

发布人:TensorFlow 团队
欢迎阅读介绍 TensorFlow 数据集和估算器的博客系列的第 3 部分。第 1 部分重点介绍了预制估算器,第 2 部分讨论了特征列。在今天的第 3 部分中,您将了解如何创建自定义估算器。需要特别注意的是,我们将演示在解决鸢尾花问题时,如何创建模仿
如果您感觉不耐烦,尽请对比下面的完整程序:
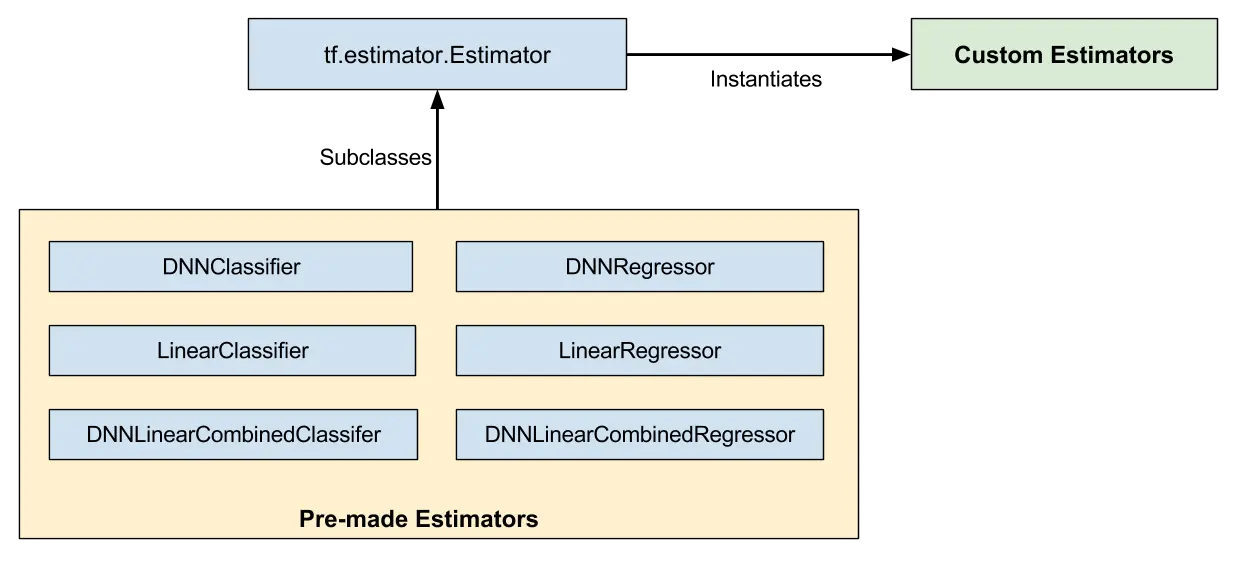
如图 1 所示,预制估算器是
预制估算器是全成品。但有时您需要更多地控制估算器的行为。自定义估算器应运而生。
您可以创建自定义估算器来仅执行某些操作。例如,如果需要以某种不同寻常的方式连接的隐藏层,则可以编写自定义估算器。如果想要计算模型的独特指标,也可以编写自定义估算器。从根本上讲,如果您需要针对特定问题优化的估算器,都可以编写自定义估算器。
模型函数 (
您的模型函数可以实现多种算法,定义各种隐藏层和指标。像输入函数一样,所有模型函数都必须接受一组标准输入参数,并返回一组标准输出值。输入参数可以利用 Dataset API,模型函数可以利用 Layers API 和 Metrics API。
在演示如何以自定义估算器形式实现鸢尾花之前,请回想一下,我们在本系列的第 1 部分是如何以预制估算器形式实现鸢尾花的。在第 1 部分,我们为鸢尾花数据集简单地创建了一个完全连接的深度神经网络,方式是将 预制估算器实例化,如下所示:
上述代码会创建一个具有下列特征的深度神经网络:
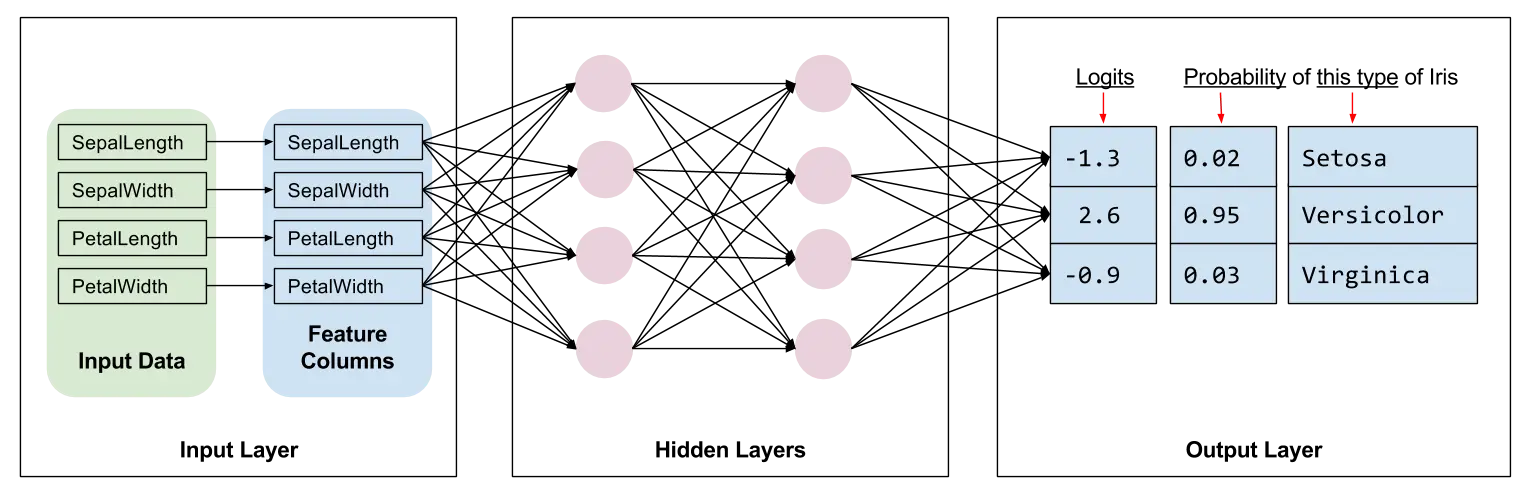
图 2 显示了鸢尾花模型的输入层、隐藏层和输出层。为清楚起见,我们在每个隐藏层中只绘制了 4 个节点。
下面我们来看看如何使用自定义估算器解决同样的鸢尾花问题。
估算器框架的一项最大优势在于,不需要改变数据管道就可以试验不同的算法。因此,我们将重复利用第 1 部分中的大量输入函数:
请注意,输入函数会返回下面两个值:
如需了解有关输入函数的完整详细信息,请参阅第 1 部分。
