

什么是数据类型? 前两章里面包含的字符串、布尔类型、整数、浮点数都是数据类型。数据类型在一个编程语言中必不可少,也是使用最多的。 而且数据类型的数据都是存放在内存中的,我们一般操作都是在对内存里对象操作。 什么是数组? 数组也是一种数据类型,为了方便处理数据,把一些同类数据放到一起就是数组,是一组数据的集合,数组内的数据称为元素,每个元素都有一个下标(索引),从0开始。 在Python中,内建数据结构有列表(list)、元组(tuple)、字典(dict)、集合(set)。
3.1 列表[List] 3.1.1 定义列表 >>> lst = ['a','b','c',1,2,3] 用中括号括起来,元素以逗号分隔,字符串用单引号引起来,整数不用。
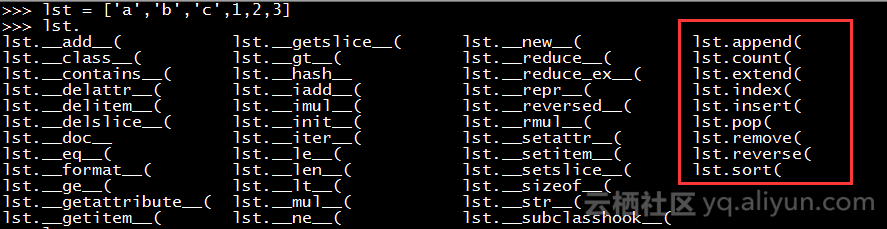
3.1.2 基本操作 # 追加一个元素 >>> lst.append(4) >>> lst ['a', 'b', 'c', 1, 2, 3, 4] # 统计列表中a字符出现的次数 >>> lst.count('a') 1 # 将一个列表作为元素添加到lst列表中 >>> a = [5,6] >>> lst.extend(a) >>> lst ['a', 'b', 'c', 1, 2, 3, 4, 5, 6] # 查找元素3的索引位置 >>> lst.index(1) 3 # 在第3个索引位置插入一个元素 >>> lst.insert(3, 0) >>> lst ['a', 'b', 'c', 0, 1, 2, 3, 4, 5, 6] # 删除最后一个元素和第3个下标元素 >>> lst.pop() 6 >>> lst.pop(3) 0 >>> lst ['a', 'b', 'c', 1, 2, 3, 4, 5] # 删除元素是5,如果没有会返回错误 >>> lst.remove("5 ") >>> lst ['a', 'b', 'c', 1, 2, 3, 4] # 倒序排列元素 >>> lst.reverse() >>> lst [4, 3, 2, 1, 'c', 'b', 'a'] # 正向排序元素 >>> lst.sort() >>> lst [1, 2, 3, 4, 'a', 'b', 'c'] # 列表连接 >>> a = [1,2,3] >>> b = ['a','b','c'] >>> a + b [1, 2, 3, 'a', 'b', 'c'] 3.1.3 学习新函数对列表排序 # reversed()函数倒序排列 使用此函数会创建一个迭代器,遍历打印才能输出: >>> lst = ['a', 'b', 'c', 1, 2, 3, 4, 5] >>> type(reversed(lst)) <type 'listreverseiterator'> >>> lst2 = [] >>> for i in reversed(lst): ... lst2.append(i) ... >>> lst2 [5, 4, 3, 2, 1, 'c', 'b', 'a'] # sorted()函数正向排列 >>> lst2 = [] >>> for i in sorted(lst): ... lst2.append(i) ... >>> lst2 [1, 2, 3, 4, 5, 'a', 'b', 'c']
这里在讲解一个序列生成器range()函数,生成的是一个列表: >>> type(range(5)) <type 'list'> >>> for i in range(1,5): ... print i ... 1 2 3 4 当然也可以用上面的排序函数来排序这个生成的序列了: >>> for i in reversed(range(1,10,3)): ... print i ... 7 4 1 range()函数用法:range(start,end,step) 说明:是不是和列表内置方法结果一样!区别是内置函数不改动原有序列。
3.1.4 切片 >>> lst [1, 2, 3, 4, 'a', 'b', 'c'] # 返回第一个元素 >>> lst[0] 1 # 返回倒数第一个元素 >>> lst[-1] 'c' # 取出倒数第一个元素 >>> lst[0:-1] [1, 2, 3, 4, 'a', 'b'] # 返回第一个至第四个元素 >>> lst[0:4] [1, 2, 3, 4] 3.1.5 清空列表 方法1: >>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> lst = [] >>> lst [] 方法2: >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst[:] >>> lst [] # 删除列表 >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst >>> lst Traceback (most recent call last): File "<stdin> ", line 1, in <module> NameError: name 'lst' is not defined 3.1.6 del语句 del语句也可以删除一个下标范围的元素 >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst[0:4] >>> lst ['a', 'b', 'c'] 3.1.7 列表推导式 利用其它列表推导出新的列表。 # 通过迭代对象方法 方法1: >>> lst = [] >>> for i in range(5): ... lst.append(i) ... >>> lst [0, 1, 2, 3, 4] 方法2: >>> lst = [] >>> lst = [i for i in range(5)] >>> lst [0, 1, 2, 3, 4] 说明:方法1和方法2,实现方式是一样的,只是方法2用简洁的写法。for循环在下一章会讲。
# 通过已有的列表生成新列表 >>> lst [0, 1, 2, 3, 4] >>> lst2 = [i for i in lst if i > 2] >>> lst2 [3, 4] 3.1.8 遍历列表 如果既要遍历索引又要遍历元素,可以这样写。 方法1: >>> lst = ['a','b','c',1,2,3] >>> for i in range(len(lst)): ... print i,lst[i] ... 0 a 1 b 2 c 3 1 4 2 5 3 方法2: >>> for index, value in enumerate(lst): ... print index,value ... 0 a 1 b 2 c 3 1 4 2 5 3 又学了一个新函数enumrate(),可遍历列表、字符串的下标和元素。
3.2 元组(Tuple) 元组与列表类型,不同之处在于元素的元素不可修改。 2.1 定义元组 t = ('a','b','c',1,2,3) 用小括号括起来,元素以逗号分隔,字符串用单引号引起来,整数不用。 2.2 基本操作 count()和index()方法和切片使用方法与列表使用一样,这里不再讲解。 3.3 集合(set) 集合是一个无序不重复元素的序列,主要功能用于删除重复元素和关系测试。 集合对象还支持联合(union),交集(intersection),差集(difference)和对称差集(sysmmetric difference)数学运算。 需要注意的是,集合对象不支持索引,因此不可以被切片。
3.3.1 定义集合 >>> s = set() >>> s set([]) 使用set()函数创建集合。 3.3.2 基本操作 # 添加元素 >>> s.add('a') >>> s set(['a']) >>> s.add('b') >>> s set(['a', 'b']) >>> s.add('c') >>> s set(['a', 'c', 'b']) >>> s.add('c') >>> s set(['a', 'c', 'b']) 说明:可以看到,添加的元素是无序的,并且不重复的。
# update方法事把传入的元素拆分为个体传入到集合中。与直接set('1234')效果一样。 >>> s.update('1234') >>> s set(['a', 'c', 'b', '1', '3', '2', '4']) # 删除元素 >>> s.remove('4') >>> s set(['a', 'c', 'b', '1', '3', '2']) # 删除元素,没有也不会报错,而remove会报错 >>> s.discard('4') >>> s set(['a', 'c', 'b', '1', '3', '2'])
# 删除第一个元素 >>> s.pop() 'a' >>> s set(['c', 'b', '1', '3', '2']) # 清空元素 >>> s.clear() >>> s set([])
# 列表转集合,同时去重 >>> lst = ['a','b','c',1,2,3,1,2,3] >>> s = set(lst) >>> s set(['a', 1, 'c', 'b', 2, 3]) 3.3.3 关系测试
示例: # 返回差集 >>> a - b set(['1', '3', '2']) >>> b - a set(['9', '8', '7']) # 返回交集 >>> a & b set(['5', '4', '6']) # 返回合集 >>> a | b set(['1', '3', '2', '5', '4', '7', '6', '9', '8']) # 不等于 >>> a !=
b True # 等于 >>> a == b False # 存在为真 >>> '1' in a True # 不存在为真 >>> '7' not in a True
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
