

常见的 Research workflow
某一天, 你坐在实验室的椅子上, 突然:
1 你脑子里迸发出一个 idea
2 你看了关于某一 theory 的文章, 想试试: 要是把 xx 也加进去会怎么样3 你老板突然给你一张纸, 然后说: 那个谁, 来把这个东西实现一下
于是, 你设计了实验流程, 并为这一 idea 挑选了合适的数据集和运行环境, 然后你废寝忘食的实现了模型, 经过长时间的训练和测试, 你发现:
1 这 idea 不 work --> 那算了 or 再调调2 这 idea 很 work --> 可以写 paper 了
我们可以把上述流程用下图表示:
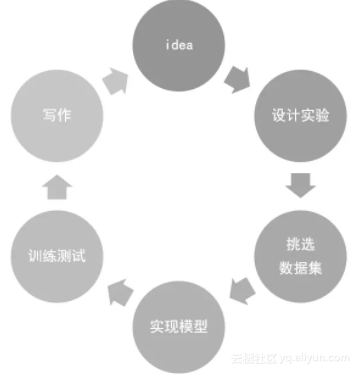
实际上, 常见的流程由下面几项组成起来:
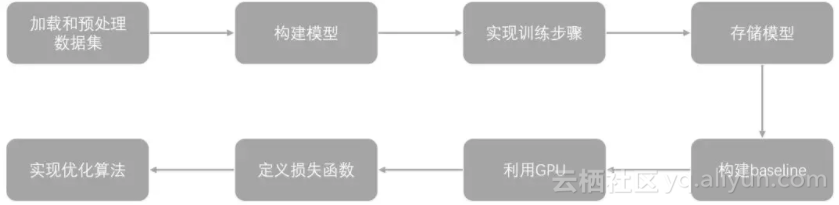
2 每个数据集的格式都不太一样
3 预处理和正则化的方式也不尽相同
4 需要一个快速的 dataloader 来 feed data, 越快越好
5 然后, 你就要实现自己的模型, 如果你是 CV 方向的你可能想实现一个 ResNet, 如果你是 NLP 相关的你可能想实现一个 Seq2Seq
6 接下来, 你需要实现训练步骤, 分 batch, 循环 epoch
7 在若干轮的训练后, 总要 checkpoint 一下, 才是最安全的
8 你还需要构建一些 baseline, 以验证自己 idea 的有效性
9 如果你实现的是神经网络模型, 当然离不开 GPU 的支持
10 很多深度学习框架提供了常见的损失函数, 但大部分时间, 损失函数都要和具体任务结合起来, 然后重新实现
11 使用优化方法, 优化构建的模型, 动态调整学习率
Pytorch 给出的解决方案
对于加载数据, Pytorch 提出了多种解决办法
1 Pytorch 是一个 Python 包, 而不是某些大型 C++ 库的 Python 接口, 所以, 对于数据集本身提供 Python API 的, Pytorch 可以直接调用, 不必特殊处理.2 Pytorch 集成了常用数据集的 data loader
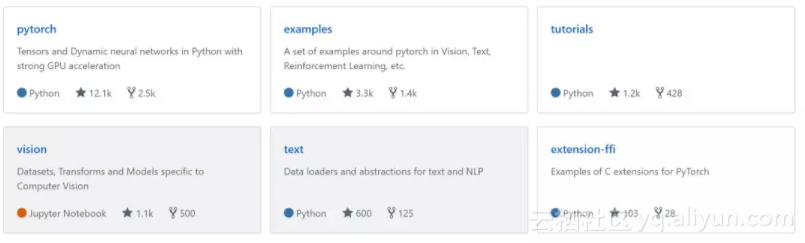
3 虽然以上措施已经能涵盖大部分数据集了, 但 Pytorch 还开展了两个项目: vision, 和 text, 见下图灰色背景部分. 这两个项目, 采用众包机制, 收集了大量的 dataloader, pre-process 以及 normalize, 分别对应于图像和文本信息.
