

The Problem
Kafka 是一个很流行的消息队列。但是在使用中,我们发现目前的消息队列设计仍然有改进的空间
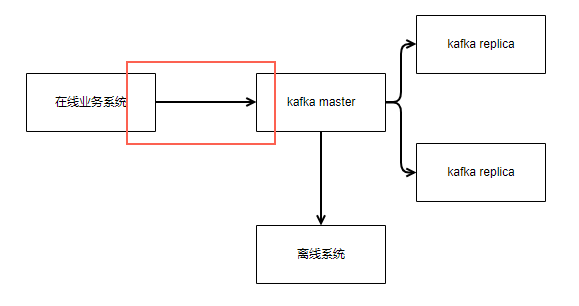
问题出在从在线业务系统往kafka master写入的过程中。kafka给业务系统提出了两难的选择
- 当往kafka master的网络出问题了。或者kafka master自身在选主的时候。要么业务系统选择放弃latency,去等待故障修复
- 要么业务系统选择丢数据。在kafka master不可用的时候把消息给扔掉
这两个选择都很艰难。kafka虽然号称是一个分布式的系统,但是对于单partition的写入仍然是单点的。
解决办法也很简单。就是如果partition 1写入失败,就去写partition 2。不同partition的master可以是不同的节点。或者可以同时写多个partition,一个成功就算成功。代价是放弃了单partition的消息有序性,以及更多的消息冗余而且消费方要做更多的努力去保持幂等。
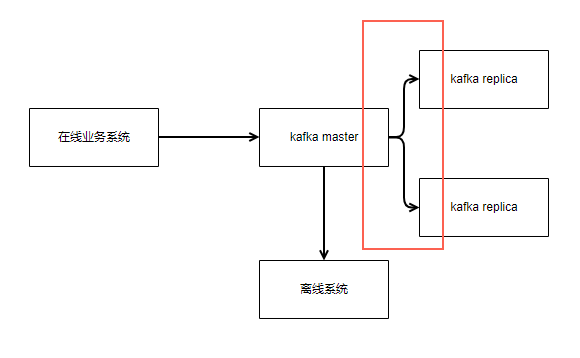
第二个问题在master和replica之间的复制。如果不等任何一个replica复制成功就返回,master挂了就会丢数据。如果需要replica,则显著增加写入的延迟,并且占用更多的资源。
我们来看看是否可以应用 RAID6 的磁盘存储技术到消息队列上。
冲突是可以避免的
我们先来看是否可以把中心化的master节点给干掉?形成这样的部署结构呢?
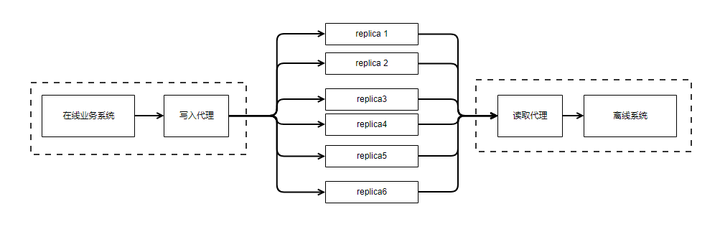
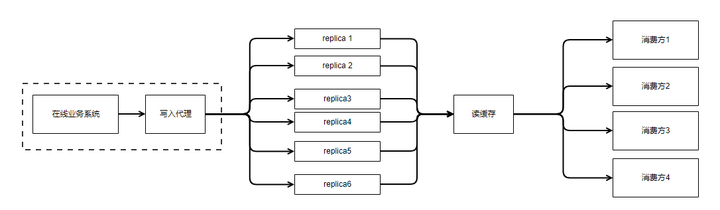
其中写入代理和在线业务系统部署在同一台机器上。当然写入代理也可以是写入的sdk,做为lib嵌入到在线业务系统里。读取代理和离线系统部署在同一台机器上,也可以是读取的sdk,做为lib嵌入到离线系统里。
但是这样会引起一个很严重的问题,offset冲突。kafka通过把给定partition的数据交给唯一的一个master机器来写入来分配这个offset。没有了这个中心化的master,怎么保证多个在线业务系统的机器在写入的时候不会产生offset冲突呢?
这个offset可以使用机器的timestamp的nanosecond。这个选择听起来很糟糕对不对?
