

最近百万英雄之类的答题软件广受大家的喜爱,不过对于我这菜鸟基本没有拿过奖。 但是作为一名码农怎么能忍,于是研究出了即将要与大家分享的答题神器。
流程:
首先,带着大家捋一遍流程:
first:将手机屏幕投影到电脑上,或者开启模拟器,在电脑上,将问题和答案截图
second:进行图像识别,将问题和答案转换成文字
third:百度搜索问题和答案并爬取数据
fourth:进行数据分析,给出答案
投影/模拟器
本人使用的iphone和Mac进行投影,只需要通过quickTime即可。

如果是安卓机,你也可以使用vysor

如果不想投影的小伙伴可以下载夜神模拟器或者Genymotion模拟器。 ok,这一步太简单了,就不多说了。
图像识别
其实我的上一篇文章就是为了这一篇做铺垫,我在python人工智能-图像识别文章中已经详细介绍了如何通过PIL截取图片,并通过pytesseract进行文字识别。这里我就不详细讲述了,同学们可以看上一篇。
这里直接上代码:
#这里根据个人电脑截取投影到电脑的问题和答案区域:
image = ImageGrab.grab(bbox=(50, 410, 750, 1100))
image.save(IMAGE_PATH)
image = Image.open(IMAGE_PATH)
character = pytesseract.image_to_string(image, lang="chi_sim+eng", config="-psm 4")
print(character)
list = character.split('\n\n')
question = list[0]
answerOne = list[1]
answerTwo = list[2]
answerThree = list[3]这里我们使用config="-psm 4",因为我们这里问题和答案相当于一个文本列.
例如下列问题:

image = ImageGrab.grab(bbox=(50, 410, 750, 1100))
image.save(IMAGE_PATH)通过上面的代码,我们会先获得到问题和答案的截图:

