

今天我们来看一下Bing搜索广告2016年公布的算法。原文在这里www.kdd.org/kdd2016/pap… 。这类神经网络不同于我们之前看的YouTube的推荐算法,侧重点是完全不一样的。
背景知识
当我们在尝试去让一个机器学习的模型变的更好的时候,我们常常会手动的给特征去做一些排列组合。这些特征排列组合理论上来说模型是可以自己理解出来的,但是常常由于模型大小,或者由于模型本身的特性,而造成拟合不了特征数据的分布。这个时候手动的去做一些特征的排列组合是可以让模型变得更好。在这个论文里,微软的人提出了让深度学习的模型自己去做特征的排列组合,他们叫这个模型Deep Crossing Model。
更严格的来说,论文里提到的Deep Crossing Model可以那各种各样的特征作为输入,比如文字,类别,ID,或者数字类型的特征。这类特征在Bing Ads所在的搜索广告领域都是不可或缺的。在讲具体特征和模型之前,我们先介绍一下搜索广告行业相关的概念:
Query: A text string a user types into the search box
Keyword: A text string related to a product, specified by an advertiser to match a user query
Match type: An option given to the advertiser on how closely the keyword should be matched by a user query, usually one of four kinds: exact, phrase, broad and contextual
每一个广告都会对一个、一组用户搜索的关键字去竞价,那么这个时候这个广告所在意的关键字跟用户具体搜索的请求,以及这些关键字跟用户请求对应的具体方式对这个模型来说就非常重要。这类特征,有文字,也有类别。
Title: The title of a sponsored advertisement (referred to as “an ad”hereafter), specified by an advertiser to capture a user’s attention
Landing page: A product’s web site a user reaches when the corresponding ad is clicked by a user
广告本身是有文案和具体的到达页面,这些内容都会被作为‘描述广告内在’的特征放到模型里面。这类特征大多是文字。
每个广告在运作的时候还会有观看次数,点击次数以及点击率,这类特征主要是基于ID的特征(广告、用户的ID)以及数字类特征放到模型里面的。
特征
上面描述的特征都是要放到模型里面的,那么每个特征具体是怎么输入到模型里面的呢?总的来说,每个特征都是一个向量。
- 文字特征被分解成tri-letter-gram,就是三个字母对应一个向量,在一个49292维度的空间里面(我看到这里也没看懂unicode要怎么弄,可能CJK类文字的收入太少?)。
- 类别特征变成one-hot,就是假设这个类别特征有5个不同的类别,那么类别一就是[1,0,0,0,0],类别4就是[0,0,0,1,0]。one-hot就是说永远只有一个1是存在、“热”的。
模型
Deep Crossing模型分四个部分:Embedding, Stacking, The Residual Unit 跟 Scoring layer。模型的loss function是log loss。
Embedding
这一层主要是负责下面这个函数
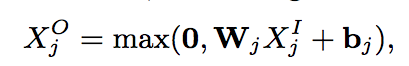
j是这一组特征的标志,我们可以先只看一组特征,所以可以吧j无视掉。
n在这里没有写明,是这个特征的维度。比如之前讲文字特征维度是49292。
X是特征的输入,是一个n维的向量。
M是一个m*n维度的向量。你可以定义m,当m比较小的时候你就把X降维了。这里可以把它理解成一个矩阵分解的行为。
b是一个m维的向量(文章里面说b是一个n维的向量,但是W*X出来应该是m维的,所以原文应该是写错了,如果我错了请指正)。
最后,用一个ReLU让W*X+b结果的向量里面每一个都至少是0。
这一层你可以把它笼统的理解为是降维,这样好输入到下一层Stacking Layer
Stacking Layer
这一层是把所有的输入stack/concatenate起来,
低纬度的特征是不用通过降维,直接concatenate到stacking layer里面来的。
The Residual Unit
这个其实不是一个层,而是在stacking layer和Embedding的输出上面的‘复式’ReLU‘
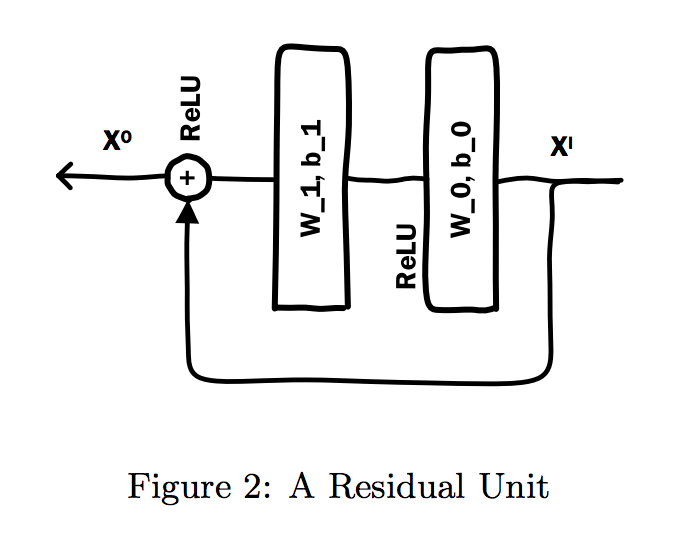
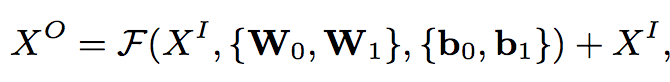
这里的W_0跟b_0应该是之前Embedding那一层的W跟b,在这个输出之上再来一层ReLU,这样的话函数F就是在拟合 X_O - X_I。
Scoring layer
所有的输出最后连到一个fully connected layer到一个Sigmoid,最后输出一个预测,这里就是预测广告的点击率啦。
效果
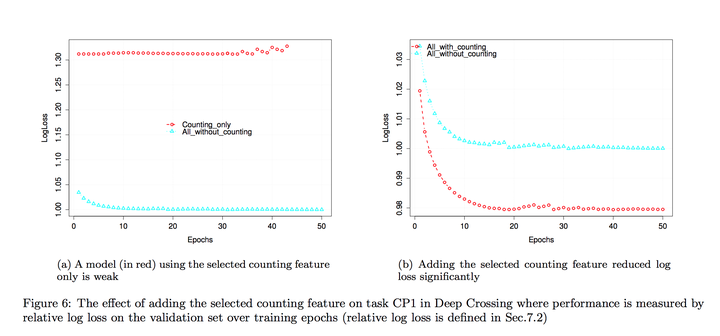
左图是只用dense feature跟只用sparse之间的区别,右边是只用sparse跟sparse+dense的区别。可以看出来这个模型是有结合dense跟sparse的功能。
自己的总结
这个模型本身跟 YouTube 2016年公布的基于深度学习的推荐算法 没有特别大的本质差别, 主要差别就是ReLU,剩下都是矩阵分解+concatenation,YouTube那个模型还分两个,各种设计的概念,还稍微复杂一点,Deep Crossing这个模型和需要理解这个模型的概念更简单,所以建议大家先读这个再读YouTube那个文章。再贴一次,Deep Crossing原文在这里 www.kdd.org/kdd2016/pap… 。