如本系列第 2 部分详述,您必须定义模型的特征列,以便指定每个特征的表示形式。无论是使用预制估算器还是自定义估算器,特征列的定义方式都一样。例如,以下代码会创建表示鸢尾花数据集中四个特征(全数值)的特征列:
我们现在准备为自定义估算器编写
前两个参数是从输入函数返回的特征和标签;也就是说,
要实现典型的模型函数,必须执行以下操作:
如果您的自定义估算器生成深度神经网络,那么您必须定义以下三个层:
使用 Layers API (
如果自定义估算器生成线性模型,则只需生成一个层,我们将在下一部分介绍。
调用
上面一行代码会创建输入层,通过输入函数读取
要为线性模型创建输入层,请调用
如果要创建深度神经网络,您必须定义一个或多个隐藏层。Layers API 具有丰富的函数,可以定义所有类型的隐藏层,包括卷积层、池化层和退出层。对于鸢尾花,我们只需调用两次

图 3.输入层馈入隐藏层 1。

图 4.隐藏层 1 馈入隐藏层 2。
请注意,
我们再次调用
请注意,输出层从

图 5.隐藏层 2 馈入输出层。
在定义输出层时,
由于输出层是最后一个层,因此,对
创建模型函数的最后一步是编写实现预测、评估和训练的分支代码。
当有人调用估算器的
注意第三个参数
例如,假设您实例化自定义估算器来生成一个名为
估算器框架随后会调用
模型函数必须提供代码来处理所有三个
使用
模型在进行预测之前必须经过训练。训练后的模型存储在您实例化估算器时建立的磁盘目录中。
在我们这个示例中,用于生成预测的代码如下所示:
代码块出奇地简单 - 代码行就像长管尽头的一个桶,只等预测落入。毕竟,估算器已经完成了进行预测的所有繁重工作:
输出层是
请注意,最大的值已分配给名为
使用
我们可以调用
现在我们把注意力转向指标。虽然返回指标是可选的,但大多数自定义估算器都会至少返回一个指标。TensorFlow 提供 Metrics API (
使用
因此,我们将创建一个包含唯一指标 (
使用
我们必须先实例化优化程序对象。我们从以下代码块中选择了 Adagrad (
然后,我们通过在优化器上建立目标来训练模型,尽可能减小其
在下面的代码中,可选的
使用
下面是代码:
模型函数现已完成!
