

在过去的几个月中,我和多个企业的数据科学团队进行了多次合作,也看到越来越多的机器学习和深度学习框架被广泛应用到实际生活中。
与大数据分析和数据科学中的其他用例一样,这些团队希望在BlueData EPIC软件 平台上的Docker 容器中运行他们最喜欢的深度学习框架和工具。因此,我的一部分工作就是尝试使用这些新工具,确保在我们的平台上能够运行,并且能够帮助这些团队开发出可以解决一些问题的新的功能。
TensorFlow 是深度学习和机器学习最流行的开源框架之一。TensorFlow 最初是由 Google 研究团队开发的并致力于解决深度神经网络的机器学习研究。另外, TensorFlow 也适用于许多其他应用场景:图像识别,自由文本数据的自然语言处理以及威胁检测和监视等。
“ TensorFlow 是一个用于对一系列任务进行机器学习 的开源软件库,它是一个构建和训练神经网络来检测、解读模式和相关性的系统,它与人类学习和推理相似(但不一样)。”——维基百科
TensorFlow 可以在各种异构系统(包括 CPU 和 GPU )上对计算资源进行合理分配。与我合作过的几个数据科学团队使用GPU 来提高TensorFlow 的计算速度,但 GPU 价格昂贵,他们需要对 TensorFlow 所占用的资源进行认真的 管理。
部署TensorFlow 的注意事项
以下是部署数据科学应用程序和TensorFlow 时的一些注意事项(尤其是在企业大规模部署时更应该注意):
