

对于我这种学渣是不可能靠知识玩转头脑王者,那么程序员应该如何玩呢👿?
我们首先了解下小程序头脑王者玩法
每局比赛两人参与,五道题,在不用道具的情况下,答对一道题最多可得200分,答得越慢分越少,答错不得分。
有十秒时间限制,如果在第一秒答对,得200分,如果用了一秒(即还剩9秒),则得180分,剩8秒则得160分,以此类推。
最后一道题得分双倍,即400分、380分、360分……这样理论上最高可得1200分。

分析玩法后,我们需要分析处理下我们的实现流程
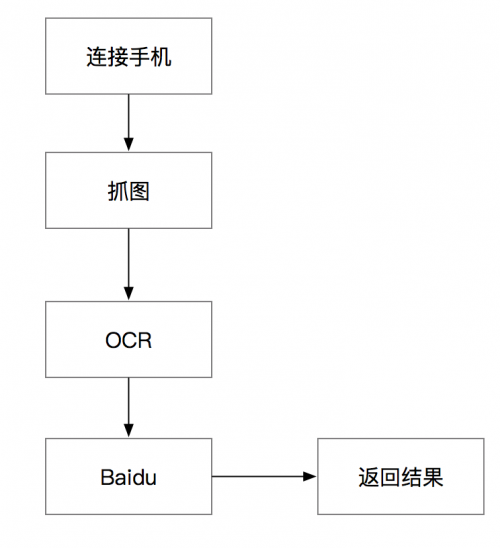
针对流程我们需要的东西
- 打开电脑,接上USB,确定连接📱即可
-
截图,参考微信跳一跳外挂所使用到 WDA,安装过程详见 testerhome.com/topics/1046…
WDA 本是 Facebook 开发的一套 iOS 测试框架,被用来做辅助真是💦了
-
Ocr
-
本地ocr服务
使用基于本地tesserocr的,尝试了一下,不训练,识别出来的效果太差了
-
在线的ocr服务
百度 好像一天只有500次?
腾讯
-
-
百度(万能的🤷♂️)
上代码
- 打开手机进入答题界面,⌛️用户的按键输入,自动截图
import wda
import tx_api2 as tx_api
c = wda.Client()
def screenshot():
print("开始截图......")
pic_name = '1.png'
c.screenshot(pic_name)
tx_api.analysis(pic_name)
while True:
input("****** ⌛️ ⌛️ ⌛️ *******")
screenshot()- 切问题和答案的矩形
def cut_pic(pic_path, left, upper, right, lower, desc):
print(desc)
im = Image.open(pic_path)
region = im.crop((left, upper, right, lower)) # iPhone 7
img_byte_arr = io.BytesIO()
region.save(img_byte_arr, format='PNG')
image_data = img_byte_arr.getvalue()
image_data_base64 = base64.b64encode(image_data).decode('ascii')
return image_data_base64- ocr识别(这里为了提高速度,采用多线程)
def ocr(pic_path, left, upper, right, lower, desc):
image_data_base64 = cut_pic(pic_path, left, upper, right, lower, desc)
return youtu.generalocr(image_data_base64)
with futures.ThreadPoolExecutor(max_workers=2) as executor:
future_ocr_dict['question'] = executor.submit(ocr, pic_path, 75, 295, 700,
500, '🚕 切问题矩形')
future_ocr_dict['question_selection'] = executor.submit(ocr, pic_path, 130,
600, 620, 1200,'🚕 切答案矩形')- 百度🔍(用问题➕答案获取匹配最多的记录,同样多线程拯救⌚️)
def match_count(keyword):
path = "http://www.baidu.com/s?tn=ichuner&lm=-1&word={0}&rn=1".format(
parse.quote(keyword))
res = request.urlopen(path)
read_line = ''
search_str = "百度为您找到相关结果约"
for line in res.readlines():
line_str = line.decode('utf-8')
if (search_str in line_str):
start = line_str.index(search_str) + 11
line_str = line_str[start:]
end = line_str.index("个")
read_line = line_str[0:end]
break
read_line = read_line.replace(",", "")
return int(read_line)
with futures.ThreadPoolExecutor(max_workers=len(items)) as executor:
for item in items:
search_str = question_str + item['itemstring']
print("🚥 :{0}".format(search_str))
future_to_search[item['itemstring']] = executor.submit(match_count, search_str)- 获取结果
for future_key in future_to_search:
cache_search[future_key] = future_to_search[future_key].result()
print("match<{0}>:\033[1;31;40m{1}\33[0m".format(question_str + future_key,
str(cache_search[future_key])))
print('并发🔍 执行完成')
cache_search = sorted(cache_search.items(), key=lambda d: d[1], reverse=True)
if(len(cache_search) > 0):
print(" 🎉 🎉 🎉 最佳答案:\033[1;31;40m{}\33[0m".format(
next(iter(cache_search))[0]))
end_time = time.time()
print("用时{0}s".format((end_time - start_time)))结果 🎉 🎉 🎉
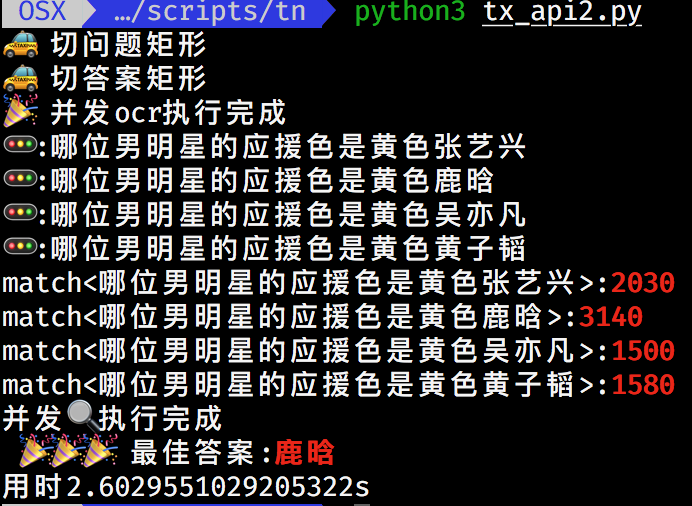
结尾:经过大部分的测试很多答案是❌的。可能还是需要使用elasticsearch存储题库,达到精确匹配。好吧!我还是玩不了这个🎮,老老实实搬砖去了,如果有更好的想法可以留言。