在创建新的自定义估算器之后,您肯定希望用一下。首先
通过
使用我们的估算器训练、评估和预测的其余代码跟第 1 部分介绍的预制
像第 1 部分一样,我们可以在 TensorBoard 中查看训练结果。要查看此报告,请按照下面所示从您的命令行启动 TensorBoard:
然后浏览至以下网址:
所有预制估算器都会自动将大量信息记录到 TensorBoard。但使用自定义估算器时,TensorBoard 只提供一个默认日志(损耗图表),以及我们明确指示 TensorBoard 记录的信息。因此,TensorBoard 会从自定义估算器生成以下图表:
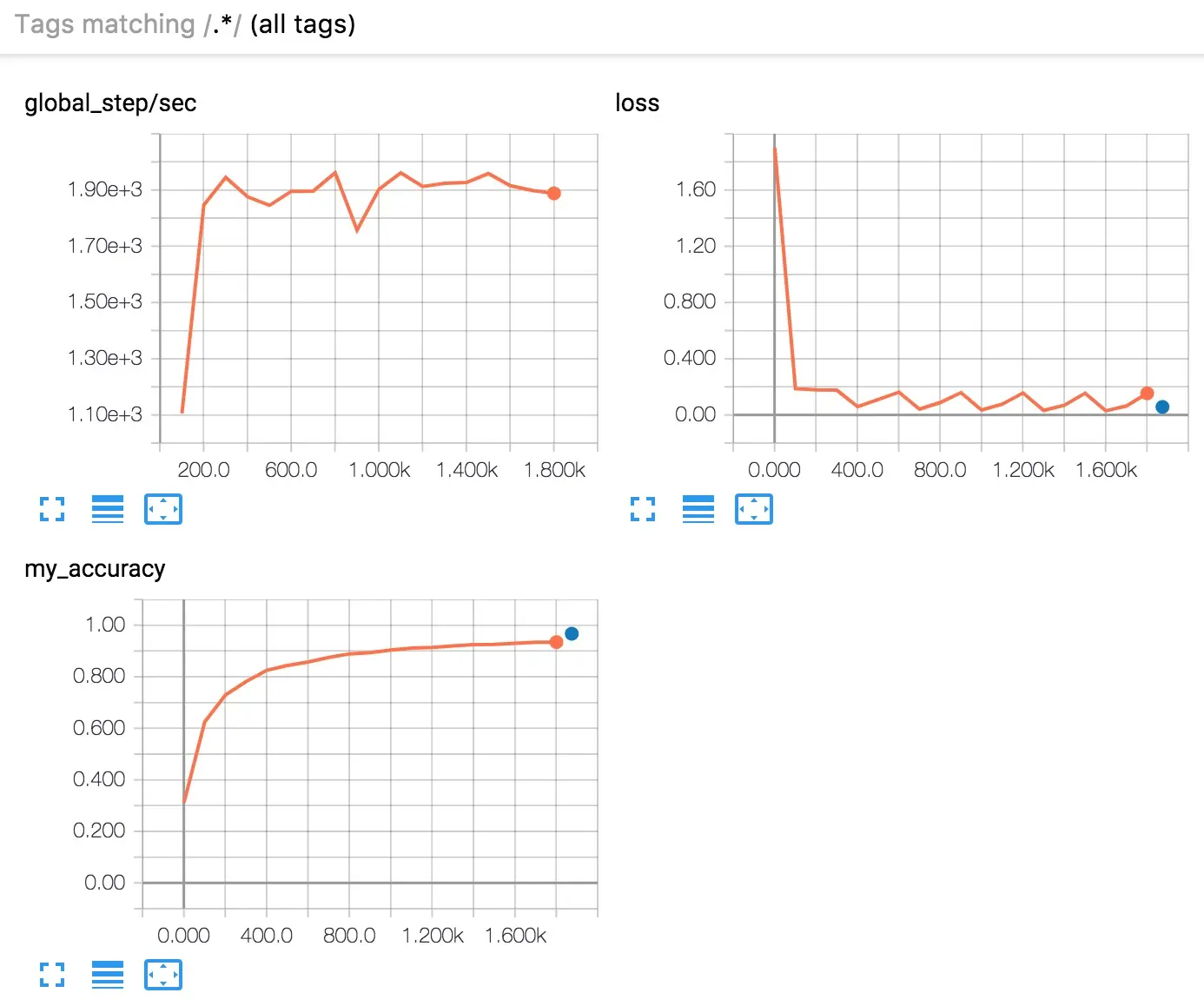
图 6.TensorBoard 显示三个图表。
简言之,这三个图表可以告诉您下列信息:
注意
在
根据图 7 中的提示,您可以查看并选择性地停用/启用左侧的训练和评估报告。(图 7 显示我们保留了两者的报告。)
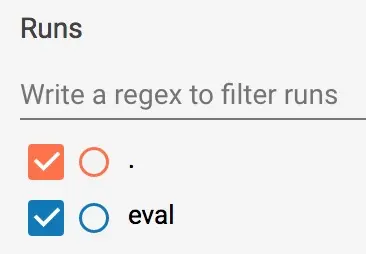
图 7.启用或停用报告。
要查看橙色图表,您必须指定一个全局步骤。结合
虽然预制估算器可以成为一种快速创建新模型的有效方式,但您经常需要自定义估算器具备的更大灵活性。幸运的是,预制和自定义估算器采用相同的编程模型。唯一的实际差异是您必须为自定义估算器编写模型函数,其他一切都相同!
如需了解更多详情,请参阅下面的资源:
祝大家 TensorFlow 编码愉快,我们下次再见!
欢迎阅读介绍 TensorFlow 数据集和估算器的博客系列的第 3 部分。第 1 部分重点介绍了预制估算器,第 2 部分讨论了特征列。在今天的第 3 部分中,您将了解如何创建自定义估算器。需要特别注意的是,我们将演示在解决鸢尾花问题时,如何创建模仿