4 如果你要自定义数据集,也只需要继承 torch.utils.data.dataset
对于构建模型, Pytorch 也提供了三种方案
1 众包的模型: torch.utils.model_zoo , 你可以使用这个工具, 加载大家共享出来的模型2 使用 torch.nn.Sequential 模块快速构建
net = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
print(net)
'''
Sequential (
(0): Linear (1 -> 10)
(1): ReLU ()
(2): Linear (10 -> 1)
)
'''- 集成 torch.nn.Module 深度定制
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1, 10, 1)
print(net)
'''
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
'''对于训练过程的 Pytorch 实现
你当然可以自己实现数据的 batch, shuffer 等, 但 Pytorch 建议用类 torch.utils.data.DataLoader 加载数据,并对数据进行采样,生成 batch迭代器。
# 创建数据加载器
loader = Data.DataLoader(
dataset=torch_dataset, # TensorDataset类型数据集
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 设置随机洗牌
num_workers=2, # 加载数据的进程个数
)
for epoch in range(3): # 训练3轮
for step, (batch_x, batch_y) in enumerate(loader): # 每一步
# 在这里写训练代码...
print('Epoch: ', epoch)对于保存和加载模型 Pytorch 提供两种方案
- 保存和加载整个网络
# 保存和加载整个模型, 包括: 网络结构, 模型参数等
torch.save(resnet, 'model.pkl')
model = torch.load('model.pkl')- 保存和加载网络中的参数
torch.save(resnet.state_dict(), 'params.pkl')
resnet.load_state_dict(torch.load('params.pkl'))对于 GPU 支持
你可以直接调用 Tensor 的. cuda() 直接将 Tensor 的数据迁移到 GPU 的显存上, 当然, 你也可以用. cpu() 随时将数据移回内存
if torch.cuda.is_available():
linear = linear.cuda() # 将网络中的参数和缓存移到GPU显存中对于 Loss 函数, 以及自定义 Loss
在 Pytorch 的包 torch.nn 里, 不仅包含常用且经典的 Loss 函数, 还会实时跟进新的 Loss 包括: CosineEmbeddingLoss, TripletMarginLoss 等.
如果你的 idea 非常新颖, Pytorch 提供了三种自定义 Loss 的方式
- 继承 torch.nn.module
import torch
import torch.nn as nn
import torch.nn.functional as func
class MyLoss(nn.Module):
# 设置超参
def __init__(self, a, b, c):
super(TripletLossFunc, self).__init__()
self.a = a
self.b = b
self.c = c
return
def forward(self, a, b, c):
# 具体实现
loss = a + b + c
return loss然后
loss_instance = MyLoss(...)
loss = loss_instance(a, b, c)这样做, 你能够用 torch.nn.functional 里优化过的各种函数来组成你的 Loss
- 继承 torch.autograd.Function
import torch
from torch.autograd import Function
from torch.autograd import Variable
class MyLoss(Function):
def forward(input_tensor):
# 具体实现
result = ......
return torch.Tensor(result)
def backward(grad_output):
# 如果你只是需要在loss中应用这个操作的时候,这里直接return输入就可以了
# 如果你需要在nn中用到这个,需要写明具体的反向传播操作
return grad_output这样做,你能够用常用的 numpy 和 scipy 函数来组成你的 Loss
- 写一个 Pytorch 的 C 扩展
这里就不细讲了,未来会有内容专门介绍这一部分。
对于优化算法以及调节学习率
Pytorch 集成了常见的优化算法, 包括 SGD, Adam, SparseAdam, AdagradRMSprop, Rprop 等等.
torch.optim.lr_scheduler 提供了多种方式来基于 epoch 迭代次数调节学习率 torch.optim.lr_scheduler.ReduceLROnPlateau 还能够基于实时的学习结果, 动态调整学习率.
原文发布时间为:2018-02-11
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号
