

使用python的过程中,或多或少都会接触一些字符编码的问题,网上提到比较多的是python2中会有各种奇怪的编码问题,很多人都会说换成python3之后就没有编码的烦恼了,但事实上不是这样的。只能说python2因为自身设计问题产生了更多编码的问题,不能说换用python3之后就能彻底摆脱编码烦恼了。既然因为历史原因,产生了这么多种编码,人们使用过程中也不能保持一致,那么编码问题将会一直存在下去。要想不被编码问题困扰,最好的方法就是彻底了解其背后的机制。
虽然编码问题网上已经有了大量文章,但是没有一篇文章能把所有的问题涵盖,所以我写了这个系列。我看了网上非常多关于字符编码的博客和回答,结合自己的使用,尽可能全地总结平时可能遇到的编码问题。有些普遍的问题很多博客都说的很清楚了我就贴上链接再简单叙述一下了。
这个系列分为以下几个部分
- 编码问题的起源(文1)
- 常见字符编码(文1)
- 文件保存与打开中的编码问题(文1)
- python3中的编码与解码原理(文2)
- python3中的报错或乱码(文2)
- 与文件网页交互时的报错或乱码(文3)
- python2中的奇特编码问题(文4)
本文包括前三个部分
- 编码问题的起源
- 常见字符编码
- 文件保存与打开中的编码问题
编码的起源
几乎每一篇讲编码的文章都会说一遍编码的起源,详细的在这里就不多说了,可以参考下面链接
总结起来就是
- 计算机只能计算数字,为了表示字符,使用二进制数来对应字符进行存储,这种对应即所谓的编码
- 最初只有ASCII编码,只包含英文字母和一些符号共128个
- 为了能用计算机表示中文,中国人制定了GB2312编码。同时各个国家都为自己的语言制定了一套编码
- 因为每个国家制定的编码无法兼容(比如在计算机中相同的二进制数在各个国家的编码中表示的字符不一样,从而产生乱码),所以最后统一出了一套Unicode标准
- 而Unicode比较占空间,于是产生了“可变长编码”的UTF-8编码,这时当前最通用的编码
常见编码
这里介绍一下我们平常会经常见到的编码,了解了这些常见编码,在遇到时就大概知道哪些编码是做什么的,比如下面文本编辑器sublime中reopen可以使用的编码表
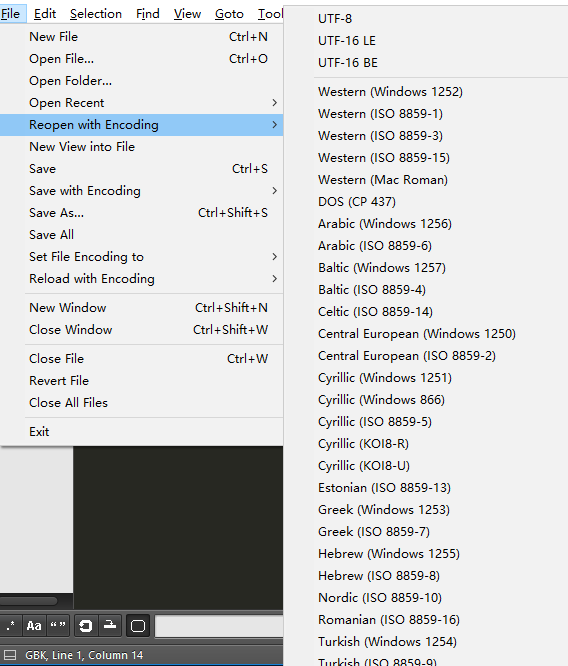
1.ASCII编码
用8个比特(一个字节),即8位的二进制数来表示一些符号。其中包含了26个英文字母大小写字母、0-9数字,以及键盘上能看到的!@#$%^&*()_+{}|<>?等符号。因为8位之首一直是0,所以一共可以表示128个。
这是最初产生的编码,所以之后的所有编码几乎都兼容这种
2.EASCII、ISO/8859-1、Latin-1、windows 1252
EASCII是ASCII编码的扩展,将8个比特数值全部填满,可以表示256个数,加入了一些公式符号、希腊字母等。不过EASCII并不表示某一种编码方式,有很多种不同的扩充方式。ISO/8859-1是其中一种,又名Latin-1。windows 1252是windows对应设计的一种。
3.GBK、GB2312
为了表示中文字符,中国人最初指定了GB2312,可以表示绝大多数中文字符,但是仍有少部分不能表示。之后又扩充产生了完整表示中文字符的GBK编码。GBK使用两个字节(16位二进制数)来表示字符。
在windows操作系统下,我们经常看到GBK这种编码,很多软件都默认用这个编码来保存和读取文件。比如记事本默认使用ANSI保存文件,常常就是使用GBK保存的文件。(ANSI后面会具体讲)
