

作者 | Justin Gage
译者 | Sambodhi
编辑 | Vincent
AI前线出品| ID:ai-front
AI 前线导语:“尽管人工智能正在被广泛应用,但大规模部署基于 AI 的产品如此之难,不过,一些新技术正被寄以厚望改变这一现状。
基石风投合伙公司研究人工智能、机器学习的分析师、美国纽约大学的前数据科学家 Justin Gage 不久前写了一篇文章 [1],为我们讲述了机器学习的部署和建模的不同之处,以及在公司中部署机器学习的困境,并介绍了 Algorithmia 公司在解决这一难题的优势。Algorithmia 是一个非常有趣的平台,它用 App Store 的模式为“算法”量身打造了一个类似的应用商店,让开发者可以到这个商店里发布自己的算法,或者寻找并购买自己需要实现的算法”。
以下是作者 Justin Gage 的声明:
我并非 Algorithmia 雇员,与该公司亦无任何利益相关。作为具有数据科学背景的数据科学家,我仅仅是为了本文观点找到一家令人信服的公司而已。
毫无疑问,我们已经迈入了人工智能时代,机器学习几乎渗透了我们日常生活和工作中所有的方方面面。受到日益创新的数据存储和计算能力的驱使,上世纪 70 年代诞生的神经网络闪亮回归了。医疗、安防、客服、欺诈检测,但凡你能想到的,都有资金雄厚的公司正在通过机器学习来提高和改进上述问题。很有可能,你正是通过 Medium 基于机器学习的推荐系统发现的这篇文章。
机器学习似乎因为任何理由都能很好地解决一系列问题并立竿见影。你甚至称之为一场革命。
创建深度学习模型越来越容易,但大规模部署却依然没有这么容易
数据存储和 Nvidia 的兴起无疑推动了这种革命,当今机器学习的另一个推动力就是你可以轻松地创建有效、精准的模型。机器学习正在显著的抽象化:新的工具使 AI 落地比任何以往时候都更容易了。[2]
除了像 Clarifai 和 Indico 那样为特定任务提供功能丰富的 API 的私人公司外,在流行的数据科学语言(如 R、Python 等)中的第三方工具包生态系统呈现飞跃式发展。2015 年 11 月,Google 发布 TensorFlow 初始版,从那时起它的发展势头异常迅猛(已经很流行的 ScikitLearn 除外)。对数据科学家而言,在测试环境中创建复杂模型已经方便多了。
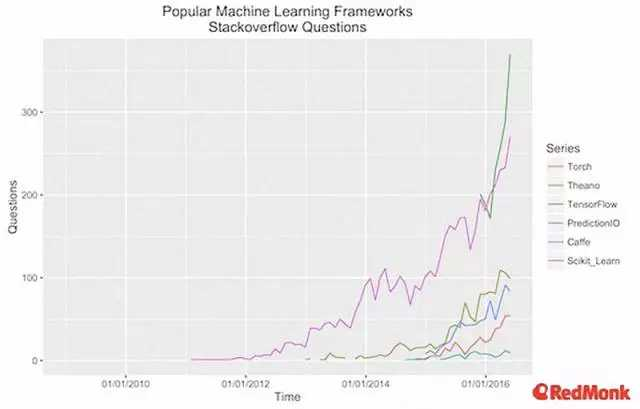
遗憾的是,这种方便并没有脱离赖以发轫的 iPython Notebook。这是因为机器学习模型在生产环境中工作,与它在你电脑上工作相比,是非常不同的任务。部署模型意味着模型被大规模调用时,以你想要的方式进行工作。创建理论上精确的模型是无用的,如果它们一旦开始为客户提供服务就崩溃的话。
你要迎接全新挑战,你需要担心的是,掌握一套新技能,以及衡量你成功的不同指标。
部署与创建模型非常不同,无论公司大小,它都非常困难
就像分布式应用一样,部署机器学习模型极其困难,是跟构建模型完全不同的任务。体现在以下几个方面:
人员的不同:由数据科学家和机器学习研究人员完成模型构建,而部署则由软件工程师、机器学习工程师和数据工程师来完成。
指标的不同:模型构建的目标是创建能够准确预测的模型,而部署的目标是快速、可靠的预测。
场所的不同:模型构建通常由多人在多台虚拟服务器上完成,而部署模型需要具备扩展的能力,能够处理极为海量的 API 请求。
这些区别反映了部署模型和构建模型有所不同。这也是很难做到的,因为涉及到不同的技巧、优先级和能力。假使你最精准的模型需要很长时间运行将会怎么样?如何用新数据更新模型?如何通过跨地域多元化来优化速度?
