

前言:本文主要结合CMU CS 11-747(Neural Networks for NLP)课程中Attention章节的内容进行讲解。本文主要包括了对如下几块内容的讲解,第一部分介绍Attention思想的提出的背景,第二部分介绍Attention结构在历年论文中的各种变化,第三部分介绍Attention结构的改进,第四部分即总结全文。
本文作者:李军毅,2014级本科生,目前研究方向为机器学习,自然语言处理,来自中国人民大学信息学院社会大数据分析与智能实验室。
备注:本文首发于知乎[RUC智能情报站],如需转载请告知作者并注明本专栏文章地址。
一、Attention思想的由来
1、《Sequence to Sequence Learning with Neural Networks》 2014
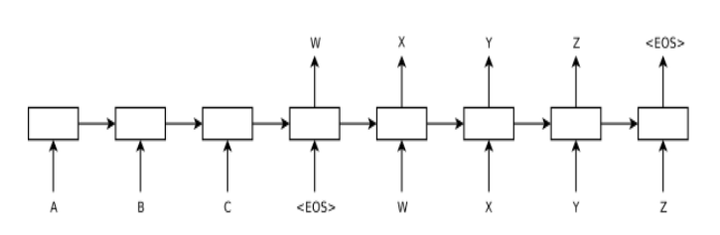
本篇论文最早提出了Encoder-Decoder框架,用于机器翻译领域。本文的亮点一方面在于对 source sentence 做了逆向输入的操作,另一方面相对于以往的论文,它将两个 RNN 结构连接在一起做翻译工作。
2、《Neural Machine Translation by Jointly Learning to Align and Translation》2015
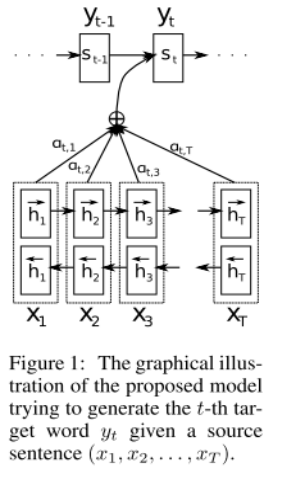
本篇论文首次提出了attention思想。作者认为,在以往的 Encoder-Decoder 框架中,source sentence 的所有信息需要由 Encoder 压缩到一个向量中,这是机器翻译表现无法提高的一个瓶颈,所以作者提出了在翻译时动态搜索 relevant part of source sentence,这就是 attention 。
二、Attention结构的各种变化
1、《Effective Approaches to Attention-based Neural Machine Translation》2015
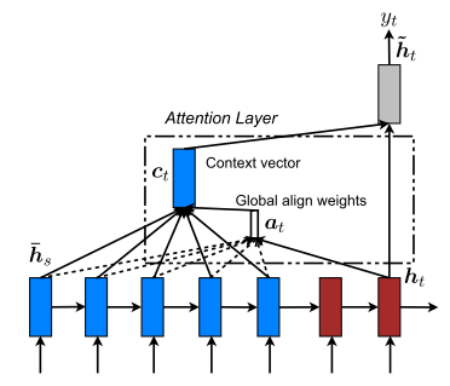
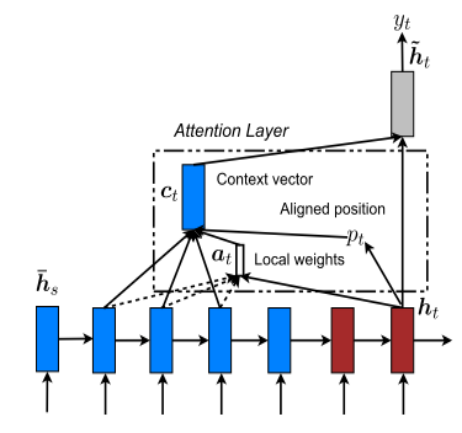
本篇论文提出了两种 attention (global attention 和 local attention),global attention 和最基本的 attention 类似,只是计算过程有所变化;local attention 只关注一个位置的 attention ,类似 one-hot 向量。