4.Unicode
这是国际组织制定的全球统一编码,可以表示任意字符,通常占用两个字节。其实Unicode只是将每个字符对应一个数字使字符得到唯一标示,它没有真正用于计算机存储,真正根据Unicode设计用于存储的是下面的UTF系列编码。
5.UTF-8
UTF-8可以说是当前最推崇的一种编码方式,可以表示任意字符,同时它一种“可变长”的编码,即表示不同字符的字节数量是不相同的。比如英文就延续ASCII使用一个字节,中文是3个字节,更不常用的字符可能是4-6个字节。
经常和UTF-8一起提到的还有
- UTF-16
- UTF-16 LE
- UTF-16 BE
- 带 BOM 的 UTF-8
- 无 BOM 的 UTF-8
这里只需要知道
- UTF-8和UTF-16都是Unicode的一种实现方式
- UTF-16是2个字节(或少部分4字节)的,因此英文使用的是2字节。我们通常说UTF-8可变长度在存储英文文件时比Unicode更省空间,应该说的是比UTF-16省空间。
- UTF-16的LE和BE的区别其实只是一些地方的字节顺序不同,理解成两种有细微差别的编码方式即可
- 带BOM可以理解成保存时在最前面加一个标志,让软件读取文件时知道这个文件是用什么进行的编码,然后用相应方法解码
这部分没那么重要,而且有点乱,更详细的内容见下面这些链接
- 有没有BOM的更多差别可以看知乎的这个回答还有这个回答
- 一篇比较完整阐述的文章
6.ANSI
这是windows记事本中特有的,记事本保存文本文件时默认使用的是ANSI,其看下面保存时的界面,可以有4种选择
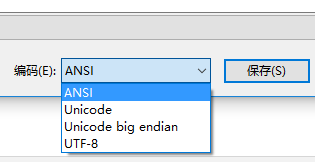
默认使用ANSI,但其实是使用GBK保存的。经常默认使用GBK而不是utf-8保存打开文件应该是windows被诟病的一个点(相比于mac和linux)。有的人就会问为什么windows这么反人类,不用兼容性好的utf-8,但是这有点冤枉windows了。现在的windows其实使用的就是unicode,但是很多软件用的不是unicode,为了兼容那些软件,windows设下这样的规定:设置一个默认编码,遇到一个字符串如果使用unicode就用unicode,不使用的就用这个默认语言来解释。而这个默认语言在不同windows语言版本中是不一样的,在简体中文版是GBK,在日语的windows系统中就是支持日语的编码。ANSI就是这个默认编码,因此在这里使用ANSI就相当于使用GBK。
关于记事本还要说明以下几点
- 其中UTF-8其实是带BOM的,我们正常使用时最好使用不带BOM的UTF-8。当我们在这里选择使用UTF-8保存时,会自动在整个文档前面加一个标志性的东西即BOM,之后再读取时就可以知道这个是用UTF-8编码的,从而使用UTF-8来解码。带BOM的UTF-8是windows为了读取准确而设计的,兼容性不是十分好,所以不建议使用。
- 如果使用ANSI保存,没有BOM的标示,在打开文件时,记事本也无法判断文件是用什么编码的,只能通过那些字节进行猜测,所以有时会出现猜错的情况。比如在记事本中输入“联通”两个字,保存关闭,之后再打开,会发现乱码了。是因为“联通”二字的编码比较像UTF-8的编码,于是使用UTF-8来解释GBK编码的字符,肯定会出现乱码。如果文件“联通”后面还有很多字,关闭打开就可以正常显示,因为打开时可以参照的文字变多了,就可以正确识别是用GBK编码的了。记事本的更多bug见 这个回答
