

node.js的强大就无需再去重复了,越来越多的公司在使用node.js,还有一点不得不提的优势就是node用的是javascript的语言,对于前端开发工程师来说,没有理由不去get这一强大的技能。现在本人也是在学习阶段,结合自己做的一些demo进行总结。今天给大家分享一下用node.js实现一个简易的爬虫,希望能和大家一起交流探讨。
目标:
当在浏览器中访问'http://localhost:3000'的时候,可以以json的形式输出慕课网首页的 部分热门课程(本人偶尔会去慕课网上看一些学习的视频)
步骤
1.新建一个文件夹,进去之后'npm init'(这个命令的作用就是帮我们互动式地生成一份 最简单的 package.json 文件,init 是 initialize 的意思,初始化。
)当一路回车并且填写信息完毕后会出现一个package.json文件(首先需要在电脑上安装node.js)。
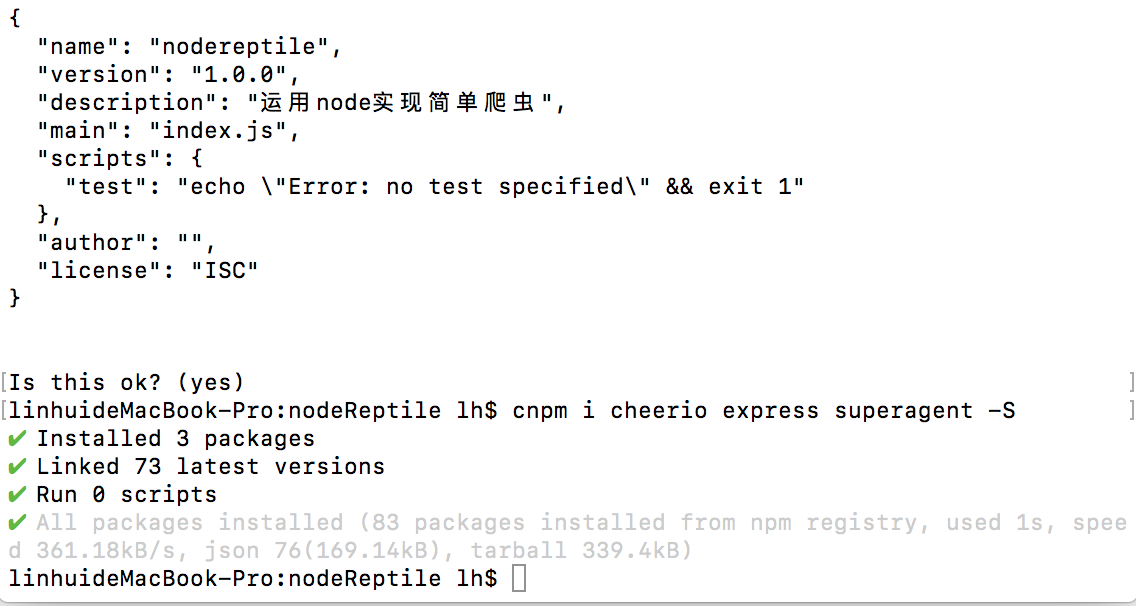
2.安装相应的依赖,在此例子中,需要用到的有cheerio,express,superagent。其中 express 是 Node.js 应用最广泛的 web 框架,建议大家有时间可以多去官网看看其API,所以现在开始安装依赖,通过命令cnpm i cheerio express superagent -S完成依赖的安装。安装完成后效果如下图:
3.现在在文件夹里建一个js文件,比如取名为index.js,接下来就是在里面写代码,话不多说,直接上代码,在代码中也做了较为详细的注释。
//引入模块
var express = require('express');
var cheerio = require('cheerio');
var superagent = require('superagent');
// 调用 express 实例,它是一个函数,不带参数调用时,会返回一个 express 实例,将这个变量赋予 app 变量。
var app = express();
// app 本身有很多方法,其中包括最常用的 get、post、put/patch、delete,在这里我们调用其中的 get 方法,为我们的 `/` 路径指定一个 handler 函数。
// 这个 handler 函数会接收 req 和 res 两个对象,他们分别是请求的 request 和 response。
// request 中包含了浏览器传来的各种信息,比如 query 啊,body 啊,headers 啊之类的,都可以通过 req 对象访问到。
// res 对象,我们一般不从里面取信息,而是通过它来定制我们向浏览器输出的信息,比如 header 信息,比如想要向浏览器输出的内容。
//这里我们调用了它的 #send 方法,向浏览器输出一个字符串。
app.get('/', function (req, res, next) {
superagent.get('https://www.imooc.com/')
.end(function (err, sres) {
if (err) {
return next(err);
}
// sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
var $ = cheerio.load(sres.text);
var items = [];
$('.banner-course-card .clearfix').each(function (idx, element) {
var $element = $(element);
items.push({
title: $element.attr('title'),
href: $element.attr('href')
});
});
res.send(items);
// 定义好我们 app 的行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,
//会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。
});
});
app.listen(3000, function () {
console.log('app is listening at port 3000');
});
代码解释:
通过请求得到网页的html内容并储存于sres.text中,再传给cheerio.load,得到一个实现jquery接口的变量,然后就类似于jquery选择器的方法对页面的元素的查找,拿到自己想要的数据即可。在定义好行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。
运行:
输入命令 ' node index.js ' , 会看到打印出'app is listening at port 3000 ',如图所示:

打开浏览器,访问'http://localhost:3000/',就可以看到我们爬虫得来的数据哦,如下图所示:

只是用了最基本的node实现了一个简易的爬虫效果,当然在这个例子中并没有利用到node.js的异步并发特性,待深入研究再做分享,希望和大家多多交流探讨。
