

数据读写
当保存数据时,目标文件已经存在的处理方式
保存模式不适用任何锁定,也不是原子操作
| Save Mode | 意义 |
|---|---|
| SaveMode.ErrorIfExists (默认) | 抛出一个异常 |
| SaveMode.Append | 将数据追加进去 |
| SaveMode.Overwrite | 将已经存在的数据删除,用新数据进行覆盖 |
| SaveMode.Ignore | 忽略,不做任何操作 |
val df = spark.read.load("path")
//val df = spark.read.json("path")
df.select("name", "age").write.mode(SaveMode.Overwrite).save("path")
//df.select("name", "age").write.mode(SaveMode.Overwrite).json("path")
全局临时视图
Spark SQL中的临时视图是session级别的,若需要spark应用级别的临时视图,可以使用全局临时视图.全局的临时视图存在于系统数据库 global_temp中, 必须加上库名去引用,如SELECT * FROM global_temp.view1.
df.createGlobalTempView("people");
spark.sql("SELECT * FROM global_temp.people").show();
//另一个session也可以访问
spark.newSession().sql("SELECT * FROM global_temp.people").show();
Parquet列式存储
列式存储优势
- 可以跳过不符合条件的数据,只读取需要的数据列,降低IO数据量。
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能。
val pdf = spark.read.parquet("users.parquet")
pdf.createTempView("users")
val result = spark.sql("select name from users")
result.show()
Parquet合并元数据
// 创建一个DataFrame,作为学生的基本信息,并写入一个parquet文件中
val studentsWithNameAge = Array(("leo", 23), ("jack", 25))
val studentsWithNameAgeDF = spark.createDataset(studentsWithNameAge).toDF("name", "age")
studentsWithNameAgeDF.write.mode(SaveMode.Append).parquet("D:\\spark-warehouse\\students")
studentsWithNameAgeDF.show()
// 创建第二个DataFrame,作为学生的成绩信息,并写入一个parquet文件中
val studentsWithNameGrade = Array(("marry", "A"), ("tom", "B")).toSeq
val studentsWithNameGradeDF = spark.createDataset(studentsWithNameGrade).toDF("name", "grade")
studentsWithNameGradeDF.write.mode(SaveMode.Append).parquet("D:\\spark-warehouse\\students")
// 两个DataFrame的元数据是不一样的
// 期望读取出来的表数据,自动合并两个文件的元数据,出现三个列,name、age、grade
// 用mergeSchema的方式,读取students表中的数据,进行元数据的合并
val students = spark.read.option("mergeSchema", "true")
.parquet("D:\\spark-warehouse\\students")
students.printSchema()
students.show()
表分区
partitionBy 创建一个 directory structure (目录结构),可以自动 discover (发现)和 infer (推断)分区信息,对 cardinality (基数)较高的 columns 的适用性有限
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过将 path/to/table 传递给 SparkSession.read.parquet 或 SparkSession.read.load , Spark SQL 将自动从路径中提取 partitioning information (分区信息),返回的 DataFrame 的 schema (模式)变成:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
从 Spark 1.6.0 开始, 默认情况下, partition discovery (分区发现)只能找到给定路径下的 partitions.对于上述示例, 如果用户直接使用path/to/table/gender=male 则 gender 将不被视为 partitioning column (分区列).
用户可以指定 partition discovery 应该开始的基本路径, 则可以在数据源选项中设置 basePath.例如, 当 path/to/table/gender=male是数据的路径并且用户将 basePath 设置为 path/to/table/, gender 将是一个 partitioning column (分区列)
模式合并
用户可以从一个 simple schema (简单的架构)开始, 并根据需要逐渐向 schema 添加更多的 columns . 以这种方式, 用户可能会使用不同但相互兼容的 schemas 的 多个 Parquet 文件
启用:
- 读取 Parquet 文件时, 将 data source option (数据源选项) mergeSchema 设置为 true
spark.sql.parquet.mergeSchema=true
Dataset<Row> squaresDF = spark.createDataFrame(squares, Square.class);
squaresDF.write().parquet("data/test_table/key=1");
Dataset<Row> cubesDF = spark.createDataFrame(cubes, Cube.class);
cubesDF.write().parquet("data/test_table/key=2");
Dataset<Row> mergedDF = spark.read().option("mergeSchema", true).parquet("data/test_table");//这里没有指定到key一级
mergedDF.printSchema();
// root
// |-- value: int (nullable = true) //square和cube都有的值
// |-- square: int (nullable = true)//square独有
// |-- cube: int (nullable = true)//cube独有
// |-- key: int (nullable = true)//分区值
Hive
将 hive-site.xml, core-site.xml(用于安全配置)和 hdfs-site.xml (用于 HDFS 配置)文件放在 conf/ 中
当 hive-site.xml 未配置时,上下文会自动在当前目录中创建 metastore_db,并创建由 spark.sql.warehouse.dir 配置的目录
spark2.x取消HiveContext,SparkSession实质上是SQLContext和HiveContext的组合
val spark = SparkSession
.builder()
.appName("Test")
.master("local")
.config("spark.sql.warehouse.dir", "D:\\spark-warehouse")
.enableHiveSupport()
.getOrCreate()
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive"); //USING hive
spark.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src");
val result = spark.sql("select ....")