然后通过下面的代码识别图中的文字,并保存到变量中,后面会用到:
image = Image.open(IMAGE_PATH)
character = pytesseract.image_to_string(image, lang="chi_sim+eng", config="-psm 4")
print(character)
list = character.split('\n\n')
question = list[0]
answerOne = list[1]
answerTwo = list[2]
answerThree = list[3]运行后
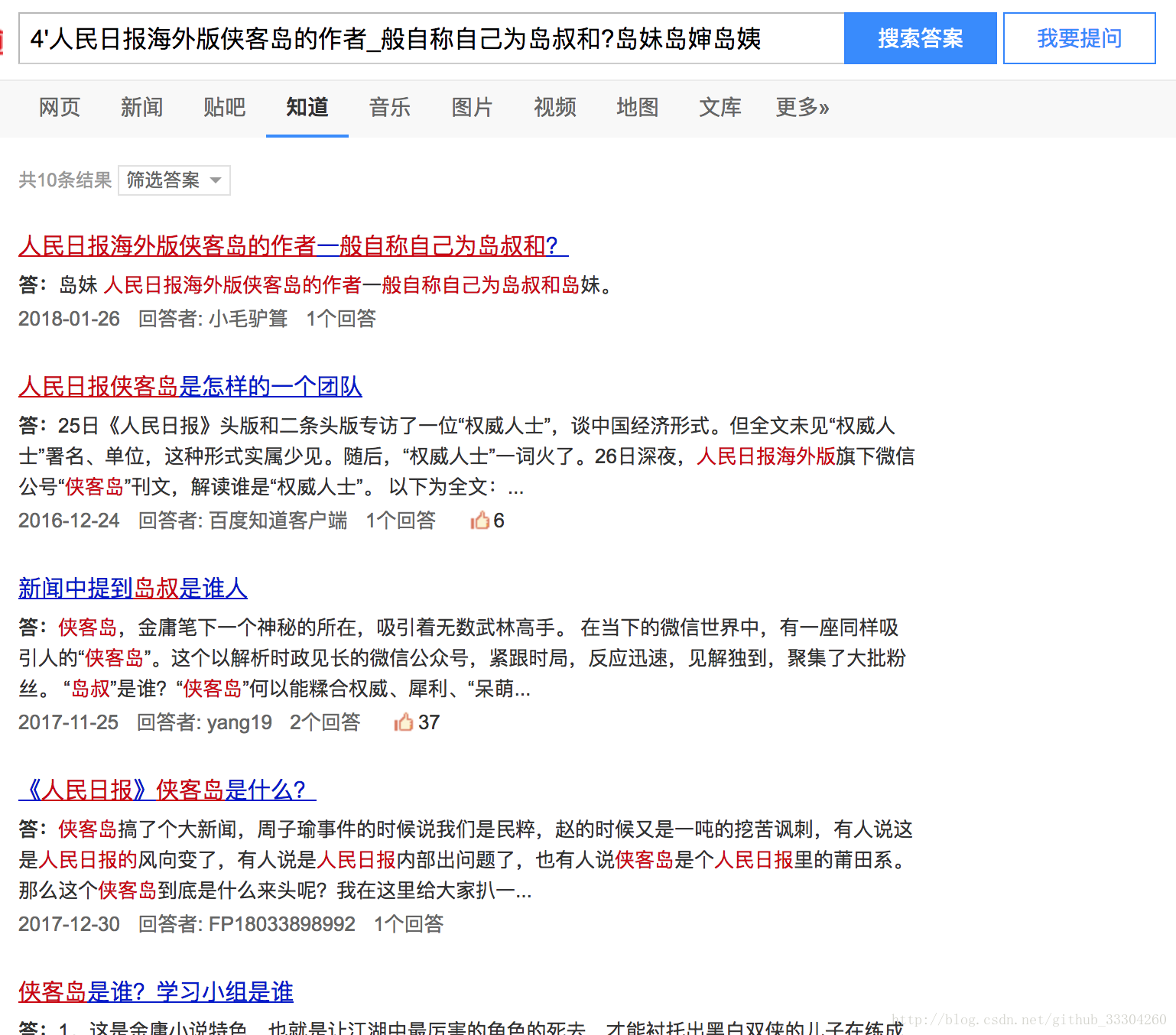
question : 4'人民日报海外版侠客岛的作者_般自称自己为岛叔和?
answerOne : 岛妹
answerTwo : 岛婶
answerThree : 岛姨这下我们的到来问题和答案,接下来就去搜索答案,由于我门没有强大的后台,所以只能自己去百度爬取数据。
搜索答案
这里我们用到了python库中的requests、BeautifulSoup和urllib.request
这篇文章就不具体讲解爬虫的基本知识了。
import requests
from bs4 import BeautifulSoup
import urllib.request
#百度知道网
BASE_URL = 'https://zhidao.baidu.com/search?ct=17&pn=0&tn=ikaslist&rn=10&fr=wwwt&word={}'
#将上面图像识别后的问题放到百度知道去搜索答案
questionParm = urllib.request.quote(question)
url = BASE_URL.format(questionParm)上面的代码运行后会得到如下链接
zhidao.baidu.com/search?ct=1…
接下来就通过我们的BeautifulSoup去解析页面
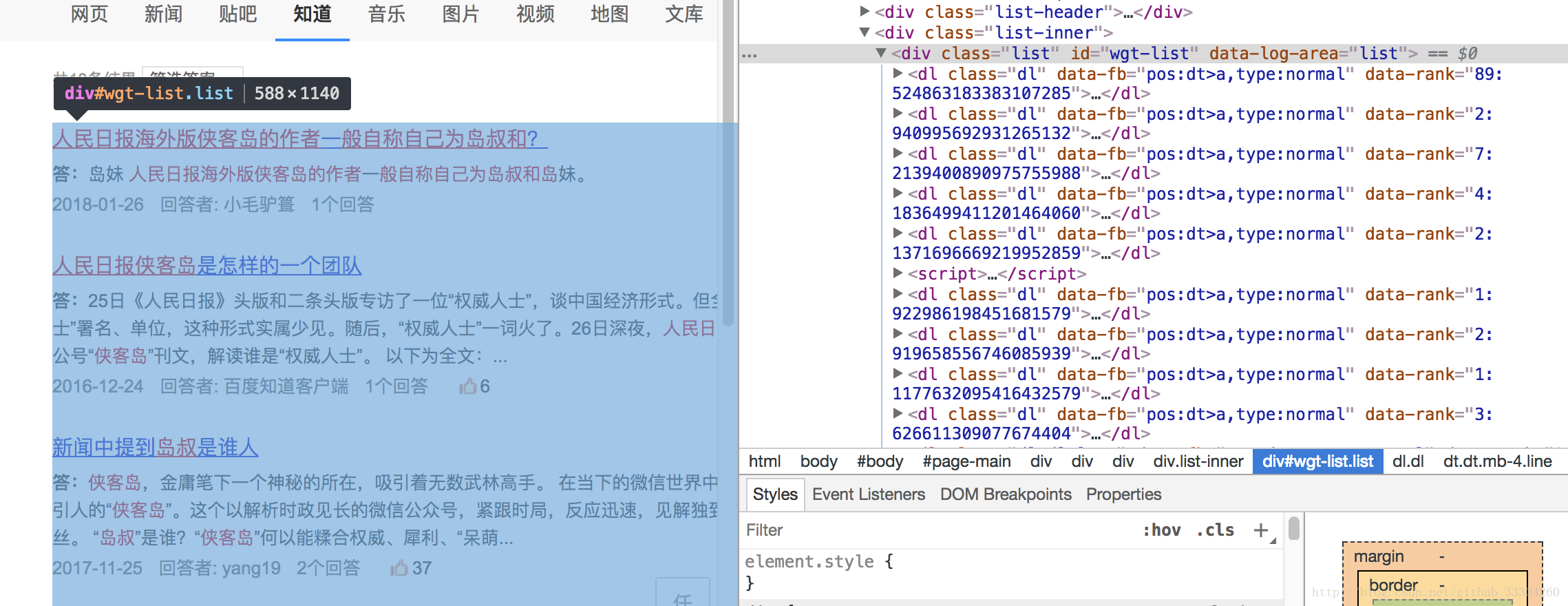
html = requests.get(url) # requests 请求页面内容 由于百科搜索没有限制爬取,所以不用设置伪请求头
soup = BeautifulSoup(html.content, "html.parser") # BeautifulSoup解析页面内容
items = soup.find_all("dl", "dl") # 获取所有的答案内容
for i in items:
firstResult = i.find("dd", "dd summary") #百度知道的问题
secondresult = i.find("dd", "dd answer") #百度知道的答案数据分析
到这里我们已经有了如下的数据:

