

某年某月某日,糖葫芦同学在掘金app上看了几篇文章,偶然看到了一篇熟悉的词LRU算法,脑海里就想这不是经常说的嘛,就那么回事,当天晚上睡觉,LRU算法是啥来着,好像是什么最近最少使用的,白天在地铁上看的文章也不少,但是到晚上想想好像啥也没记住,就记得LRU算法,我发现人大多数是这样的啊,对于自己熟悉的部分呢还能记着点,不熟悉或者不会的可能真的是看过就忘啊~既然这样还不如先把熟悉的弄明白。
第二天来到公司,我觉着还是有必要看一下这个LRU的源码,到底是怎么回事,嗯,糖葫芦同学刷刷得看,下面我们将进入正题,请戴眼镜的同学把眼镜擦一擦,哈哈哈
First
先看源码,再用具体的demo加以验证,我们先看一下这个LruCache这个类的大致结构和方法,如下图所示:
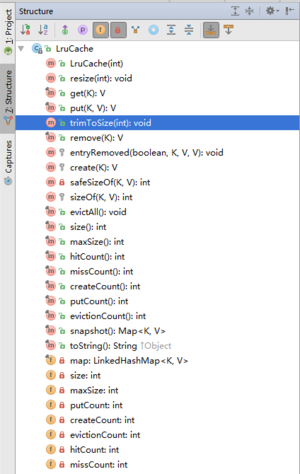
这又是 get(K),put(K,V), remove(K) 的方法的 给人的感觉就像是一个Map的集合嘛,又有Key ,又有value 的,再看下具体的代码:
public class LruCache<K, V> {
private final LinkedHashMap<K, V> map;
/** Size of this cache in units. Not necessarily the number of elements. */
private int size;
private int maxSize;
private int putCount;
private int createCount;
private int evictionCount;
private int hitCount;
private int missCount;
/**
* @param maxSize for caches that do not override {@link #sizeOf}, this is
* the maximum number of entries in the cache. For all other caches,
* this is the maximum sum of the sizes of the entries in this cache.
*/
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
看到开头,我们就明白了,哦原来这个LruCache类中维护一个LinkedHashMap的一个集合,缓存我们这个对象,而且构造方法里需要我们传入一个maxSize的一个值,根据上面的注释我们就明白了这个就是我们LruCache缓存对象的最大数目。
有什么用呢?
根据惯性思维,我们可以认为,在put新的缓存对象的时候,根据我们设定的最大值remove集合里的某些缓存对象,进而添加新的缓存对象。
Second
根据我们的分析,我们有必要去看一下这个put方法的源码:
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
代码量也不是特别多,我们看下这个,在这个synchronized同步代码块里,我们看到这个 size,是对put进来缓存对象个数的累加,然后调用集合的map.put方法,返回一个对象 previous ,就是判断这个集合中是否添加了这个缓存对象,如果不为null,就对size减回去。
最后又调用一个 trimToSize(maxSize)方法,上面都是对添加一些逻辑的处理,那么不可能无限制添加啊,肯定有移除操作,那么我们推测这个逻辑可能在这个trimToSize(maxSize) 里处理。
源码如下:
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//只要当前size<= maxSize 就结束循环
if (size <= maxSize || map.isEmpty()) {
break;
}
// 获取这个对象,然后从map中移除掉,保证size<=maxSize
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
注释:Remove the eldest entries until the total of remaining entries is at or below the requested size 大概意思是说:清除时间最久的对象直到剩余缓存对象的大小小于设置的大小。没错是我们想找的。
这里说明一下:maxSize就是我们在构造方法里传入的,自己设置的
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
这样LruCache的核心方法 trimToSize方法我们就说完了,接下来我将通过实例再次验证下:
设置场景
假设我们设置maxSize 为2,布局里显示3个imageView,分别代表3张我们要显示的图片,我们添加3张图片,看看会不会显示3张?
xml布局显示如下(代码就不贴了,很简单):
activity代码如下:
public final int MAX_SIZE = 2;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.layout_lru);
ImageView iv1 = (ImageView) findViewById(R.id.iv1);
ImageView iv2 = (ImageView) findViewById(R.id.iv2);
ImageView iv3 = (ImageView) findViewById(R.id.iv3);
Bitmap bitmap1 = BitmapFactory.decodeResource(getResources(),R.drawable.bg);
Bitmap bitmap2 = BitmapFactory.decodeResource(getResources(),R.drawable.header_img);
Bitmap bitmap3 = BitmapFactory.decodeResource(getResources(),R.drawable.ic_launcher);
LruCache<String,Bitmap> lruCache = new LruCache<>(MAX_SIZE);
lruCache.put("1",bitmap1);
lruCache.put("2",bitmap2);
lruCache.put("3",bitmap3);
Bitmap bitmap = lruCache.get("1");
iv1.setImageBitmap(bitmap);
Bitmap b2 = lruCache.get("2");
iv2.setImageBitmap(b2);
Bitmap b3 = lruCache.get("3");
iv3.setImageBitmap(b3);
}
图:



我们可以先尝试分析一下:因为我们设置的MaxSize 是2 ,那么在put第三个Bitmap的时候,在trimToSize方法中,发现这个size是3 ,maxSize 是2,会继续向下执行,不会break,结合下面代码看下
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//第一次循环:此时 size 是3,maxSize 是 2
//第二次循环,此时 size 是 2 ,maxSize 是 2 ,满足条件,break,结束循环
if (size <= maxSize || map.isEmpty()) {
break;
}
//获取最先添加的第一个元素
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
//移除掉第一个缓存对象
map.remove(key);
// size = 2,减去移除的元素
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
这个 safeSizeOf 是调用sizeOf方法。
那么也就是说,我们在put第三个bitmap的时候,LruCache 会自动帮我们移除掉第一个缓存对象,因为第一个最先添加进去,时间也最长,当然后添加的bitmap就是新的,最近的,那么我们推断这个iv1是显示不出图片的,因为被移除掉了,其它剩余两个可以显示,分析就到这里,看下运行结果是不是跟我们分析的一样:
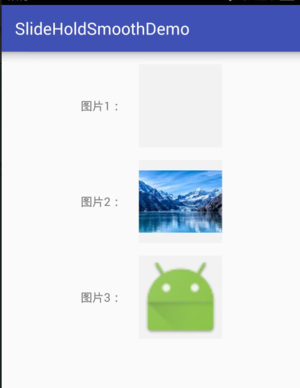
哇!真的跟我们想的一样耶,证明我们想的是对的。这里我们思考一下就是为什么LruCache使用了这个LinkedHashMap,为什么LinkedHashMap的创造方法跟我们平时创建的不太一样,源码是这样的:
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
这里说一下评论里
藏地情人评论是:new LinkedHashMap<K, V>(0, 0.75f, true)这句代码表示,初始容量为零,0.75是加载因子,表示容量达到最大容量的75%的时候会把内存增加一半。最后这个参数至关重要。表示访问元素的排序方式,true表示按照访问顺序排序,false表示按照插入的顺序排序。这个设置为true的时候,如果对一个元素进行了操作(put、get),就会把那个元素放到集合的最后。
确实也是这样的,我们看下LinkedHashMap的源码:
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
里面这个assessOrder 注释里也说的很明白:the ordering mode - <tt>true</tt> for * access-order, <tt>false</tt> for insertion-order -> true 呢就表示会排序,false 就代表按照插入的顺序。默认不传就是 false ,而且我们每次 get(K) put(K,V) 的时候 会根据这个变量调整元素在集合里的位置。而这么做的目的也只有一个:保留最近使用的缓存对象,举个例子说明一下:
我们向这个集合里添加了三种元素
LruCache<String, Bitmap> lruCache = new LruCache<>(MAX_SIZE);(MAX_SIZE=2)
lruCache.put("1", bitmap1);
lruCache.put("2", bitmap2);
lruCache.put("3", bitmap3);
此时它们在集合里的顺序是这样的:

那比如说我们在put 3 元素之前,使用了1元素,就是调用了get("1")方法,我们知道LinkedHashMap就会改变链表里元素的存储顺序,代码是这样的:
lruCache.put("1", bitmap1);
lruCache.put("2", bitmap2);
lruCache.get("1");
lruCache.put("3", bitmap3);
那么此时对应链表里的顺序就是:

当我们再调用显示的时候,循环遍历就会优先把第一个位置的key = "2" 的缓存对象移除掉,保证了最近使用的原则,当然了因为把这个max_size = 2所以在我们执行lruCache.put("3", bitmap3); 时,集合最终会变成这样:
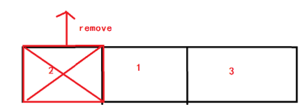
集合里只剩下 1 ,3对应的缓存对象。
至此,LruCache就说完了,如果看完的你有不明白的地方可以留言,一起讨论下~