//非临时表,会持久化
result.write.saveAsTable("")
当读取和写入 Hive metastore Parquet 表时, Spark SQL 将尝试使用自己的 Parquet 支持, 而不是 Hive SerDe 来获得更好的性能. 此行为由 spark.sql.hive.convertMetastoreParquet配置控制, 默认情况打开.
保存到持久表
saveAsTable将会持久化数据
对于基于文件的数据源, 如text, parquet, json等, 可以通过 path 选项自定义表路径df.write.option("path", "/some/path").saveAsTable("t") . 当表被 dropped 时,自定义表路径将不会被删除, 并且表数据仍然存在. 如果未指定自定义表路径, Spark 将把数据写入 warehouse directory 下的默认表路径. 当表被删除时,默认的表路径也将被删除.
指定 Hive 表的存储格式
创建 Hive 表时,需要定义如何 从/向 文件系统 read/write 数据,
默认以纯文本形式读取表格文件,指定存储格式CREATE TABLE src(id int) USING hive OPTIONS(fileFormat 'parquet')
| Property Name | Meaning |
|---|---|
| fileFormat | fileFormat是一种存储格式规范的包,包括 "serde","input format" 和 "output format"。 目前支持6个文件格式:'sequencefile','rcfile','orc','parquet','textfile'和'avro'。 |
| inputFormat, outputFormat | 这两个选项将相应的 "InputFormat" 和 "OutputFormat" 类的名称指定为字符串文字,例如: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat。 这两个选项必须成对出现,如果已经指定了 "fileFormat" 选项,则无法指定它们。 |
| serde | 此选项指定 serde 类的名称。 当指定 fileFormat 选项时,如果给定的 fileFormat 已经包含 serde 的信息,那么不要指定这个选项。 目前的 "sequencefile", "textfile" 和 "rcfile" 不包含 serde 信息,你可以使用这3个文件格式的这个选项。 |
| fieldDelim, escapeDelim, collectionDelim, mapkeyDelim, lineDelim | 这些选项只能与 "textfile" 文件格式一起使用。它们定义如何将分隔的文件读入行。 |
内置函数
聚合函数
按日统计访问次数
// 内置函数中,传入的参数,也是用单引号作为前缀的,其他的字段
userAccessLogRowDF.groupBy("date") // 调用groupBy()方法,对某一列进行分组
// 调用agg()方法 ,第一个参数为传入在groupBy()方法中出现的字段
// 第二个参数,传入countDistinct、sum、first等,Spark提供的内置函数
.agg('date, countDistinct('userid))
.map { row => Row(row(1), row(2)) }
.collect()
.foreach(println)
row_number()开窗函数
row_number()给每个分组的数据,按照其排序顺序,打上一个分组内的行号
比如有一个分组date=20151001,里面有3条数据,1122,1121,1124,
对分组的每一行使用row_number()开窗函数后,每行数据依次会获得一个组内的行号,
行号从1开始递增,比如1122 1,1121 2,1124 3
//按category分组取前3
DataFrame top3SalesDF = hiveContext.sql(""
+ "SELECT product,category,revenue "
+ "FROM ("
+ "SELECT "
+ "product,"
+ "category,"
+ "revenue,"
// row_number()函数后加OVER关键字
// PARTITION BY:根据哪个字段分组
// 可以用ORDER BY进行组内排序
// row_number()就可以给每个组内的行,一个组内行号
+ "row_number() OVER (PARTITION BY category ORDER BY revenue DESC) rank "
+ "FROM sales "
+ ") tmp_sales "
+ "WHERE rank<=3"); // 选择前三行
UDF自定义函数
简单自定义函数
// 注册函数:SQLContext.udf.register()
sqlContext.udf.register("strLen", (str: String) => str.length())
// 使用自定义函数
sqlContext.sql("select name,strLen(name) from names")
.collect()
.foreach(println)
复杂自定义函数
// 构造模拟数据
val names = Array("Leo", "Marry", "Jack", "Tom", "Tom", "Tom", "Leo")
val namesRDD = spark.sparkContext.parallelize(names, 5)