for i in items:
firstResult = i.find("dd", "dd summary")
secondresult = i.find("dd", "dd answer")
if firstResult is not None:
countAnswerOne += firstResult.text.count(answerOne)
countAnswerTwo += firstResult.text.count(answerTwo)
countAnswerThree += firstResult.text.count(answerThree)
print(firstResult.text)
if secondresult is not None:
countAnswerOne += secondresult.text.count(answerOne)
countAnswerTwo += secondresult.text.count(answerTwo)
countAnswerThree += secondresult.text.count(answerThree)
print(secondresult.text) 通过统计答案在搜索结果中的次数来给出推荐答案(较为复杂的推荐结果尚在完善之中,敬请期待)
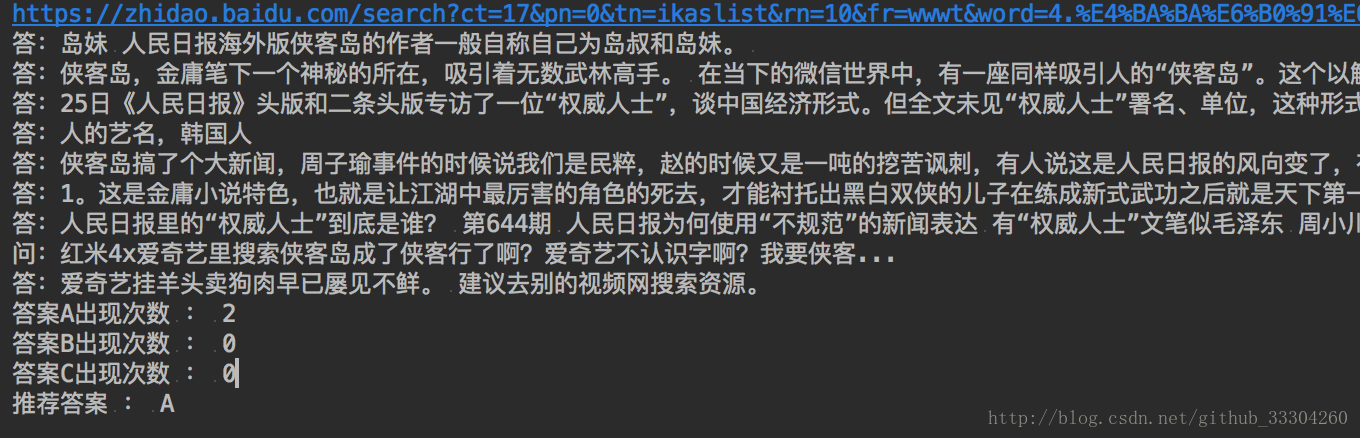
至少我们心中可以快速的检索到答案,并且有推荐答案,提高了答题正正确率,哈哈。

欢迎关注“伟大程序员的诞生”公众号,获取更多干货,同时欢迎来稿
想要获取源码:关注公众号–》回复:“百万英雄” 。即可获取源代码。
公众号回复“资料获取”,获取更多干货哦~