DNNClassifier 行为的自定义估算器。 如果您感觉不耐烦,尽请对比下面的完整程序:
预制与自定义对比
如图 1 所示,预制估算器是
tf.estimator.Estimator 基类的子类,而自定义估算器是 tf.estimator.Estimator: 的实例化 
图 1.预制和自定义估算器都是估算器。
预制估算器是全成品。但有时您需要更多地控制估算器的行为。自定义估算器应运而生。
您可以创建自定义估算器来仅执行某些操作。例如,如果需要以某种不同寻常的方式连接的隐藏层,则可以编写自定义估算器。如果想要计算模型的独特指标,也可以编写自定义估算器。从根本上讲,如果您需要针对特定问题优化的估算器,都可以编写自定义估算器。
模型函数 (
model_fn) 可以实现您的模型。使用预制估算器与自定义估算器的唯一差别在于: - 使用预制估算器时,已经有人为您写好了模型函数。
- 而使用自定义估算器,您必须自己编写模型函数。
您的模型函数可以实现多种算法,定义各种隐藏层和指标。像输入函数一样,所有模型函数都必须接受一组标准输入参数,并返回一组标准输出值。输入参数可以利用 Dataset API,模型函数可以利用 Layers API 和 Metrics API。
以预制估算器形式实现鸢尾花:快速温习
在演示如何以自定义估算器形式实现鸢尾花之前,请回想一下,我们在本系列的第 1 部分是如何以预制估算器形式实现鸢尾花的。在第 1 部分,我们为鸢尾花数据集简单地创建了一个完全连接的深度神经网络,方式是将 预制估算器实例化,如下所示:
# Instantiate a deep neural network classifier.
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns, # The input features to our model.
