欢迎访问集智主站:集智,通向智能时代的引擎
注意!
本文所有代码均可在集智原贴中运行调试(无需安装环境),请点击这里前往原贴
得分与交叉验证得分
如前所见,每个预测器对象都带有score方法以判定对于新数据拟合(或预测)的质量,当然是越高越好。
示例:用支持向量分类对数字数据集做分类,并将得分赋值予变量score_svc。
# 从Scikit-learn库中导入数据集和支持向量机两个模块
from sklearn import datasets, svm
# 加载数字数据集并分别读入特征和标签
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
# 支持向量分类
svc = svm.SVC(C=1, kernel='linear')
score_svc = svc.fit(X_digits[:-100], y_digits[:-100]).score(X_digits[-100:], y_digits[-100:])
# 从Scikit-learn库中导入数据集和支持向量机两个模块
from sklearn import datasets, svm
# 加载数字数据集并分别读入特征和标签
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
# 支持向量分类
svc = svm.SVC(C=1, kernel='linear')
score_svc = svc.fit(X_digits[:-100], y_digits[:-100]).score(X_digits[-100:], y_digits[-100:])
score_svc > 0.9
KFold交叉验证
为了得到更好的预测精度,我们可以将训练/测试数据分成若干份:
from sklearn import datasets, svm
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
svc = svm.SVC(C=1, kernel='linear')
import numpy as np
# 将数据分为3份
X_folds = np.array_split(X_digits, 3)
y_folds = np.array_split(y_digits, 3)
scores_cross = list()
# 对每组数据分别用SVC做分类,并输出结果得分
for k in range(3):
# 用list()函数复制以便之后通过pop()方法调用
X_train = list(X_folds)
X_test = X_train.pop(k)
X_train = np.concatenate(X_train)
y_train = list(y_folds)
y_test = y_train.pop(k)
y_train = np.concatenate(y_train)
# SVC分类并将得分添加至scores_cross变量
scores_cross.append(svc.fit(X_train, y_train).score(X_test, y_test))
print(scores)
import numpy as np
# 将数据分为3份
X_folds = np.array_split(X_digits, 3)
y_folds = np.array_split(y_digits, 3)
scores_cross = list()
# 对每组数据分别用SVC做分类,并输出结果得分
for k in range(3):
# 用list()函数复制以便之后通过pop()方法调用
X_train = list(X_folds)
X_test = X_train.pop(k)
X_train = np.concatenate(X_train)
y_train = list(y_folds)
y_test = y_train.pop(k)
y_train = np.concatenate(y_train)
# SVC分类并将得分添加至scores_cross变量
scores_cross.append(svc.fit(X_train, y_train).score(X_test, y_test))
print(scores)
np.mean(scores_cross) > 0.9
交叉验证生成器
Scikit-learn有一系列类可以用于为交叉验证策略产生训练/测试序列数组。这些类提供split方法,以待切分的数据集作为输入参数,然后产生序列数组,在交叉验证中充当迭代依据。
下例演示了split方法的用途:
import numpy as np
from sklearn import datasets, svm
svc = svm.SVC(C=1, kernel='linear')
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
from sklearn.cross_validation import KFold, cross_val_score
X = ["a", "a", "b", "c", "c", "c"]
k_fold = KFold(n=6, n_folds=3)
for train_indices, test_indices in k_fold:
print('Train: %s | test: %s' % (train_indices, test_indices))
scores_kf = [svc.fit(X_digits[train], y_digits[train]).score(X_digits[test], y_digits[test]) for train, test in k_fold]
from sklearn.cross_validation import KFold, cross_val_score
X = ["a", "a", "b", "c", "c", "c"]
k_fold = KFold(n=6,n_folds=3)
for train_indices, test_indices in k_fold:
print('Train: %s | test: %s' % (train_indices, test_indices))
scores_kf = [svc.fit(X_digits[train], y_digits[train]).score(X_digits[test], y_digits[test]) for train, test in k_fold]
np.mean(scores_kf) > 0.9
