

Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
•是CDH平台首选的PB级大数据实时查询分析引擎
1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
2、无需转换为MR,直接读取HDFS数据
3、C++编写,LLVM统一编译运行
4、兼容HiveSQL
5、具有数据仓库的特性,
6、可对hive数据直接做数据分析
7、支持列式存储
8、支持Data Local
9、支持JDBC/ODBC远程访问
1、对内存依赖大
2、C++编写 开源
3、共生完全依赖hive一挂解千愁
4、实践过程中分区超过1w 性能严重下下降
5、稳定性不如hive
Statestore Daemon
•实例*1-statestored
–负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
–负责query的调度
Catalog Daemon
•实例*1-catalogd
–分发表的元数据信息到各个impalad中
–接收来自statestore的所有请求
Impala Daemon(具有数据本地化的特性所以放在DataNode上)
•实例*N–impalad
–接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
–子节点上的守护进程,负责向statestore保持通信,汇报工作
ImpalaSql
默认方式创建表:
create external table tab_p1( id int,name string)
location ‘/user/xxx.txt’
指定存储方式:
create external table tab_p2 like parquet_tab ‘/user/xxx/xxx/1.dat’
partition (year int , month tinyint, day tinyint)
location ‘/user/xxx/xxx’
stored as parquet;
视图:
–创建视图:
create view v1 as select count(id) as total from tab_3 ;
–查询视图:
select * from v1;
–查看视图定义:
describe formatted v1
注意: –1)不能向impala的视图进行插入操作
–2)insert 表可以来自视图
Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
•步骤1:创建hbase 表,向表中添加数据
create 'test_info', 'info'
put 'test_info','1','info:name','zhangsan'
put 'test_info','2','info:name','lisi'
•步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string )
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES ("hbase.table.name" = "test_info");
•步骤3:刷新Impala表
invalidate metadata
impala性能优化
执行计划:查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的详细方案。命令:explain sql、profile
•是CDH平台首选的PB级大数据实时查询分析引擎
1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
2、无需转换为MR,直接读取HDFS数据
3、C++编写,LLVM统一编译运行
4、兼容HiveSQL
5、具有数据仓库的特性,
6、可对hive数据直接做数据分析
7、支持列式存储
8、支持Data Local
9、支持JDBC/ODBC远程访问
1、对内存依赖大
2、C++编写 开源
3、共生完全依赖hive一挂解千愁
4、实践过程中分区超过1w 性能严重下下降
5、稳定性不如hive
Statestore Daemon
•实例*1-statestored
–负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
–负责query的调度
Catalog Daemon
•实例*1-catalogd
–分发表的元数据信息到各个impalad中
–接收来自statestore的所有请求
Impala Daemon(具有数据本地化的特性所以放在DataNode上)
•实例*N–impalad
–接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
–子节点上的守护进程,负责向statestore保持通信,汇报工作
ImpalaSql
默认方式创建表:
create external table tab_p1( id int,name string)
location ‘/user/xxx.txt’
指定存储方式:
create external table tab_p2 like parquet_tab ‘/user/xxx/xxx/1.dat’
partition (year int , month tinyint, day tinyint)
location ‘/user/xxx/xxx’
stored as parquet;
视图:
–创建视图:
create view v1 as select count(id) as total from tab_3 ;
–查询视图:
select * from v1;
–查看视图定义:
describe formatted v1
注意: –1)不能向impala的视图进行插入操作
–2)insert 表可以来自视图
Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
•步骤1:创建hbase 表,向表中添加数据
create 'test_info', 'info'
put 'test_info','1','info:name','zhangsan'
put 'test_info','2','info:name','lisi'
•步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string )
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES ("hbase.table.name" = "test_info");
•步骤3:刷新Impala表
invalidate metadata
impala性能优化
执行计划:查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的详细方案。命令:explain sql、profile
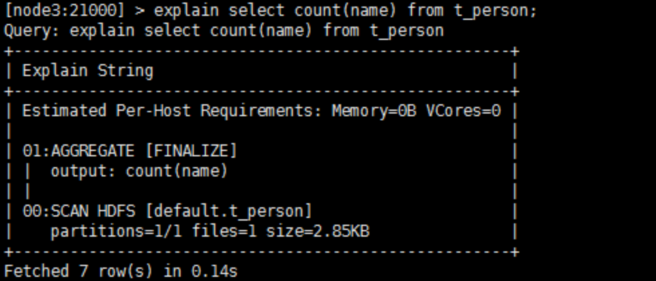
·1、SQL优化,使用之前调用执行计划
•2、选择合适的文件格式进行存储
•3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表,将小文件存放到中间表然后写入到要执行的表里A—>V—>B)
•4、使用合适的分区技术,根据分区粒度测算
•5、使用compute stats进行表信息搜集
•6、网络io的优化:
–a.避免把整个数据发送到客户端
–b.尽可能的做条件过滤
–c.使用limit字句
–d.输出文件时,避免使用美化输出
•7、使用profile输出底层信息计划,在做相应环境优化
谢谢阅读,更多大数据相关技术请看上海尚学堂大数据。