1. 如何对部署的复杂性进行管理,例如在 OS ,内核库和 TensorFlow 不同版本之间进行部署。
2. 如何在作业期间支持创建临时集群。
3. 如何隔离正在使用的资源并阻止同时队同一资源的访问请求。
4. 如何在共享的多租户环境中对 GPU 和 CPU 资源进行管理和分配。
BlueData EPIC软件平台 就可以解决这些问题,它能够按照数据科学团队的需要访问各种不同的大数据分析、数据科学、机器学习和深度学习工具。在一个灵活、弹性和安全的多租户架构中使用Docker 容器, BDaaS ( Big-Data-as-a-Service )软件平台可以支持大规模分布式数据科学和深度学习用例。
BlueData 的最新版本可以支持启动采用 GPU 加速的集群,并且支持 TensorFlow 在 GPU 或 Intel 架构的 CPU 上进行深度学习。数据科学家可以在 BlueData EPIC 软件平台上启动即时 TensorFlow 集群在 Docker 容器上进行深度学习。 BlueData 支持在 Intel Xeon 硬件和 Intel MKL 上运行基于 CPU 的 TensorFlow ,也支持采用 NVIDIA CUDA 库、 CUDA 扩展以及用于 Docker 容器的字符设备映射的基于 GPU 的 TensorFlow 。