交叉验证得分可在cross_val_score的帮助下直接计算得出。给定某个预测器,交叉验证对象和输入数据集,cross_val_scroe将数据反复分割为训练集/测试集,并用训练集训练预测器再基于测试集为每次迭代计算得分。
默认设置下,预测器的score方法被用于计算各个得分。
from sklearn import datasets, svm
svc = svm.SVC(C=1, kernel='linear')
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
# n_jobs=-1表示计算将被分配到计算机的所有CPU上
#'scoring'参数可以指定特别的得分计算方式
cross_val_score(svc, X_digits, y_digits, cv=k_fold, n_jobs=-1,scoring='precision_macro')
# n_jobs=-1表示计算将被分配到计算机的所有CPU上
#'scoring'参数可以指定特别的得分计算方式
cross_val_score(svc, X_digits, y_digits, cv=k_fold, n_jobs=-1,scoring='precision_macro')
# n_jobs=-1表示计算将被分配到计算机的所有CPU上
运行示例代码,查看输出结果。
| KFold (n_splits, shuffle, random_state) | StratifiedKFold (n_iter, test_size, train_size, random_state) | GroupKFold (n_splits, shuffle, random_state) |
|---|---|---|
| 分为K份,K-1用于训练,余下的用作测试 | 与K-Fold相同,但是每个组都保持了类别分布 | 确保同组数据不会同时出现在训练集和测试集中 |
| ShuffleSplit (n_iter, test_size, train_size, random_state) | StratifiedShuffleSplit | GroupShuffleSplit |
| 随机产生训练/测试序列 | 与Shuffle分割相同,但是在每次迭代中保持了类别分布S | 确保同组数据不会同时出现在训练集和测试集中 |
| LeaveOneGroupOut () | LeavePGroupsOut (p) | LeaveOneOut () |
| 剔除一个组 | 剔除P个组 | 剔除1个采样 |
| LeavePOut (p) | PredefinedSplit | |
| 剔除P个采样 | 基于预定义分割产生训练/测试序列 |
练习:
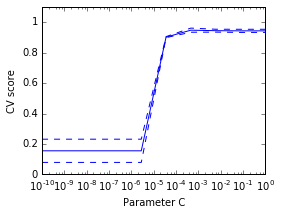
对数字数据集(digits dataset),以图象形式绘出一个SVC预测器(线性核)的交叉验证得分,与参数C的函数关系(使用对数轴,从1到10)。
%matplotlib inline
import numpy as np
from sklearn.cross_validation import cross_val_score
from sklearn import datasets, svm
digits = datasets.load_digits()
X = digits.data
y = digits.target
svc = svm.SVC(kernel='linear')
C_s = np.logspace(-10, 0, 10)
# 以下由读者完成全部程序
import numpy as np
from sklearn.cross_validation import cross_val_score
from sklearn import datasets, svm
digits = datasets.load_digits()
X = digits.data
y = digits.target
svc = svm.SVC(kernel='linear')
C_s = np.logspace(-10, 0, 10)
scores = list()
scores_std = list()
for C in C_s:
svc.C = C
this_scores = cross_val_score(svc, X, y, n_jobs=1)
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
# 绘制图象
import matplotlib.pyplot as plt
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.semilogx(C_s, scores)
plt.semilogx(C_s, np.array(scores) + np.array(scores_std), 'b--')
plt.semilogx(C_s, np.array(scores) - np.array(scores_std), 'b--')
locs, labels = plt.yticks()
plt.yticks(locs, list(map(lambda x: "%g" % x, locs)))
plt.ylabel('CV score')
plt.xlabel('Parameter C')
plt.ylim(0, 1.1)
plt.show()
网格搜索与交叉验证预测器
网格搜索
Scikit-learn提供一种对象:在参数网格上对给定的数据计算预测器的拟合得分,并选择合适的参数以期获得最大交叉验证得分。此对象在构建时以预测器为输入,并提供预测器API:
import numpy as np
from sklearn import datasets, svm
svc = svm.SVC(kernel='linear')
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import cross_val_score
Cs = np.logspace(-6, -1, 10)
# 构建分类器对象
clf = GridSearchCV(estimator=svc, param_grid=dict(C=Cs), n_jobs=-1)
clf.fit(X_digits[:1000], y_digits[:1000])
# 获取并输出最佳得分
score_best = clf.best_score_
print(score_best)
# 获取并输出最佳得分对应的参数C
C_best = clf.best_estimator_.C
print(C_best)
# 测试集上的预测表现不如训练集
score_train = clf.score(X_digits[1000:], y_digits[1000:])
