

基于spark 2.2.0
Structured Streaming 编程指南
容错语义
提供 end-to-end exactly-once semantics (端到端的完全一次性语义)是 Structured Streaming 设计背后的关键目标之一
Datasets 和 DataFrames
自从 Spark 2.0 , DataFrame 和 Datasets 可以表示 static (静态), bounded data(有界数据),以及 streaming , unbounded data (无界数据)
Input Sources
在 Spark 2.0 中,有一些内置的 sources 。
- File source
以文件流的形式读取目录中写入的文件。支持的文件格式为 text , csv , json , parquet 。文件必须以 atomically (原子方式)放置在给定的目录中 - Kafka source
来自 Kafka 的 Poll 数据。它与 Kafka broker 的 0.10.0 或者更高的版本兼容。 - Socket source (for testing)
从一个 socket 连接中读取 UTF8 文本数据。 监听服务器 socket位于 driver 。只能用于测试,因为它不提供 端到端的容错保证。
Window Operations on Event Time
每个事件有一个event-time,假设运行Word count,计算10分钟内的window Word count,每5分钟更新一次,延迟超过10分钟才到达的数据不再重新接收
Dataset<Row> words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset<Row> windowedCounts = words
//watermarking:超过该值到达的数据不再更新
.withWatermark("timestamp", "10 minutes")
.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word"))
.count();
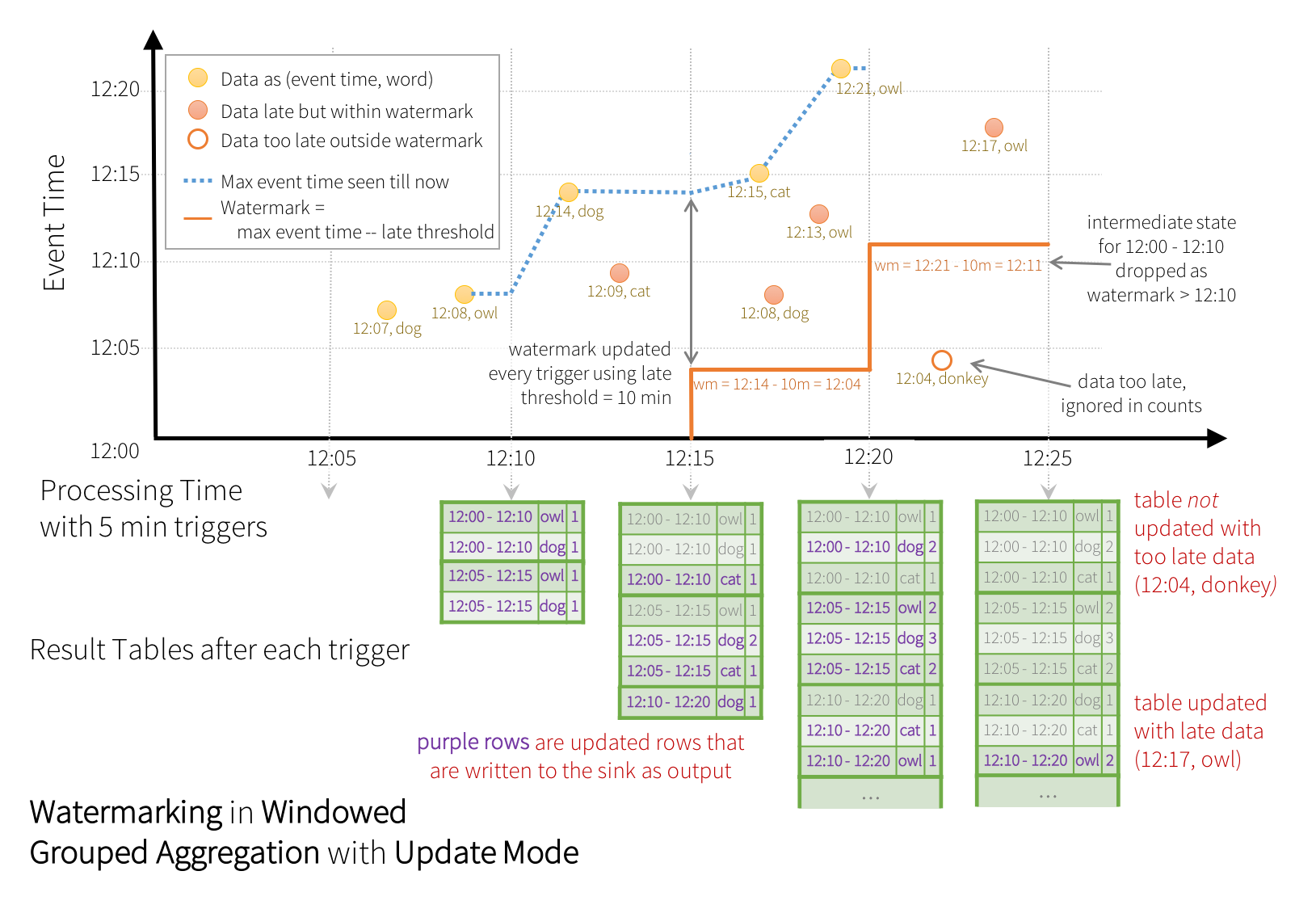
在 non-streaming Dataset (非流数据集)上使用 withWatermark 是不可行的
Streaming 去重
event中有unique identifier (唯一标识符),可用于删除重复记录
Dataset<Row> streamingDf = spark.readStream. ...; // columns: guid, eventTime, ...