hidden_units=[10, 10], # Two layers, each with 10 neurons.
n_classes=3, # The number of output classes (three Iris species).
model_dir=PATH) # Pathname of directory where checkpoints, etc. are stored.上述代码会创建一个具有下列特征的深度神经网络:
- 特征列的列表。(上面的代码段中未显示特征列的定义。)对于鸢尾花,特征列是四个输入特征的数字表示。
- 两个完全连接的层,每个都有 10 个神经元。完全连接的层(也称为密集层)连接到后继层中的每个神经元。
- 输出层包括一个三元素列表。该列表中的元素都是浮点值;这些值的总和必须为 1.0(这是一种概率分布)。
- 将用于存储训练的模型和各个检查点的目录 (
PATH)。
图 2 显示了鸢尾花模型的输入层、隐藏层和输出层。为清楚起见,我们在每个隐藏层中只绘制了 4 个节点。

图 2.我们的鸢尾花实现包含四个特征、两个隐藏层和一个 logits 输出层。
下面我们来看看如何使用自定义估算器解决同样的鸢尾花问题。
输入函数
估算器框架的一项最大优势在于,不需要改变数据管道就可以试验不同的算法。因此,我们将重复利用第 1 部分中的大量输入函数:
def my_input_fn(file_path, repeat_count=1, shuffle_count=1):
def decode_csv(line):
parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]])
label = parsed_line[-1] # Last element is the label
del parsed_line[-1] # Delete last element
features = parsed_line # Everything but last elements are the features
d = dict(zip(feature_names, features)), label
return d
dataset = (tf.data.TextLineDataset(file_path) # Read text file
.skip(1) # Skip header row
.map(decode_csv, num_parallel_calls=4) # Decode each line
.cache() # Warning: Caches entire dataset, can cause out of memory
.shuffle(shuffle_count) # Randomize elems (1 == no operation)
.repeat(repeat_count) # Repeats dataset this # times
.batch(32)
.prefetch(1) # Make sure you always have 1 batch ready to serve
)
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels请注意,输入函数会返回下面两个值:
batch_features,是一本字典。此字典的键是特征名称,值是特征的值。batch_labels,是一个用于批处理的标签值列表。
如需了解有关输入函数的完整详细信息,请参阅第 1 部分。
创建特征列
如本系列第 2 部分详述,您必须定义模型的特征列,以便指定每个特征的表示形式。无论是使用预制估算器还是自定义估算器,特征列的定义方式都一样。例如,以下代码会创建表示鸢尾花数据集中四个特征(全数值)的特征列:
feature_columns = [
tf.feature_column.numeric_column(feature_names[0]),
tf.feature_column.numeric_column(feature_names[1]),
tf.feature_column.numeric_column(feature_names[2]),
tf.feature_column.numeric_column(feature_names[3])
]编写模型函数
我们现在准备为自定义估算器编写
model_fn。首先是函数声明: def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode): # Instance of tf.estimator.ModeKeys, see below前两个参数是从输入函数返回的特征和标签;也就是说,
features 和 labels 是模型要使用的数据句柄。mode 参数指明调用方是在请求训练、预测还是评估。 要实现典型的模型函数,必须执行以下操作:
- 定义模型的层。
- 指定模型在三种不同模式下的行为。
定义模型的层
如果您的自定义估算器生成深度神经网络,那么您必须定义以下三个层:
- 一个输入层
- 一个或多个隐藏层
- 一个输出层
使用 Layers API (
tf.layers) 定义隐藏层和输出层。 如果自定义估算器生成线性模型,则只需生成一个层,我们将在下一部分介绍。
定义输入层
调用
tf.feature_column.input_layer,为深度神经网络定义输入层。例如: # Create the layer of input
input_layer = tf.feature_column.input_layer(features, feature_columns)上面一行代码会创建输入层,通过输入函数读取
features,并通过之前定义的 feature_columns 对它们进行筛选。要详细了解通过特征列表示数据的各种方法,请参阅第 2 部分。 要为线性模型创建输入层,请调用
tf.feature_column.linear_model,而不是 tf.feature_column.input_layer。由于线性模型没有隐藏层,因此,从