2、《Attention is All You Need》2017
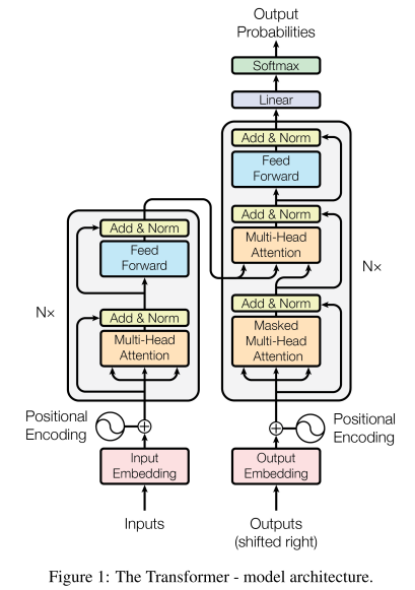
本篇论文将 attention 结构用到极致,在 Encoder 和 Decoder 中只有 attention ,使用了多层 self-attention 结构来做对齐。
3、《Incorporating Discrete Translation Lexicons into Neural Machine Translation》2016
本篇论文主要解决神经机器翻译在翻译过程中遇到的低频词经常出错的问题。作者的解决方法是在计算单词概率时,结合标准的 NMT 概率和 lexicon probability。
4、《Pointer Sentinel Mixture Models》2016
本篇论文主要是在计算单词概率时,对 Pointer Network 的概率和 RNN softmax 的概率做了一个线性结合。
5、《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》2015
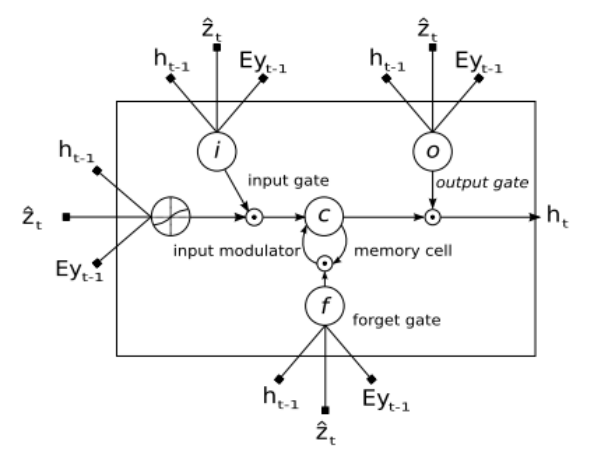
本篇论文是基于 attention 结构来生成描述图片内容的文字。主要思想是将 CNN 所提取的全局特征或者局部特征结合到 attention 的计算过程中,从而指导描述的生成。
6、《Listen, Attend and Spell》2015
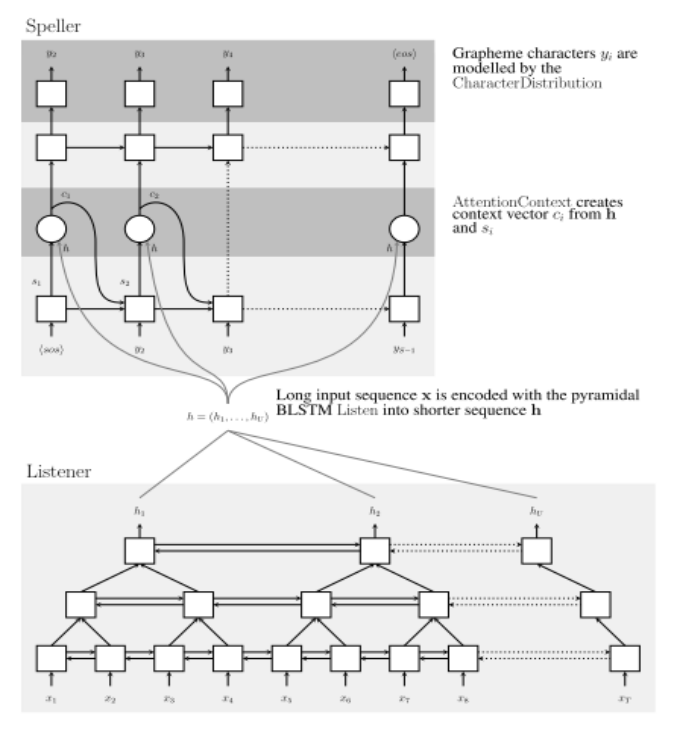
本篇论文构建了一个 LAS 网络,在于把演讲发言转化为文字形式。
7、《Hierarchical Attention Networks for Document Classification》2016
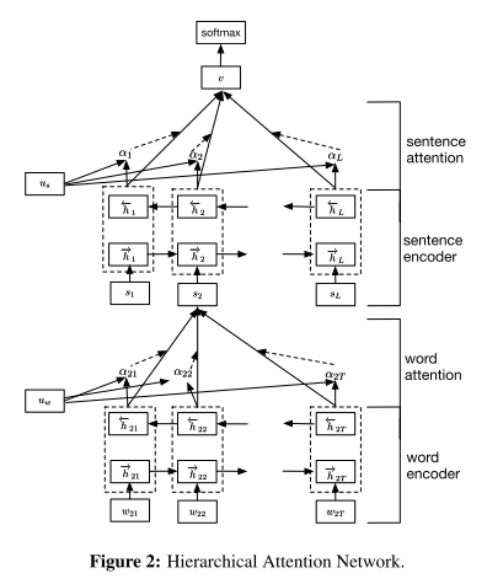
本篇论文分别构建了 word-level 和 sentence-level 的 attention,完成对文本分类的工作。
8、《Multi-Source Neural Translation》2015
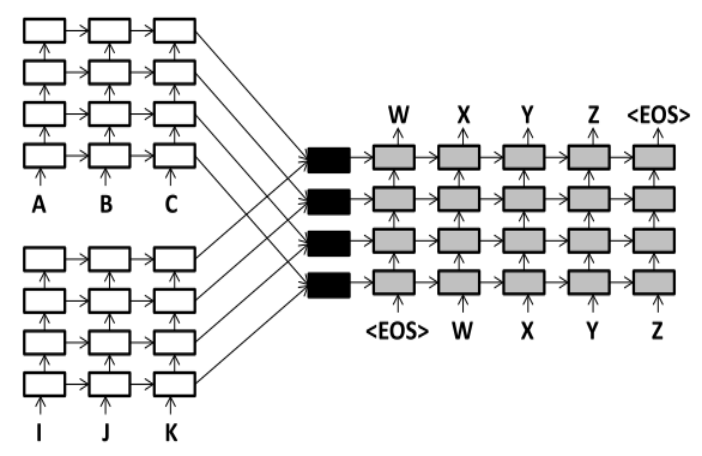
本篇论文构建了一个多源机器翻译的模型。使用多种源语言作为参考生成目标语言。需要注意图中黑色实心方框,这是将多个源语言的 context vector 和 hidden vector 进行结合的部位。
9、《Attention Strategies for Multi-Source Sequence to Sequence Learning》2017
