信息组织和提取方法、
信息标记的三种形式

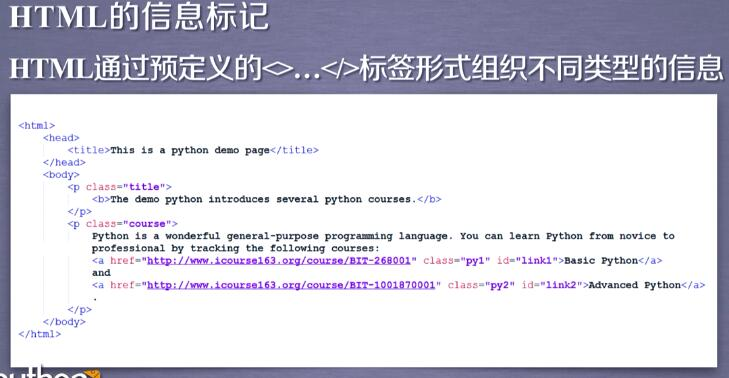
- xml



三种信息标记形式的比较
三种实例排列





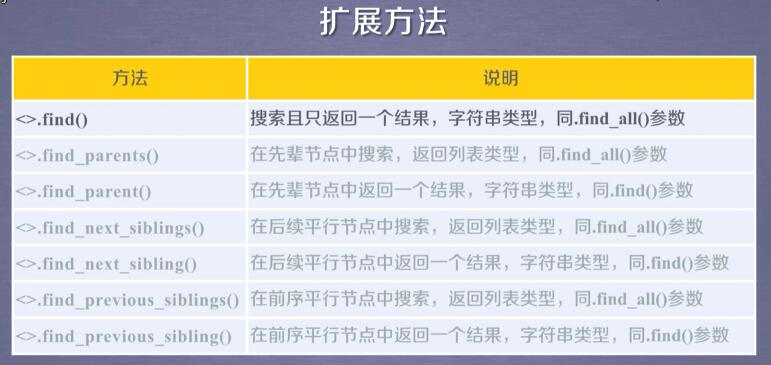
信息提取的一般方法
从标记的信息中提取要关注的内容



import requests
from bs4 import BeautifulSoup as bs
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
#print(demo)
soup = bs(demo, 'html.parser')
#print(soup.prettify())
#print(soup.find_all('a'))
for link in soup.find_all('a'): #寻找所有的外部链接
print(link.get('href'))’
基于HTML内容的查找方法
import requests
from bs4 import BeautifulSoup as bs
import re #正则表达库
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
#print(demo)
soup = bs(demo, 'html.parser')
#print(soup.prettify())
#print(soup.find_all('a'))
for tag in soup.find_all(re.compile('b')):#查找以b开头的所有标签
print(tag.name)