tf.feature_column.linear_model 返回的值将用作输入层和输出层。也就是说,此函数返回的值 是 预测。 建立隐藏层
如果要创建深度神经网络,您必须定义一个或多个隐藏层。Layers API 具有丰富的函数,可以定义所有类型的隐藏层,包括卷积层、池化层和退出层。对于鸢尾花,我们只需调用两次
tf.layers.Dense 来创建两个密集的隐藏层,每个层有 10 个神经元。“密集”的意思是第一个隐藏层中的每个神经元都连接到第二个隐藏层中的每个神经元。下面是相关代码:
# Definition of hidden layer: h1
# (Dense returns a Callable so we can provide input_layer as argument to it)
h1 = tf.layers.Dense(10, activation=tf.nn.relu)(input_layer)
# Definition of hidden layer: h2
# (Dense returns a Callable so we can provide h1 as argument to it)
h2 = tf.layers.Dense(10, activation=tf.nn.relu)(h1)tf.layers.Dense 的 inputs 参数标识 前置 层。位于 h1 之前的层是输入层。 
图 3.输入层馈入隐藏层 1。
h2 的前置层是 h1。因此,这些层的串联看起来就像下图所示: 
图 4.隐藏层 1 馈入隐藏层 2。
tf.layers.Dense 的第一个参数定义其输出神经元数量 - 这里是 10。 activation 参数定义激活函数 - 这里是 Relu。
请注意,
tf.layers.Dense 提供许多其他功能,包括设置多个正则化参数。但为简便起见,我们简单地接受其他参数的默认值。另外,在查看 tf.layers 时,您可能会发现小写版本(如 tf.layers.dense)。作为一般规则,您应使用以大写字母开头的类版本 (tf.layers.Dense)。 输出层
我们再次调用
tf.layers.Dense 来定义输出层: # Output 'logits' layer is three numbers = probability distribution
# (Dense returns a Callable so we can provide h2 as argument to it)
logits = tf.layers.Dense(3)(h2)请注意,输出层从
h2 接收其输入。因此,全部层现在按照下面所示方式连接: 
图 5.隐藏层 2 馈入输出层。
在定义输出层时,
units 参数指定可能的输出值数量。因此,将 units 设置为 3 后,tf.layers.Dense 函数会建立一个三元素的
logits 矢量。logits 矢量的每个单元都包含鸢尾花分别为山鸢尾、变色鸢尾或维吉尼亚鸢尾的可能性。 由于输出层是最后一个层,因此,对
tf.layers.Dense 的调用会忽略可选的 activation 参数。 实现训练、评估和预测
创建模型函数的最后一步是编写实现预测、评估和训练的分支代码。
当有人调用估算器的
train、evaluate 或 predict 函数时,就会调用模型函数。回想一下,模型函数的特征如下所示: def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode): # Instance of tf.estimator.ModeKeys, see below注意第三个参数
mode。如下表所示,当有人调用 train、evaluate 或 predict 时,估算器框架将调用模型函数,其 mode
parameter 设置如下: 表 2.模式的值。
| 调用方调用自定义估算器函数... | 估算器框架调用模型函数,其 mode 参数设置为... |
train() |
ModeKeys.TRAIN |
evaluate() |
ModeKeys.EVAL |
predict() |
ModeKeys.PREDICT |
例如,假设您实例化自定义估算器来生成一个名为
classifier 的对象。然后进行以下调用(暂时不用管 my_input_fn 的参数): classifier.train(
input_fn=lambda: my_input_fn(FILE_TRAIN, repeat_count=500, shuffle_count=256))估算器框架随后会调用
model 函数,并将 mode 设置为 ModeKeys.TRAIN。 模型函数必须提供代码来处理所有三个
mode 值。对于每个模式值,您的代码都必须返回 tf.estimator.EstimatorSpec 的实例,其中包含调用方需要的信息。我们来检查每个模式。 PREDICT
使用
mode == ModeKeys.PREDICT 调用 model_fn 时,模型函数必须返回包含以下信息的 tf.estimator.EstimatorSpec: - 模式,即
tf.estimator.ModeKeys.PREDICT - 预测
模型在进行预测之前必须经过训练。训练后的模型存储在您实例化估算器时建立的磁盘目录中。
在我们这个示例中,用于生成预测的代码如下所示:
# class_ids will be the model prediction for the class (Iris flower type)
# The output node with the highest value is our prediction
predictions = { 'class_ids': tf.argmax(input=logits, axis=1) }