BlueData EPIC 软件平台可以为 TensorFlow 提供自助服务、弹性和安全环境,无论是在本地、公共云还是在二者的混合结构中都拥有同样的界面,不管其底层架构多么不同,用户都会有相同的用户体验。
如下图所示,用户可以像用于其他大数据分析、数据科学和机器学习环境一样,能够很容易地将带有BigDL 的即时 TensorFlow 集群在 BlueData 软件平台上进行深度学习。并且,用户可以指定在 TensorFlow 运行的 Docker 容器放置在有 GPU 还是 CPU 配置的基础架构,以及在公共云还是在本地。
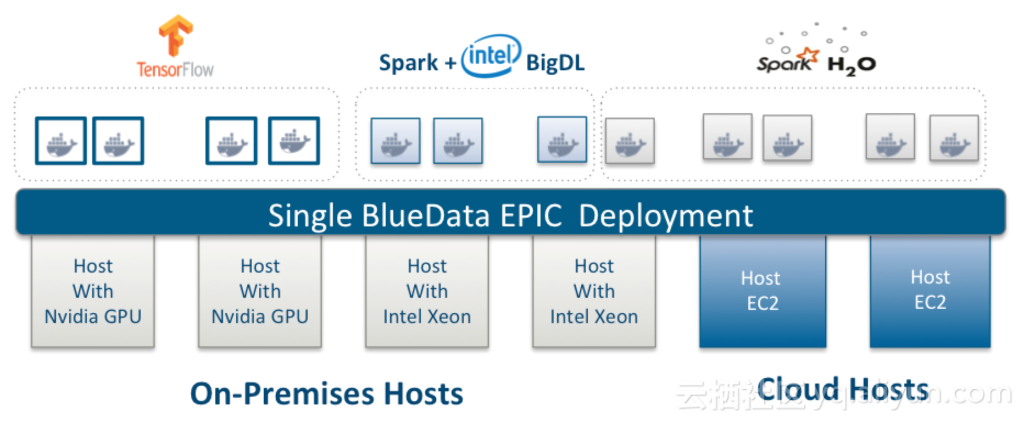
按需创建TensorFlow 集群
在BlueData EPIC 软件平台上,用户只需点击几下鼠标即可根据自己的需求创建 TensorFlow 群集。 BlueData 的最新版本引入主机标签,用户可以创建具有主机标记的基于 GPU 或 CPU 的 TensorFlow 集群,这些主机标记为特定工作负载指定所需要的硬件,如下图所示。
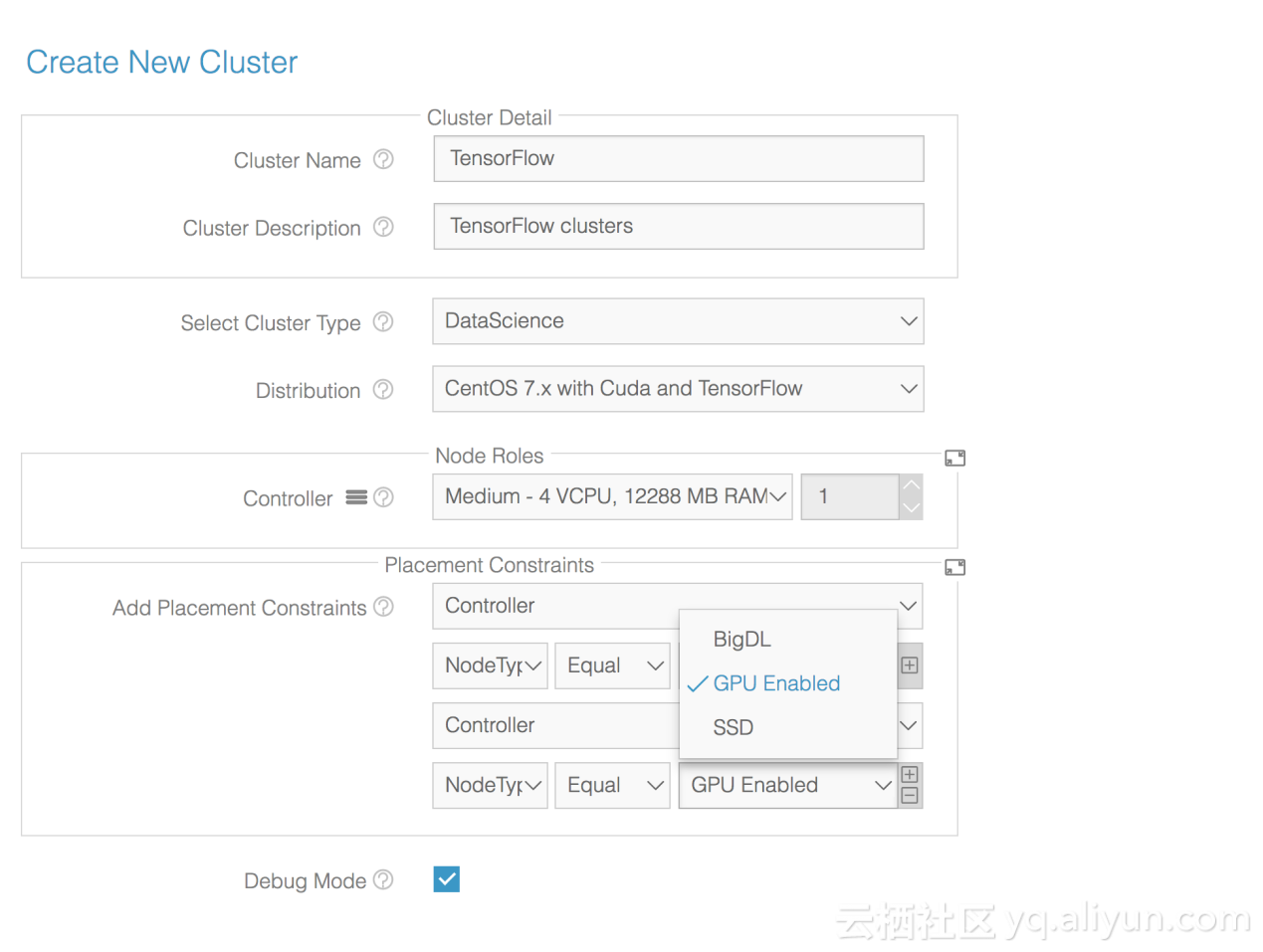
一旦创建完成,TensorFlow 集群将拥有一个或多个 Docker 容器节点,这些 Docker 容器使用 TensorFlow 软件和相应的 GPU 和 / 或 CPU 加速库进行部署。例如,基于 GPU 的 TensorFlow 群集将在 Docker 容器内具有 NVIDIA CUDA 和 CUDA 扩展;而基于 CPU 的 TensorFlow 群集则在 Docker 容器中具有 Intel MKL 和 Jupyter Notebook 扩展。