本节这些编码的更详细解释见这个回答
上面我们介绍了各种编码如何演变以及常见编码,之后几个部分就来看一下哪些情况下会遇到乱码问题。
文件保存与打开中的编码问题
本节分为如下部分
- 明确存储原理
- txt文件不同编码方式保存与打开试验
- sublime中关于编码的选项解释
- 如何知道一个文件的编码
- R文件乱码问题
- python脚本开头提示
明确存储原理
首先要明确,我们人眼看到的英文字母、文字等计算机是无法识别的,也无法直接处理和储存这样的内容,所以需要将这些字符编码成计算机可以识别的二进制数进行存储。
比如在记事本中输入A中,使用UTF-8保存文件,记事本会将这些字符按照UTF-8的规则编码成01000001 11100100 10111000 10101101这样的二进制数,将这些数存到硬盘中。之后某一天我们想看文件中的内容,用记事本打开,它会将这一串二进制数又解码为我们能看懂的字符串。因为在UTF-8下二进制编码和字符是一一对应的,所以存储和打开时都使用UTF-8就不会出现乱码。
而如果我们读取时使用EASCII,它的每个字符对应一个字节,即上面存储的4个字节会被解码成4个字符,显然不是我们最开始保存的A中了,这种不一致就是乱码。这段二进制数放在EASCII中可能得到的字符我们还认得,而在有的编码方式中可能就对应着非常生僻的符号,全篇解码出来都是这种看不懂的东西,这就是我们脑中最直观的所谓乱码了。
还可能你使用的解码方式中没有这段二进制数据对应的字符,此时就会报错。因为一种编码方式占用一些字节数,这些字节可以表示的字符数量超过了当前需要表示的字符数量,就会有一些二进制数不对应任何字符,此时要将这些二进制数转成字符而报错。
txt文件不同编码方式保存与打开试验
首先推荐写代码时不要使用windows自带的记事本,它对写代码的各种支持都不好。可以选择自己称手的文本编辑器,我用的是sublime text3,它一个优点是打开文件非常快。这个文本编辑器支持以各种编码打开或保存文件,所以这里拿这个编辑器对编码问题进行测试。
为了更直观地体会乱码,这里使用windows自带的记事本和文本编辑器sublime text进行对比。
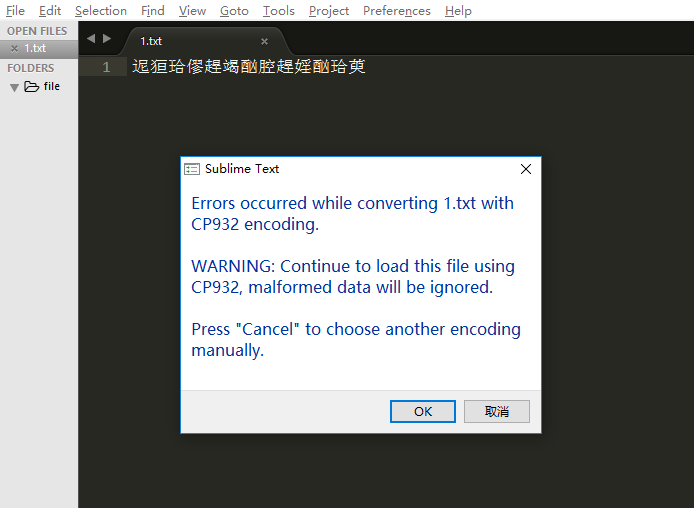
实验方法:用记事本写下一段中文保存,再用sublime text打开,看结果。这里输入写下一段话很长的话再长一点
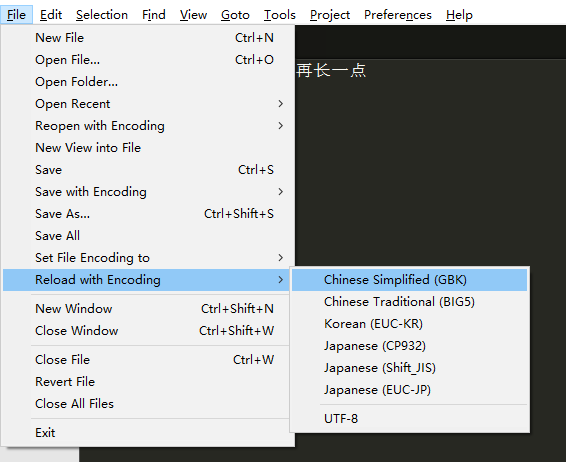
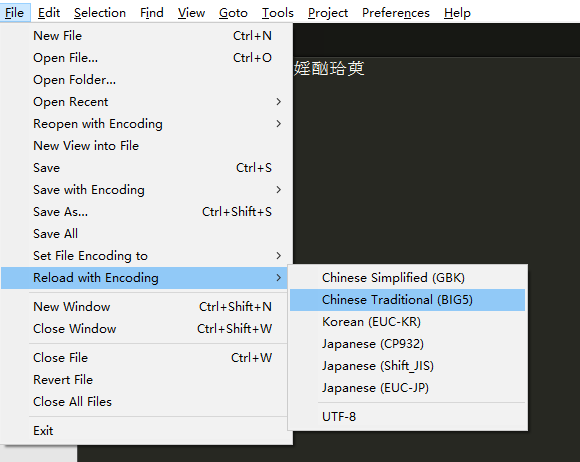
为了看使用不同编码方式打开结果,用sublime打开后可以点击 file-reload with encoding(没有这个选项的看下一部分)来更换编码方式,选择GBK(中文简体)就正常显示,选择BIG5(中文繁体)发现文本乱码了,选择CP932(日文)报错了。
如下图
sublime中关于编码的选项解释
1.选项说明。sublime打开一个文件使用什么编码方式也是靠猜,而保存一个文件默认方式是UTF-8。它本身是不支持GBK解码的,刚下载sublime时应该是没有reload with encoding和set file encoding to的,只有reopen with encoding和save with encoding。reopen with encoding让我们可以在打开文件时指定用什么方式解码,但是这里没有GBK,要想解码GBK就只好安装ConvertToUTF8这个插件(如何安装百度一下),它提供了reload with encoding选项,也是表示用什么编码解码文件,这里提供了简体中文(GBK)、繁体中文、日文等编码。reload和reopen的功能其实是一样的,只是支持的编码方式不一样。