val namesRowRDD = namesRDD.map { name => Row(name) }
val structType = StructType(Array(StructField("name", StringType, true)))
val namesDF = spark.createDataFrame(namesRowRDD, structType)
// 注册一张names表
namesDF.createOrReplaceTempView("names")
// 定义和注册自定义函数
spark.udf.register("strCount", new StringCount)
// 使用自定义函数
spark.sql("select name,strCount(name) from names group by name")
.collect()
.foreach(println)
class StringCount extends UserDefinedAggregateFunction {
// inputSchema,输入数据的类型
def inputSchema: StructType = {
StructType(Array(StructField("str", StringType, true)))
}
// bufferSchema,中间进行聚合时,所处理的数据的类型
def bufferSchema: StructType = {
StructType(Array(StructField("count", IntegerType, true)))
}
// dataType,函数返回值的类型
def dataType: DataType = {
IntegerType
}
def deterministic: Boolean = {
true
}
// 为每个分组的数据执行初始化操作
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
}
// 由于Spark是分布式的,所以一个分组的数据,可能会在不同的节点上进行局部聚合,就是update
// 每个分组,有新的值进来的时候,如何进行分组对应的聚合值的计算
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getAs[Int](0) + 1
}
// 最后一个分组,在各个节点上的聚合值,要进行merge,也就是合并
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getAs[Int](0) + buffer2.getAs[Int](0)
}
// 最后,一个分组的聚合值,如何通过中间的缓存聚合值,最后返回一个最终的聚合值
def evaluate(buffer: Row): Any = {
buffer.getAs[Int](0)
}
}
计算结果
[Jack,1]
[Tom,3]
[Marry,1]
[Leo,2]
SparkSQL工作原理
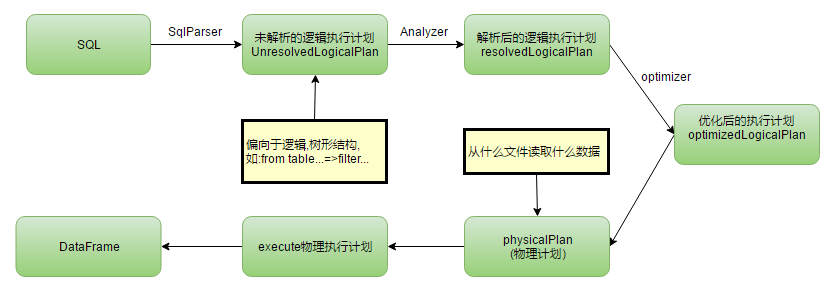
SparkSQL性能优化
- 设置Shuffle过程中的并行度
- 在Hive数据仓库建设过程中,合理设置数据类型;比如能设置为INT的,就不要设置为BIGINT。减少数据类型导致的不必要的内存开销。
- 编写SQL时,尽量给出明确的列名,比如
select name from students。不要写select *的方式。 - 并行处理查询结果:对于Spark SQL查询的结果,如果数据量比较大,比如超过1000条,那么就不要一次性
collect()到Driver再处理。使用foreach()算子,并行处理查询结果。 - 缓存表:对于一条SQL语句中可能多次使用到的表,可以对其进行缓存,使用
spark.catalog.cacheTable(tableName),或者DataFrame.cache()即可。Spark SQL会用内存列存储的格式进行表的缓存。Spark SQL就可以仅仅扫描需要使用的列,并且自动优化压缩,来最小化内存使用
内存缓存的配置可以使用 SparkSession 上的 setConf 方法或使用 SQL 运行 SET key=value 命令来完成
| 属性名称 | 默认 | 含义 |
|---|---|---|
| spark.sql.inMemoryColumnarStorage.compressed | true | 当设置为 true 时,Spark SQL 将根据数据的统计信息为每个列自动选择一个压缩编解码器。 |
| spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 控制批量的柱状缓存的大小。更大的批量大小可以提高内存利用率和压缩率,但是在缓存数据时会冒出 OOM 风险。 |
- 广播join表:
spark.sql.autoBroadcastJoinThreshold,默认10485760 (10 MB)。在内存够用的情况下,可以增加其大小,该参数设置了一个表在join的时候,最大在多大以内,可以被广播出去优化性能,设置为-1可以禁用广播。
NaN Semantics语义
当处理一些不符合标准浮点数语义的 float 或 double 类型时,对于 Not-a-Number(NaN) 需要做一些特殊处理. 具体如下:
NaN = NaN 返回 true.
在 aggregations(聚合)操作中,所有的 NaN values 将被分到同一个组中.
在 join key 中 NaN 可以当做一个普通的值.
NaN 值在升序排序中排到最后,比任何其他数值都大.
