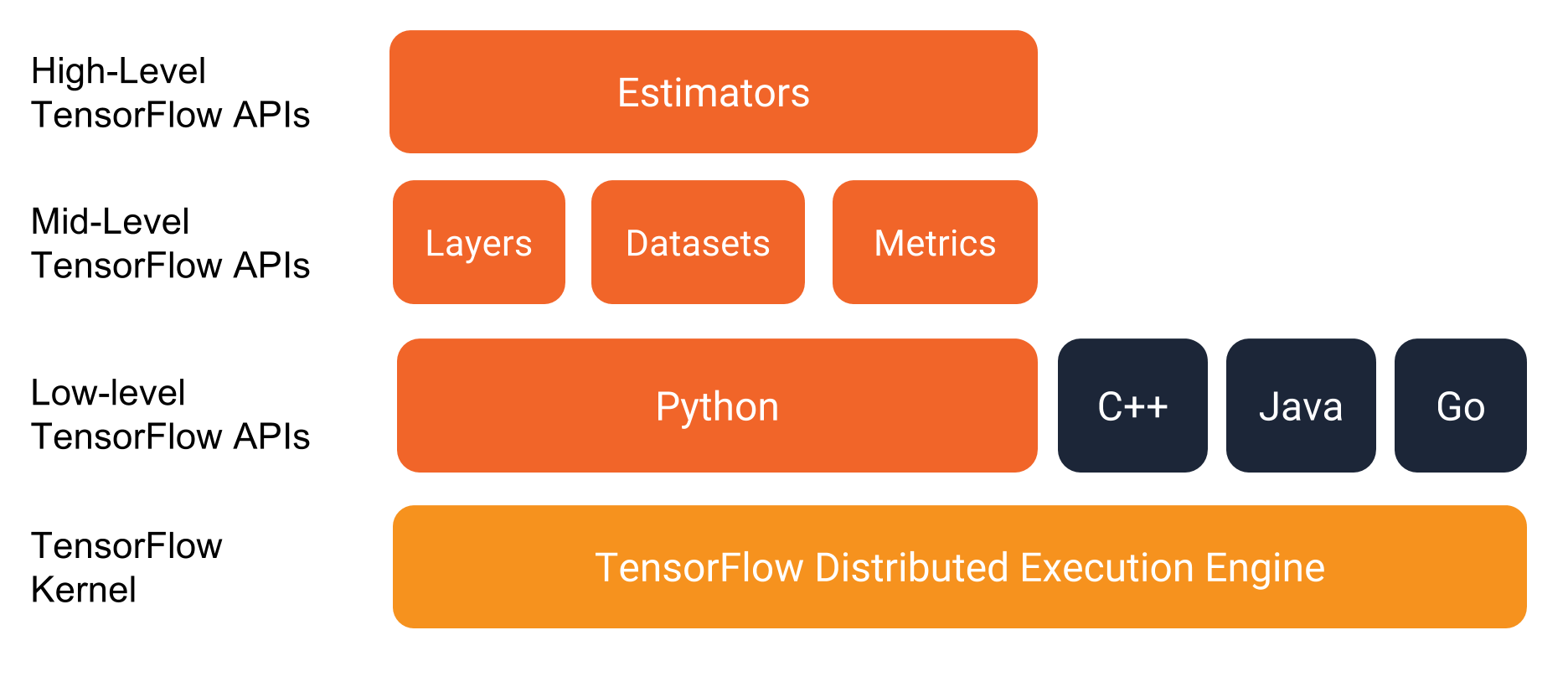
不知道上面这个图能不能显示,如果不能,只好去原站去看了。在这个图里,TensorFlow 的 API 被分成了四级:
- 最上层的高级 API,全长 Estimator 来封装了模型、训练和预测
- 中间级的 Layers,Datasets 和 Metrics,应该是在一个稍微低一点的层级来构建一个网络模型
- 再下面是低级 API,这里并没有给出细节,我想应该就是
tf.nn之类的模块了 - 最下面就是 TensorFlow 的计算引擎了
TensorFlow 推荐使用 Estimator 来构建模型,使用 Datasets 来管理输入数据。从直接使用的角度来看,这个方式很不错。不过如果是研究型的开发,可能这个方法不是很好。
Iris 分类器
Iris 是一种什么花,这个数据集在 scikit-learn 里很常用,可能是因为特征很明显,所以使用传统的分类器,其实分类效果也不错的。iris 数据包含 4 个特征(feature),一个整数的 label。构造的深度网络也很简单,只有两个全连接层,输出转换成了 1-hot 的,也就是把 0 对应到 [1, 0, 0]。
Estimator 概览
Estimator 是 TensorFlow 的高阶 API,一个 Estimator 代表了一个完整的模型,包含了初始化、日志、wkdh/恢复模型以及其它的一些细节。使用 Estimator 就可以免去关心这些细节,从而专注在构造模型上。
实现一个 Estimator,只需要创建一个继承自 tf.estimator.Estimator 的类,然后实现对应的接口就可以了。TensorFlow 也给出了一些已经实现好的 Esitmator,比如线性分类器、DNN 分类器之类的。这些预先构造好的模型,主要是为了了解 TensorFlow,入门的时候用的。
iris 分类器,正是使用了 DNN 分类器来实现分类的。这个主要是做为入门和演示。比起大型复杂的 CNN、LSTM 等模型,这个简单的分类器显然是不够用的。
使用 Estimator 的方法分四步:
- 创建输入函数
- 定义模型
- 创建 Estimator
- 运行 Estimator
创建输入函数
这个部分我感觉还有点用,因为输入函数无论是对于预定义的模型还是自己定义的模型都是一样的。一个输入函数就是要返回输入数据。一组输入数据保存在一个 tf.data.Dataset 对象里。
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