安装好插件后,大多数时候用记事本编辑的中文,用sublime直接打开都不会乱码,是因为它根据存储的二进制数可以猜出要用GBK来打开。但是有的时候还是不行,用记事本编辑的什么,在sublime中打开就会乱码,因为它识别不出来是GBK,使用了UTF-8来解码,这时就要人为去选择reload with encoding中的GBK,就可以正常显示了。
2.在使用过程中发现一个奇怪的现象:比如打开一个中文文件,默认正常显示,这是选择reload with encoding中的BIG5和CP932等都会出现乱码,这是正常的,而选择UTF-8没反应,正常不也应该乱码吗?此时如果用reopen with encoding中的所有选项都没反应,然而事实上都应该乱码才对。
摸索了很久发现一个规律,就是如果打开时默认使用的是reload with encoding中的编码,想切换成UTF-8或者reopen with encoding中的编码,需要这样做
- 先点击reload中的UTF-8,再去点reopen中的UTF-8才是用UTF-8来解码
- 也就是说当前使用reload时想要切换到reopen需要先点reload中的UTF-8
- 而如果当前使用reopen的编码时,可以随意点reopen和reload中的编码都可以
- reload中的UTF-8无论何时都不起作用,它只是reload到reopen的一座桥梁
知道这点之后我们就可以自由地对一些文本使用各种各样的编码方式进行解码了,会发现即使是乱码很多种编码的结果都是一样的,说明这些是相似的编码方式。
3.如何改变文件编码。比如用记事本保存默认用的GBK编码,可以在sublime中打开将文件编码方式转变成UTF-8。sublime自带的选项是save with encoding,这里也不支持将文件转变成GBK进行保存,于是ConvertToUTF8这个插件又增加了一个选项set file encoding to可以保存为GBK,这个设置完要再点一下保存。
这里要说明一点,比如当前显示中文字符,用的是GBK,你想换成UTF-8编码,它的内部原理是这样的
- 当前存储时使用的是GBK二进制编码,每个字符对应两个字节,计算机只能对这些字节进行操作
- 点击转换成UTF-8的过程是:识别GBK中的字节(二进制数),找到其对应的字符,再找到字符对应的UTF-8二进制字节,用新字节代替旧字节
- 如果这个文件实际上是用GBK编的码会正常显示中文,而你用BIG5去打开文件(解码)得到一堆乱码,此时再save转化为UTF-8,那么它去查询和替换的会是乱码字符的UTF-8二进制数,所以相当于你保存下了这些乱码而把真正的东西丢掉了(虽然也可以往回推导找到原始文本)
如何知道一个文件的编码
对于一个未知的文件,我们不能准确知道它的正确解码方式,毕竟软件也都是靠猜,因为很多种解码方式都可以得到一个结果,有些结果在我们眼中叫做乱码,但在计算机眼中都是一样的,所以它无法辨别人眼到底能识别的是哪种结果。
我们能知道的只有
- 当前软件使用了什么方式进行解码
- 这种方式解码结果是不是我们想要的