高效的GPU 资源管理
GPU 和特定的 CPU 通常不会作为 Docker 容器的独立资源。 BlueData EPIC 软件平台通过在所有主机上管理 GPU 的共享池并在群集创建期间将 GPU 所请求的数量分配给群集来处理此问题。这种排他性(或隔离性)保证了对深度学习作业的服务质量,并防止多个处理作业尝试同时访问同一资源。
对于今天的大多数企业来说,GPU 是一种需要有效利用的高端资源。当一个集群没有在使用或完成一项作业时, BlueData EPIC 软件平台可以停止该集群使用并将 GPU 分配给其他正在使用的集群。 这允许用户在不同的租户环境中创建多个集群,并且仅仅在集群需要时才使用 GPU ,而不需要删除或重新创建群集群。还有一种机制,即在作业期间创建一个群集作为暂时性集群。
提高用户生产力
一旦TensorFlow 集群创建完成,用户可以使用 AD / LDAP 控制的 SSH 启用容器并保护 Jupyter Notebook 。
为了进行验证和测试,TensorFlow 集群默认包含 Jupyter Notebook ,用例如下图所示。
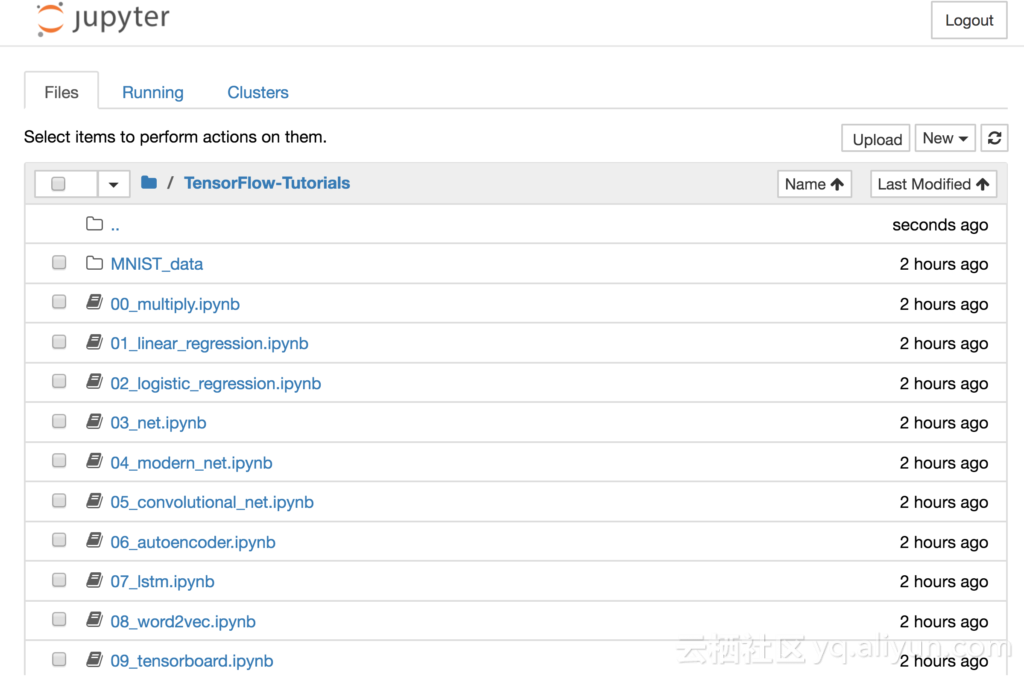
上图来自于GitHub回购。这些源码和教程可供用户使用,并可以立即投入应用中去。