# Return our prediction
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions=predictions)代码块出奇地简单 - 代码行就像长管尽头的一个桶,只等预测落入。毕竟,估算器已经完成了进行预测的所有繁重工作:
- 输入函数为模型函数提供用于推断的数据(特征值)。
- 模型函数将这些特征值转变成特征列。
- 模型函数通过之前训练的模型运行这些特征列。
输出层是
logits 矢量,分别包含三个作为输入花的鸢尾花种类的值。tf.argmax 函数会选择 logits 矢量值 最大 的鸢尾花种类。 请注意,最大的值已分配给名为
class_ids 的字典键。我们通过
tf.estimator.EstimatorSpec 的预测参数返回该字典。调用方然后可以检查传回估算器 predict 函数的字典来检索预测。 EVAL
使用
mode == ModeKeys.EVAL 调用 model_fn 时,模型函数必须评估模型,返回损耗甚至一个或多个指标。 我们可以调用
tf.losses.sparse_softmax_cross_entropy 来计算损耗。下面是完整的代码: # To calculate the loss, we need to convert our labels
# Our input labels have shape: [batch_size, 1]
labels = tf.squeeze(labels, 1) # Convert to shape [batch_size]
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)现在我们把注意力转向指标。虽然返回指标是可选的,但大多数自定义估算器都会至少返回一个指标。TensorFlow 提供 Metrics API (
tf.metrics) 来计算不同类型的指标。为简便起见,我们只返回准确率。tf.metrics.accuracy 将预测与“真实标签”(即输入函数提供的标签)进行对比。tf.metrics.accuracy 函数要求标签和预测具有相同的形状(我们前面做过)。下面调用 tf.metrics.accuracy:
# Calculate the accuracy between the true labels, and our predictions
accuracy = tf.metrics.accuracy(labels, predictions['class_ids'])使用
mode == ModeKeys.EVAL 调用模型时,模型函数将返回包含以下信息的 tf.estimator.EstimatorSpec: mode,即tf.estimator.ModeKeys.EVAL- 模型的损耗
- 字典中通常包含的一个或多个指标。
因此,我们将创建一个包含唯一指标 (
my_accuracy) 的字典。如果我们计算了其他指标,应该已经将它们作为附加的键值对添加到同一字典中。然后,我们在 tf.estimator.EstimatorSpec 的 eval_metric_ops 参数中传递该字典。下面是代码块: # Return our loss (which is used to evaluate our model)
# Set the TensorBoard scalar my_accurace to the accuracy
# Obs: This function only sets value during mode == ModeKeys.EVAL
# To set values during training, see tf.summary.scalar
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode,
loss=loss,
eval_metric_ops={'my_accuracy': accuracy})TRAIN
使用
mode == ModeKeys.TRAIN 调用 model_fn 时,模型函数必须训练模型。 我们必须先实例化优化程序对象。我们从以下代码块中选择了 Adagrad (
tf.train.AdagradOptimizer),只是因为我们模仿的
DNNClassifier 也使用 Adagrad。tf.train 软件包提供了许多其他优化器 - 尽管去试验。
然后,我们通过在优化器上建立目标来训练模型,尽可能减小其
loss。为建立该目标,我们将调用 minimize 函数。 在下面的代码中,可选的
global_step 参数指定 TensorFlow
用来统计已经处理的批处理数量的变量。将 global_step 设置为 tf.train.get_global_step 就能完美地运行。此外,我们将调用 tf.summary.scalar,在训练期间向
TensorBoard 报告 my_accuracy。对于这两条说明,请参阅下面的 TensorBoard 部分查看更多说明。 optimizer = tf.train.AdagradOptimizer(0.05)
train_op = optimizer.minimize(
loss,
global_step=tf.train.get_global_step())
# Set the TensorBoard scalar my_accuracy to the accuracy
tf.summary.scalar('my_accuracy', accuracy[1])使用
mode == ModeKeys.TRAIN 调用模型时,模型函数必须返回包含以下信息的 tf.estimator.EstimatorSpec: - 模式,即
tf.estimator.ModeKeys.TRAIN - 损耗
- 训练操作的结果
下面是代码:
# Return training operations: loss and train_op
return tf.estimator.EstimatorSpec(
mode,
loss=loss,
train_op=train_op)模型函数现已完成!