本篇论文是对第八篇论文的一个补充,它介绍了多个黑色实心方框如何结合 context vector 和 hidden vector 的方法。
10、《Attention-based Multimodal Neural Machine Translation》2016
本篇论文介绍了将图片描述内容翻译为另一种语言的方法,主要是结合文本特征的图片的特征。
11、《Long Short-Term Memory-Networks for Machine Reading》2016
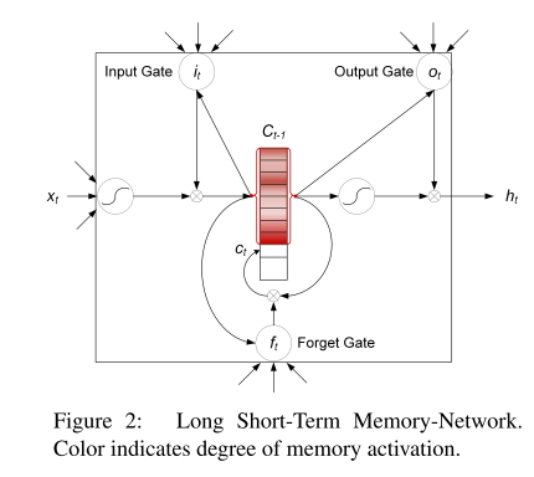
传统的 Encoder-Decoder 翻译模型存在两个问题,一个是记忆压缩问题,另一个是输入的结构化问题。本篇论文通过设计 memory/hidden tape 两个类似列表的结构,以及描述词与词之间相关程度的 intra-attention 来改进LSTM处理输入的结构化问题。
三、Attention 结构的改进
1、针对机器翻译过程中出现的遗漏或者重复翻译的问题。
《Coverage Embedding Models for Neural Machine Translation》2016
本篇论文提出了一个 coverage embedding model,它为每一个 source sentence 单词都设置了一个 coverage embedding,然后在翻译时实时更新这些 embedding,每一个 embedding 越接近0就表示已经被翻译过了不需要再次翻译。
《Incorporating Structural Aligment Biases into an Attention Neural Translation Model》
本篇论文提出了在下一次预测的时候加入过去时刻的 attention 信息,这样就可以保证已经被翻译过的不会再次翻译。
2、增加 attention 的有监督训练模型
《Supervised Attention for Neural Machine Translation》2016
本篇论文为 attention 增加了一个 gold standard,在最后计算损失时加入模型 attention 和 gold standard 的距离。
四、总结
还有一些论文没有列出来,都是对 attention 结构的补充,感兴趣的朋友可以登录 CMU 课程首页查询所有论文的列表。
Attention 结构的基本思想就是帮助我们有权重地关注序列中的某一个部分,它可以根据我们在研究过程中遇到的不同问题进行不同的变化。