// 按照唯一标识符对所有数据去重
streamingDf.dropDuplicates("guid");
// 以唯一标识符删除10s内的重复数据
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime");
有状态操作
自从 Spark 2.2 ,可以使用 mapGroupsWithState 操作和更强大的操作 flatMapGroupsWithState 来完成,这两个操作都允许在分组的数据集上应用用户定义的代码来更新用户定义的状态
Streaming Queries
获得窗口数据后,需要进行流计算,需指定以下一个或多个:
- output sink 的详细信息: Data format, location, etc.
- Output mode : 指定写入 output sink 的内容。
- Query name : 可选,指定用于标识的查询的唯一名称。
- Trigger interval (触发间隔): 可选,指定触发间隔。 如果未指定,则系统将在上一次处理完成后立即检查新数据的可用性。 如果由于先前的处理尚未完成而导致触发时间错误,则系统将尝试在下一个触发点触发,而不是在处理完成后立即触发。
- Checkpoint location : 对于可以保证端对端容错能力的某些 output sinks ,定系统将写入所有 checkpoint 信息的位置。 这应该是与 HDFS 兼容的容错文件系统中的目录。
Output Modes
不同类型的 streaming queries 支持不同的 output modes
| 查询类型 | 查询细分 | 支持的输出模式 | 说明 |
|---|---|---|---|
| Queries with aggregation (聚合) | Aggregation on event-time with watermark | Append, Update, Complete | Append mode使用 watermark 来删除旧聚合状态。Update mode 使用 watermark 删除旧的聚合状态。Complete mode 不会删除旧的聚合状态,因为在定义上Complete mode会保存Result Table 中的所有数据。 |
| Queries with aggregation (聚合) | Other aggregations | Complete, Update | 由于没有定义 watermark,旧的聚合状态不会删除。不支持 Append mode ,因为aggregates聚合可以更新,违反了模式语义。 |
| Queries with mapGroupsWithState | Update | ||
| Queries with flatMapGroupsWithState | Append operation mode | Append | Aggregations are allowed after flatMapGroupsWithState |
| Queries with flatMapGroupsWithState | Update operation mode | Update | Aggregations not allowed after flatMapGroupsWithState. |
| Other queries | Append, Update | 不支持 Complete mode ,因为将所有未分组数据保存在 Result Table 中是不可行的 。 |
Output Sinks
//streamingQuery对象有stop(),awaitTermination(),explain()等多个方法
val streamingQuery =writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.queryName("aggregatestable") // this query name will be the table name
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start() //call start() to actually start the execution of the query
spark.sql("select * from aggregatestable").show();
同样,不同sink支持不同的output modes
| Sink | 支持的输出模式 | 选项 | Fault-tolerant 容错 | 说明 |
|---|---|---|---|---|
| File Sink | Append | path: 必须指定输出目录的路径。 | Yes | 支持对 partitioned tables的写入。Partitioning by time may be useful. |
| Foreach Sink | Append, Update, Compelete | None | 取决于 ForeachWriter 的实现。 | |
| Console Sink | Append, Update, Complete | numRows: 每个触发器需要打印的行数(默认:20) truncate: 如果输出太长是否截断(默认: true) | No | |
| Memory Sink | Append, Complete | None | 否。但是在 Complete Mode 模式重新启动查询将重建 full table。 | Table name is the query name |
Foreach
datasetOfString.writeStream().foreach(
//writer必须是可序列化的,发送到executors执行
new ForeachWriter<String>() {
@Override
// version 是每个触发器增加的单调递增的 id
public boolean open(long partitionId, long version) {
// open connection or init
//返回fasle,则process不会被调用
}
@Override
public void process(String value) {
// write string to connection
}
@Override
//当 open 被调用时(不论是返回true/false), close 也将被调用
public void close(Throwable errorOrNull) {
// close the connection
}
});
异步监视
添加StreamingQueryListener对象,有相关任务时将收到callback
SparkSession spark = ...
spark.streams().addListener(new StreamingQueryListener() {
@Override
public void onQueryStarted(QueryStartedEvent queryStarted) {
System.out.println("Query started: " + queryStarted.id());
}
@Override
public void onQueryTerminated(QueryTerminatedEvent queryTerminated) {
System.out.println("Query terminated: " + queryTerminated.id());
}
@Override
public void onQueryProgress(QueryProgressEvent queryProgress) {
System.out.println("Query made progress: " + queryProgress.progress());
}
});
