聚类算法简介
kmeans算法是无监督学习算法,它的主要功能就是把相似的类别规到一类中,虽然它和knn算法都是以k开头,但是knn却是一种监督学习算法.
那我们怎样去区分样本间的相似性呢?其实计算相似性的方式有很多,其中最常用的是欧示距离。
聚类算法的实现原理
假设我们有个样本点,这
个样本点有
个分类,首先我们随机选取
个样本点作为质心,
- 我们遍历
个样本点
,计算
- 当我们通过(1)分好所有类之后,我们重新选择质心。再重复(1)的过程,直到算法收敛。
由于kmeans算法比较简单,在这里不详细进行介绍,直接给出算法的实现过程和结果。
算法python实现
# coding=gbk
'''
Created on 2018年2月28日
@author: sundarchen
'''
from numpy import *
from mpmath.tests.test_elliptic import zero
import matplotlib.pyplot as plt
from _ast import If
'''
k-means分类模型
@param dataSet: n*n维数组
@param kValue: 分类类型
'''
def kmeans(dataSet, kValue):
'''构建n*(n + 1)维数组,用于存放离cluster的距离'''
currentClusters = randomSelectCluster(dataSet, kValue)
'''用于记录使用kmeans分后类的结果'''
kmeansResult = {}
totalRows = dataSet.shape[0]
while True:
'''重置分类后结果,后面会重新计算'''
kmeansResult.clear()
'''重新计算所有样本到cluster的距离'''
for currentRow in range(totalRows):
minCluster = -1
minDistance = 100000000
currentRowData = dataSet[currentRow:(currentRow + 1)]
'''计算当前的行与所有的cluster的距离,找出最小的距离'''
for clusterIndex in range(len(currentClusters)):
'''计算距离'''
innerDistance = calcuateDistance(currentRowData, currentClusters[clusterIndex])
'''记录最小距离'''
if minDistance > innerDistance:
minCluster = clusterIndex
minDistance = innerDistance
'''找出当前的行与哪个cluster的距离最小后,就把当前的行分配到相应的cluster下面进行分类'''
print("minCluster ====== " + str(minCluster))
if minCluster in kmeansResult:
resultArray = kmeansResult[minCluster]
resultArray.append(currentRowData)
else:
resultArray = []
resultArray.append(currentRowData)
kmeansResult[minCluster] = resultArray
currentRow = 0
innerClusterArray = mat(zeros((kValue, 2)))
'''重新计算所有集合的cluster点'''
for key in kmeansResult:
resultArray = kmeansResult[key]
'''重新计算中点,即集合中所有的点与点之间的距离'''
minClusterValue = 0
minClusterIndex = -1
for outerIndex in range(len(resultArray)):
innterMinClusterValue = 0
for innerIndex in range(len(resultArray)):
innterMinClusterValue += calcuateDistance(resultArray[outerIndex], resultArray[innerIndex])
if innterMinClusterValue < minClusterValue or minClusterValue == 0:
minClusterIndex = outerIndex
minClusterValue = innterMinClusterValue;
'''存放cluster点'''
innerClusterArray[currentRow, :] = resultArray[minClusterIndex]
currentRow += 1
'''算法收敛'''
if (currentClusters == innerClusterArray).all():
break
'''重新找到的cluster点'''
currentClusters = innerClusterArray
return currentClusters, kmeansResult
'''
随机选择k个中心点
'''
def randomSelectCluster(dataSet, kValue):
indexCache = []
indexValue = 0
centerSamples = mat(zeros((kValue, dataSet.shape[1])))
totalRows = dataSet.shape[0]
while indexValue < kValue:
index = random.randint(0, totalRows)
if index in indexCache:
continue
indexCache.append(index)
rowData = dataSet[index, :]
centerSamples[indexValue,:] = rowData
indexValue += 1
return centerSamples
'''
计算样本和中心点的距离
'''
def calcuateDistance(rowData, clusterData):
return math.sqrt((rowData - clusterData) * (rowData - clusterData).T)
'''
显示Kmeans结果集
'''
def showKmeans(currentClusters, kmeansResult):
x = []
y = []
marker = ["a", "b", "c", "d", "e"]
'''中心点'''
for kmeanRow in currentClusters:
x.append(kmeanRow[0, 0])
y.append(kmeanRow[0, 1])
plt.scatter(x,y, color='r', label=marker[0])
'''分类点'''
typeColor = ["m", "c", "b", "k"]
for kmeanRow in kmeansResult:
x1 = []
y1 = []
kmeansResultRow = kmeansResult[kmeanRow]
for innerRow in kmeansResultRow:
isFinded = False
'''判断当前的点必须为非中心点'''
for kmeanRow2 in currentClusters:
if kmeanRow2[0, 0] == innerRow[0, 0] and kmeanRow2[0, 1] == innerRow[0, 1]:
isFinded = True
'''上面己经画出了中心点,这里只要画非中心点就可以'''
if not isFinded:
x1.append(innerRow[0, 0])
y1.append(innerRow[0, 1])
plt.scatter(x1, y1, color=typeColor[kmeanRow], label=marker[kmeanRow + 1])
plt.show()
以下给出测试代码
# coding=gbk
import random
import kmeans2
from numpy import *
def createDataSet():
result = []
totalRows = 100
xAdder = 15
yAdder = 10
centerPoints = [[5, 10], [20, 10], [5, 0], [15, 0]]
for row in range(totalRows):
randomIndex = random.randint(0, len(centerPoints))
randomPoints = centerPoints[randomIndex]
randomX = random.randint(0, xAdder - 3)
randomY = random.randint(0, yAdder - 3)
result.append([randomPoints[0] + randomX, randomPoints[1] + randomY])
return result
dataSet = mat(createDataSet())
currentClusters, kmeansResult = kmeans2.kmeans(dataSet, 4)
'''
显示kmeans数据
'''
kmeans2.showKmeans(currentClusters, kmeansResult)
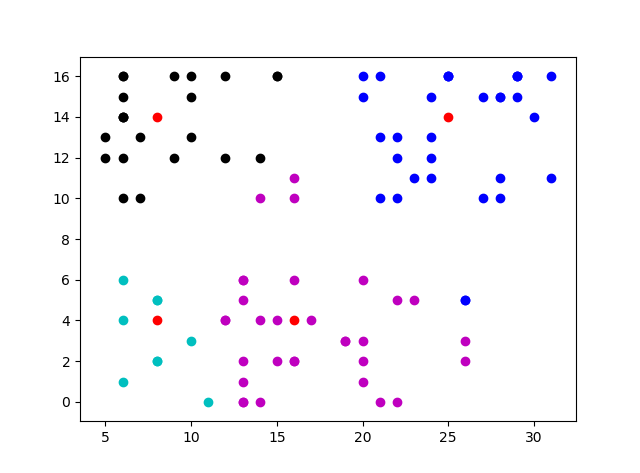
运行结果