看代码,这种组织方式和我之前的想法有些不同。之前我都是把一个 label 对应的所有数据组织在一起,以保证一组对对象数据的对齐。而这里一个 feature 的数据被放在一起,这就需要把数据拆分开。只是我很好奇如果是图像,这个怎么传入呢?还有,label 好像并没有转换成 1-hot 的模式,而是直接使用的 int 式的 label。不过,这个输入函数并没有使用 Dataset API。
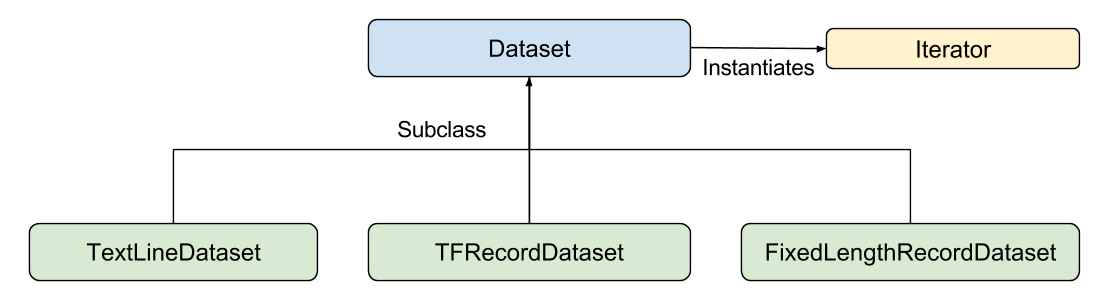
TensorFlow 提供了三种 Dataset:
- TestLineDataset
- TFRecordDataset
- FixedLengthRecordDataset
这里,除了 TFRecord 还是知道是一种什么样子的函数格式,另外两个都很明确了。Dataset API 提供了创建数据集,变换数据的操作,还有一个迭代器,可能可以用来实现 mini-batch。
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
return dataset.shuffle(1000).repeat().batch(batch_size)
看了这一段,看来刚才的理解并不对。上一个input_evaluation_set函数应该是返回数据集。不过,如果转换是基于这个格式,那我也得重新组织自己的数据。从 API 上看,Dataset API 可以在数据集上进行操作,比如 shuffle 和 batch。
下一步是要把 feature 映射到一个容易计算的空间,这里又需要用到 tf.feature_column 这个模型。不过,例子中的 feature column 不是很理解有什么特别的用处。
创建好 feature column,就可以创建 Estimator 了
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
好像很容易。然后就可以训练了:
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
然后评估训练结果:
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
嗯,很好,都是 one function call。这样我之前使用 CIFAR10 那个模型搞出来的 scafold 就没什么用了……
最后,来试试初阶的预测效果:
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
batch_size=args.batch_size))
这样,Get Started 就看完了。不过,只是感觉 Estimator 在使用的时候很简单,但这里面,input function 是怎么回事,怎么创建复杂的 Dataset,feature column 又是怎么回事,都不是很理解。