- 不要求多个写入机器之间的绝对有序。本来前序的处理就是乱序的负载均衡的。多个机器生产的数据严格排序大部分场景上下没有收益。使用timestamp可以使得总体上来说基本有序。
- nanosecond timestamp分配的offset是为了尽量避免多个producer写入到同一个offset,产生写入冲突。
- nanosecond是十亿分之一秒。也就是说按照大部分业务生产的速度来说,冲突的概率是很小的。
- 如果写入发生了冲突,则offset+一个random的整数,然后重试。
然后问题就是怎样知道写入冲突了
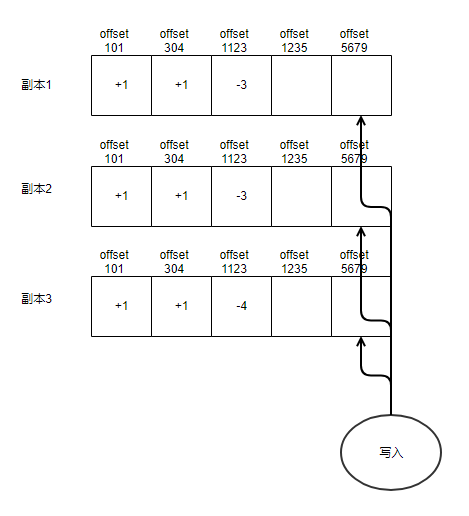
每个replica对应到一个offset就是一个洞。offset与offset之间不需要连续。如果是6个replica,那么每个offset就有6个洞要填。每个repica保证每个洞只能被写入一次。那么多个写入方对于同一个offset就是争抢这6个洞。比如6个写入成功了4份就可以认为写入成功了。因为其他的producer只剩2个洞可以用,它们在这个offset肯定写不成功的。
但是如果一个producer写成功了3个洞,另外一个producer写成功了3个洞,这样怎么办?这种情况就是两个producer都写入失败了。这个offset就算作废了。读取的时候不能只读一个洞就认为读到了值。读取也要读到了4份完全一致的数据才算读取成功了。
这样的好处就是如果是要写6份,写成功了4份就算成功。可以并行地启动6份写入,然后只要等到4份ACK了就可以认为写入成功了,剩下的2份异步处理就可以了。一方面容忍了三分之一机器的故障。同时也容忍了三分之一机器出现写入慢的长尾问题。最大化的利用了不把鸡蛋放到一个篮子里的好处。
但是消费方怎么办?它如何能读取到所有producer写入的数据呢?毕竟producer之间的时钟不是完全同步的。有可能读到了offset10024之后,之前的offset10018又被写入了,这条消息不就被漏掉了吗?解决办法就是延迟读取。只要滞后500ms就可以cover大部分NTP不同步引起的问题了。对于大部分准实时和离线业务来说,500ms的延迟读取不算什么大的问题。另外一个办法就是让读取的窗口重叠。比如之前是[0, 500ms], [500ms, 1000ms],现在就改成[0, 400ms], [200ms, 600ms], [400ms, 800ms],以读取放大的代价来避免漏掉消息。
完全逐条的硬实时大部分情况下就是个伪需求。micro batch is good enough。micro batch比逐条的模型,减少了单个offset产生的contention。
复制是可以避免的
基于多副本复制的另外一个问题是因为复制引起的磁盘,网络和cpu的消耗。如果复制6份写入,4份成功就算成功的话,1份数据就要冗余出5份来做写入。虽然通过并发写入降低了延迟,但是总的写入放大仍然是非常可观的。对于一些价值可能并不高的数据,也许不希望有这么多副本。这个也是kafka设计ISR的模式的出发点,希望尽可能少的减少副本数量,降低成本。
如何既保持6副本,但是减少总的写入放大呢?也许我们可以尝试RAID 6,通过reed solomon编码,把一份消息切成6份,存入6个节点里。只要4份写入成功了,就算写入完了。这样写入放大的成本仅仅是reed solomon编码带来的冗余。而且实际需要同步等待写入的只是6份中的4份而已。
reed solomon编码的问题是编码慢,解码慢。编码可以用SSE进行优化,比如klauspost/reedsolomon
解码慢可以用多个消费方共享同一份拷贝来解决。本质上是一份读缓存。这份缓存不用考虑可用性,随时可以用原始的拷贝重建。
总结
本文构想了一种降低消息队列写入延迟和提高可用性的方法。把kafka的单partition从CP系统变成了AP系统。同时减少了总体的持久存储成本。