print(score_train)
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import cross_val_score
Cs = np.logspace(-6, -1, 10)
# 构建分类器对象
clf = GridSearchCV(estimator=svc, param_grid=dict(C=Cs), n_jobs=-1)
clf.fit(X_digits[:1000], y_digits[:1000])
# 获取并输出最佳得分
score_best = clf.best_score_
print(score_best)
# 获取并输出最佳得分对应的参数C
C_best = clf.best_estimator_.C
print(C_best)
# 测试集上的预测表现不如训练集
score_train = clf.score(X_digits[1000:], y_digits[1000:])
print(score_train)
score_best > 0.9
用GridSearchCV()函数生成参数样本空间,使参数C迭代并计算相应预测得分。
默认设置下,GridSearchCV使用3重交叉验证(3-fold cross-validation)。但是如果程序检测到输入参数是分类器而非回归器,将使用分层3重交叉验证(stratified 3-fold)。
嵌套交叉验证
两个交叉验证循环并行运行:一个通过GridSearchCV设置值,另一个通过
cross_val_scroe衡量预测器的预测表现。所得的分数将是对于新数据的无偏估计。
警告: 不能在并行计算时嵌套对象(n_jobs必须为1)
交叉验证预测器
用于设置参数的交叉验证可以基于“算法决定算法”准则。这就是为什么对于特定预测器,Scikit-learn提供Cross-validation: evaluating estimator performance预测器,此类预测器的参数由交叉验证自动生成。
这些预测器的名称与他们的对应基础版本很像,只是名字后面多了个'CV'。
from sklearn import linear_model, datasets
lasso = linear_model.LassoCV()
diabetes = datasets.load_diabetes()
X_diabetes = diabetes.data
y_diabetes = diabetes.target
lasso.fit(X_diabetes, y_diabetes)
# 预测器自动选择了lambda
lasso.alpha_
from sklearn import linear_model, datasets
lasso = linear_model.LassoCV()
diabetes = datasets.load_diabetes()
X_diabetes = diabetes.data
y_diabetes = diabetes.target
lasso.fit(X_diabetes, y_diabetes)
# 预测器自动选择了lambda
lasso.alpha_
lasso.alpha_ > 0
使用LassoCV线性模型,对糖尿病数据集做拟合,输出自动选择的lambda参数。
练习
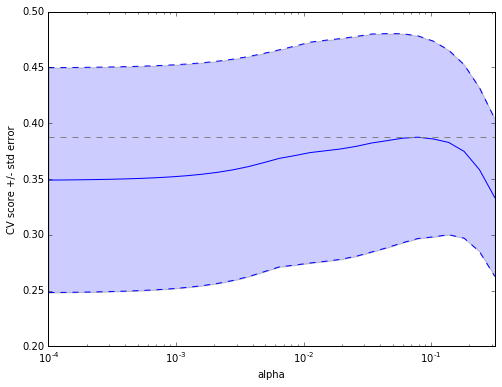
基于糖尿病数据集,寻找更好的正则化参数alpha。
On the diabetes dataset, find the optimal regularization parameter alpha.
Bonus: How much can you trust the selection of alpha?
进阶问题:alpha的选择可信度几何?
%matplotlib inline
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LassoCV
from sklearn.linear_model import Lasso
from sklearn.cross_validation import KFold
from sklearn.cross_validation import cross_val_score
diabetes = datasets.load_diabetes()
# 以下由读者完成全部程序
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = Lasso(random_state=0)
alphas = np.logspace(-4, -0.5, 30)
scores = list()
scores_std = list()
n_folds = 3
for alpha in alphas:
lasso.alpha = alpha
this_scores = cross_val_score(lasso, X, y, cv=n_folds, n_jobs=1)
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
scores, scores_std = np.array(scores), np.array(scores_std)
plt.figure().set_size_inches(8, 6)
plt.semilogx(alphas, scores)
# plot error lines showing +/- std. errors of the scores
std_error = scores_std / np.sqrt(n_folds)
plt.semilogx(alphas, scores + std_error, 'b--')
plt.semilogx(alphas, scores - std_error, 'b--')
# alpha=0.2 controls the translucency of the fill color
plt.fill_between(alphas, scores + std_error, scores - std_error, alpha=0.2)
plt.ylabel('CV score +/- std error')
plt.xlabel('alpha')
plt.axhline(np.max(scores), linestyle='--', color='.5')
plt.xlim([alphas[0], alphas[-1]])
np.mean(scores) > 0.3
首先生成alpha的样本空间,再对alpha进行迭代并绘制对应score图象。