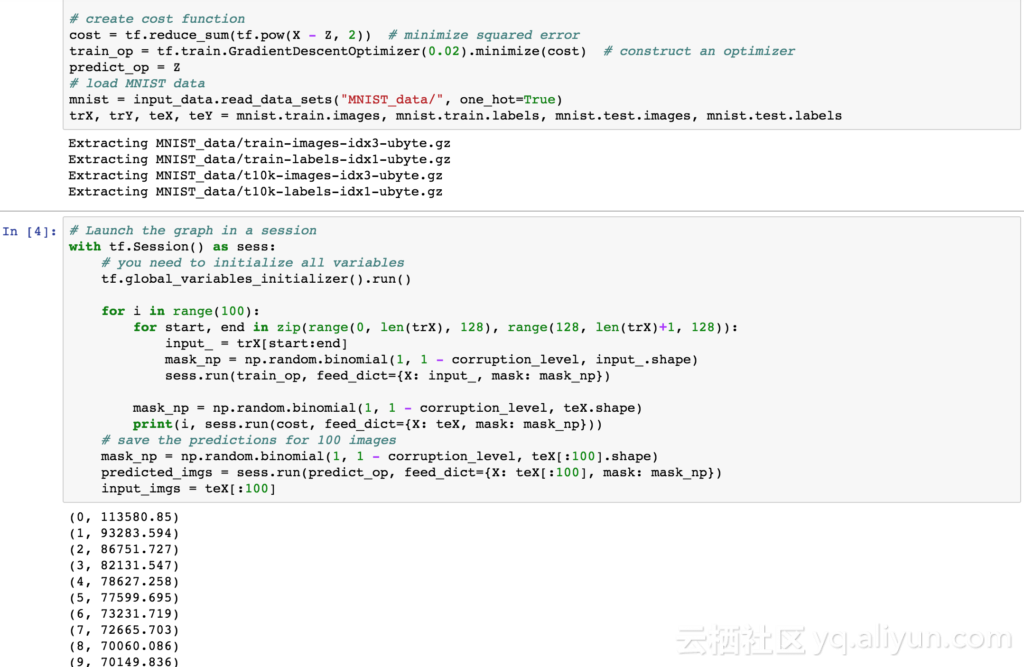
在BlueData EPIC 软件平台上使用 TensorFlow 库和图表绘制的 MNIST 数据集的输入数字图像的重建示例如下图所示。
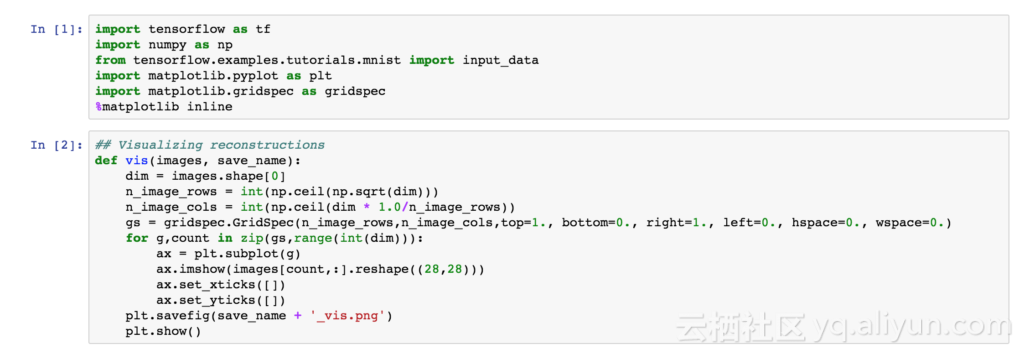
根据输入图像和模型(使用TensorFlow GradientDescentOptimizer 训练)提取数据集和模型预测如下图所示:
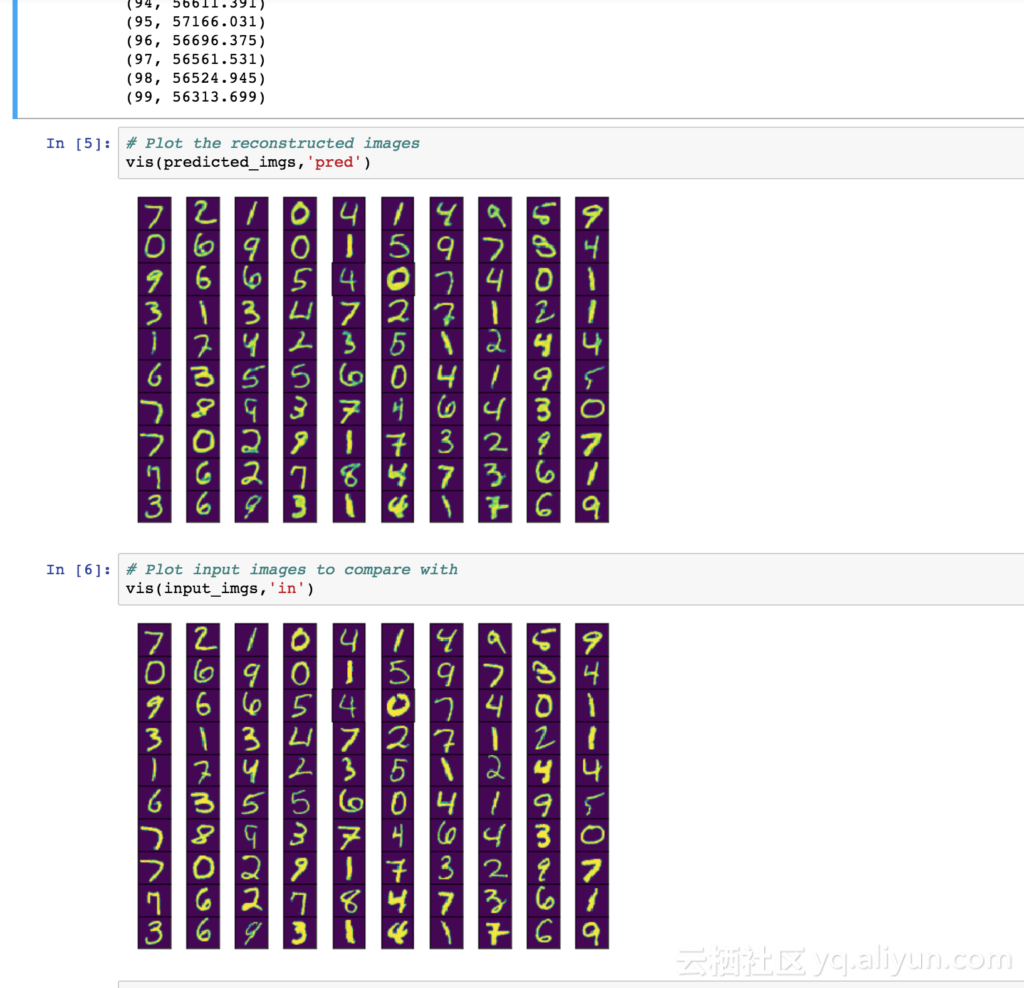
对输入图像和输出预测结果的对比如下图所示:
对运行的TensorFlow 集群更新
随着新的库和软件包不断被推出,数据科学团队的需求也在不断的变化,因此BlueData EPIC 软件平台提供了一种称为“操作脚本”的机制,该机制允许用户使用新的库和软件包对正在运行集群的所有节点进行更新。在长时间运行的交互或批处理作业中,用户还可以使用基于 Web 的 UI 或 RESTful API 将 Python 作业提交。
以上为译文。
本文由北邮@爱可可-爱生活 老师推荐, 阿里云云栖社区 组织翻译。
文章原标题《Deep Learning With TensorFlow, GPUs, and Docker Containers 》,译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看 原文 。