- 这个文件最有可能是哪几种编码方式,去试
首先我们可以看出当前软件使用什么方式进行的解码
- 在记事本中,点击另存为,此时默认是什么编码就说明它是使用的这个方法解的码
- 在sublime中进行这样的配置,在下方显示解码方式,如图
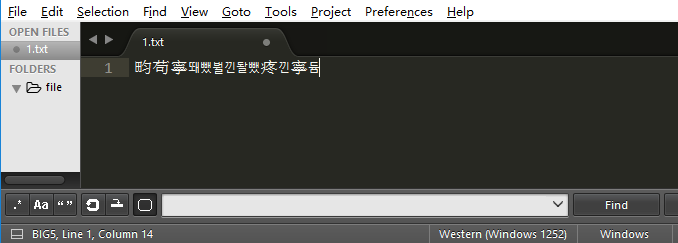
其中左边一个,右边一个。左边对应的是插件里的编码,右边对应的是sublime自带的。看你打开文件时使用了什么编码,如果是用GBK,那么右边显示的编码就完全没用不用看,如果是用reopen中的编码,则左边的不用看。
比如一个中文文件,我们使用UTF-8解码,发现正常显示中文了,说明我们的解码方式正确,万事大吉。如果乱码了,说明文件不是用UTF-8编码的,这时是无法得知确切编码的,只能猜。这个文件是一个中国同学发给我的,他可能用的是GBK,于是去试GBK。不行的话可能再想这个文件最初是一个日本人创建的辗转到我这里来,于是再试日本的编码。如果都不行就没辙了,或者一个个试下来。
R文件乱码问题
在weindows下,R语言中无论是R还是rstudio,如果有中文注释都是使用GBK进行保存。但是最好将打开和保存文件设置为默认UTF-8,这在rstudio中是可以设置的。R里面应该是不能设置的。
如果要和别人一起完成工作,他的电脑是mac,发给你的R文件都是utf-8编码的,你打开的话中文(比如注释)就会乱码,所以最好设置默认UTF-8。但是我们在rstudio设置之后,如果去打开以前的R文件,其中的中文也会乱码;那些没有设置过的windows小伙伴发来的.R文件也会出现中文乱码,但是这不是不换UTF-8的理由。如果你要和mac系统的人合作,同时要和日本人合作,和韩国人合作,他们默认保存的是UTF-8、日本设计的编码、韩国设计的编码,而你使用的是中国设计的编码GBK,遇到编码不兼容问题,最后商讨的结果一定是大家都换UTF-8来统一,所以早换晚换都要换,两个人编码不一样一定是非UTF-8的妥协。早一点换会让你电脑中GBK的文件少一些,之后修改编码方便一些。
在rstudio中修改默认编码的方式:tool-global options-code-saving-change选择UTF-8
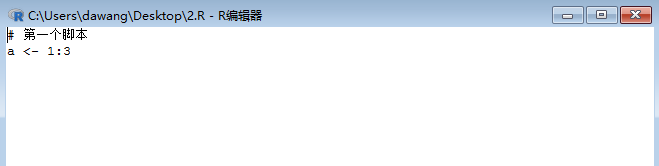
设置完我们用R和rstudio进行试验
在R中编辑脚本保存后用rstudio打开,如下图
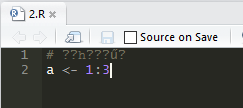
在rstudio中选择reopen with encoding,选择GB2312就可以正常显示中文了。如果用R打开rstudio的UTF-8应该是没有方法进行转化的,所以还是全用rstudio就好。
在rstudio中也可以选择save with encoding改变文件的编码方式。
python脚本开头提示
我们经常会看到一些python脚本文件(.py文件)最开始两行总是这样的
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
其中第一行是在Linux/OS X中声明这是一个可执行的python程序,在windows下无用,可以忽略。
第二行是告诉Python解释器,按照UTF-8编码读取脚本代码
但是在python3中其实第二条也没有必要了,参考这个回答。
专栏信息
专栏主页:python编程
专栏目录:目录
版本说明:软件及包版本说明