自定义估算器
在创建新的自定义估算器之后,您肯定希望用一下。首先
通过
Estimator 基类实例化自定义估算器,如下所示: classifier = tf.estimator.Estimator(
model_fn=my_model_fn,
model_dir=PATH) # Path to where checkpoints etc are stored使用我们的估算器训练、评估和预测的其余代码跟第 1 部分介绍的预制
DNNClassifier 一样。例如,以下代码行将触发模型训练:
classifier.train(
input_fn=lambda: my_input_fn(FILE_TRAIN, repeat_count=500, shuffle_count=256))TensorBoard
像第 1 部分一样,我们可以在 TensorBoard 中查看训练结果。要查看此报告,请按照下面所示从您的命令行启动 TensorBoard:
# Replace PATH with the actual path passed as model_dir
tensorboard --logdir=PATH 然后浏览至以下网址:
localhost:6006 所有预制估算器都会自动将大量信息记录到 TensorBoard。但使用自定义估算器时,TensorBoard 只提供一个默认日志(损耗图表),以及我们明确指示 TensorBoard 记录的信息。因此,TensorBoard 会从自定义估算器生成以下图表:

图 6.TensorBoard 显示三个图表。
简言之,这三个图表可以告诉您下列信息:
- global_step/sec:一种性能指标,显示我们在特定批处理(x 轴)中每秒处理了多少批处理(y 轴,梯度更新)。要查看此报告,您需要提供
global_step(像使用tf.train.get_global_step()时一样)。还需要运行时间足够长的训练,我们要求估算器在我们调用其训练函数时训练 500 次循环:- loss:报告的损耗。实际损耗值(y 轴)并没有多大意义。图表的形状很重要。
- my_accuracy:我们调用以下函数时记录的准确率:
eval_metric_ops={'my_accuracy': accuracy}),在EVAL期间(返回我们的EstimatorSpec时)tf.summary.scalar('my_accuracy', accuracy[1]),在TRAIN期间
注意
my_accuracy 和 loss 图表中的以下信息: - 橙色线表示
TRAIN。 - 蓝色点代表
EVAL。
在
TRAIN 期间,处理批处理时会持续记录橙色值,这正是图表横跨 x 轴范围的原因。相反,EVAL 在处理所有评估步骤时只生成一个值。 根据图 7 中的提示,您可以查看并选择性地停用/启用左侧的训练和评估报告。(图 7 显示我们保留了两者的报告。)

图 7.启用或停用报告。
要查看橙色图表,您必须指定一个全局步骤。结合
global_steps/sec 报告,这成为随时注册全局步骤的最佳做法,只需将 tf.train.get_global_step() 作为参数传送到
optimizer.minimize 调用即可。 总结
虽然预制估算器可以成为一种快速创建新模型的有效方式,但您经常需要自定义估算器具备的更大灵活性。幸运的是,预制和自定义估算器采用相同的编程模型。唯一的实际差异是您必须为自定义估算器编写模型函数,其他一切都相同!
如需了解更多详情,请参阅下面的资源:
- 此博文的完整源代码。
- MNIST 的正式 TensorFlow 实现,使用自定义估算器。此模型也是一个示例,在这个模型中,我们将原始像素用作数值,而不使用特征列(以及
input_layer)。 - TensorFlow 官方模型库,其中可能包含更具引导意义并使用自定义估算器的示例。
- TensorFlow Dev Summit 中的 TensorBoard 视频,以有趣的方式介绍 TensorBoard,很有教育意义。
祝大家 TensorFlow 编码愉快,我们下次再见!