无论公司规模多大,都会受此问题困扰。部署对那些希望开发和运行机器学习模型产品的初创公司来说,简直就是一团乱麻。招聘合格的软件工程师和数据工程师本就是一个巨大的挑战了,再让一款产品落地就更为困难,你的恢复能力还取决于使模型运行的那些人。数据科学家所掌握的技能为你创建精准的模型,但却无法大规模部署模型。
这个问题并不会随着你公司的发展而变得容易,事实上,在某些方面,这个问题在企业中最为明显。数据科学团队开发有效的模型和产品,但他们需要让这些运行及具备可扩展能力,这就意味着需要其他工程团队加入,而他们并不一定拥有合适的背景。然而,数据科学家还得依靠他们来正确地移植模型、调整参数、确定批量大小。等他们的团队克服机器学习部署的挑战后,时间可能已经过去四个月或者更久,而且模型与数据科学团队最初构建的样子或者运作完全不一样。
总之,很多初创公司无法解决这一令人头疼的问题,很多企业同样也束手无策。针对部署问题的普遍解决方案之一是使用某个平台,但这些平台对多数公司并不适用。本质上来说,你要保存自己的数据,但要使用 API 快速构建驻留在供应商的服务器上的脏模型,它们给你扩展模型,你还要操心如何使这一切良好运作。适合此类需求的平台有 BigML、Seldon。
不幸的是,取决于它们的构建方式,这些平台部署并非总是有用:如果你公司构建了大型的机器学习相关产品,你就无法将模型迁移到第三方平台上。你想创建自己的复杂算法,不管它们是 TensorFlow 还是别的什么其他平台上的神经网络。
造成这一现状的根源就是没有哪个产品解决了“最后一公里”的问题:根据自己的需求开发模型,同时维护好剩下的部分。谢天谢地,事情正在改变。
Algorithmia 提供部署服务,解决“最后一公里”的难题
Algorithmia 发布新产品来解决这一问题,但遗留了一个问题:建模和数据仍然由数据科学家掌握。这款产品名为 Enterprise AI Layer,它本质上就是对机器学习部署进行自动化的开发运维,让你专心致志构建伟大的模型和产品。
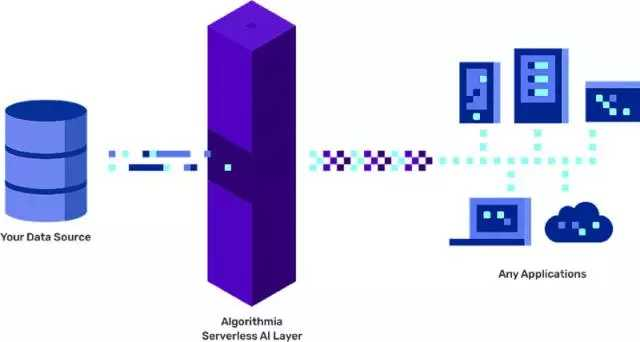
Enterprise AI Layer 涵盖了可扩展部署解决方案所有的基础问题。它和云无关,可以根据你的需求进行扩展,并允许你选择使用 CPU 或者 GPU,有着非常低的延迟。Algorithmia 的平台也适用于开发运维人员:它有详细的仪表板,能跟踪所有的指标,确保部署符合客户要求。
Google 工程和人工智能副总裁 Anna Patterson 表示:
作为一个多年设计和部署机器学习系统的人,我真是被 Algorithmia 的无服务器微服务架构所折服。对想规模化部署 AI 的公司来说,这是一个很棒的解决方案。但是,除去技术规格之外,Algorithmia 的 AI Layer 也很重要,因为它改变了公司考虑机器学习的方式。现在,机器学习就像任何应用一样,在你发送新数据并预测之前,你需要处理所有的基础架构。就像一个 API 调用 Yelp 的应用那样,你的 API 可以调用你的模型。这就是应用程序的类型,意味着你的团队需具备应用部署的技能。
现在情况不一样了,因为你的团队可以专注创建优秀的模型,而不是考虑它们在基础架构上如何运作。这是无服务器通过 Google 的 BigQuery 和 Amazon 的 Athena 来完成数据存储的模式:允许公司专注数据分析,无须考虑复杂的存储数据技术问题。赖以获取利润的数据分析是从数据存储中抽象出来的,现在,建模也可以从部署中抽象出来。
这真是帅爆了:这意味着更多的点子可以转化成产品,更多的产品可以打破特大型工程团队和公司积压带来的单调。这意味着作为一名数据科学家,你可以做你真正想做的事情:专注构建卓越的想法和模型,而不是如何处理后端的管理。我认为,这是一件幸事。
参考资料
[1] The missing part of the Machine Learning revolution
towardsdatascience.com/the-missing…
[2] Machine Learning Abstraction And The Age of AI Ease
machinelearnings.co/machine-lea…
-全文完-
人工智能已不再停留在大家的想象之中,各路大牛也都纷纷抓住这波风口,投入AI创业大潮。那么,2017年,到底都有哪些AI落地案例呢?机器学习、深度学习、NLP、图像识别等技术又该如何用来解决业务问题?
2018年1月11-14日,AICon全球人工智能技术大会上,一些大牛将首次分享AI在金融、电商、教育、外卖、搜索推荐、人脸识别、自动驾驶、语音交互等领域的最新落地案例,应该能学到不少东西。目前大会8折报名倒计时,更多精彩可点击阅读原文详细了解。