3.4 字典{Dict} 序列是以连续的整数位索引,与字典不同的是,字典以关键字为索引,关键字可以是任意不可变对象(不可修改),通常是字符串或数值。 字典是一个无序键:值(Key:Value)集合,在一字典中键必须是互不相同的, 3.4.1 定义字典 >>> d = {'a':1, 'b':2, 'c':3} 用大括号括起来,一个键对应一个值,冒号分隔,多个键值逗号分隔。 3.4.2 基本操作 # 返回所有键值 >>> d.items() [('a', 1), ('c', 3), ('b', 2)] # 返回所有键 >>> d.keys() ['a', 'c', 'b'] # 查看所有值 >>> d.values() [1, 3, 2] # 添加键值 >>> d['e'] = 4 >>> d {'a': 1, 'c': 3, 'b': 2, 'e': 4} # 获取单个键的值,如果这个键不存在就会抛出KeyError错误 >>> d['a'] >>> 1 # 获取单个键的值,如果有这个键就返回对应的值,否则返回自定义的值no >>> d.get('a','no') 1 >>> d.get('f','no') no # 删除第一个键值 >>> d.popitem() ('a', 1) >>> d {'c': 3, 'b': 2, 'e': 4} # 删除指定键 >>> d.pop('b') 2 >>> d {'c': 3, 'e': 4} # 添加其他字典键值到本字典 >>> d {'c': 3, 'e': 4} >>> d2 = {'a':1}
>>> d.update(d2) >>> d {'a': 1, 'c': 3, 'e': 4} # 拷贝为一个新字典 >>> d {'a': 1, 'c': 3, 'e': 4} >>> dd = d.copy() >>> dd {'a': 1, 'c': 3, 'e': 4} >>> d {'a': 1, 'c': 3, 'e': 4} # 判断键是否在字典 >>> d.has_key('a') True >>> d.has_key('b') False 3.4.3 可迭代对象 字典提供了几个获取键值的迭代器,方便我们在写程序时处理,就是下面以iter开头的方法。
d.iteritems() # 获取所有键值,很常用 d.iterkeys() # 获取所有键 d.itervalues() # 获取所有值
# 遍历iteritems()迭代器 >>> for i in d.iteritems(): ... print i ... ('a', 1) ('c', 3) ('b', 2) 说明:以元组的形式打印出了键值 如果我们只想得到键或者值呢,就可以通过元组下标来分别获取键值: >>> for i in d.iteritems(): ... print "%s:%s " %(i[0],i[1]) ... a:1 c:3 b:2 有比上面更好的方法实现: >>> for k, v in d.iteritems(): ... print "%s: %s " %(k, v) ... a: 1 c: 3 b: 2 这样就可以很方面处理键值了!
# 遍历其他两个迭代器也是同样的方法 >>> for i in d.iterkeys(): ... print i ... a c b >>> for i in d.itervalues(): ... print i ... 1 3 2 说明:上面用到了for循环来遍历迭代器,for循环的用法在下一章会详细讲解。 3.4.4 一个键多个值 一个键对应一个值,有些情况无法满足需求,字典允许一个键多个值,也就是嵌入其他数组,包括字典本身。 # 嵌入列表 >>> d = {'a':[1,2,3], 'b':2, 'c':3} >>> d['a'] [1, 2, 3] >>> d['a'][0] # 获取值 1 >>> d['a'].append(4) # 追加元素 >>> d {'a': [1, 2, 3, 4], 'c': 3, 'b': 2} # 嵌入元组 >>> d = {'a':(1,2,3), 'b':2, 'c':3} >>> d['a'][1] 2 # 嵌入字典 >>> d = {'a':{'d':4,'e':5}, 'b':2, 'c':3} >>> d['a'] {'e': 5, 'd': 4} >>> d['a']['d'] # 获取值 4 >>> d['a']['e'] = 6 # 修改值 >>> d {'a': {'e': 6, 'd': 4}, 'c': 3, 'b': 2}
3.5 额外的数据类型 colloctions()函数在内置数据类型基础上,又增加了几个额外的功能,替代内建的字典、列表、集合、元组及其他数据类型。 3.5.1 namedtuple namedtuple函数功能是使用名字来访问元组元素。 语法:namedtuple("名称 ", [名字列表])
>>> from collections import namedtuple >>> nt = namedtuple('point', ['a', 'b', 'c']) >>> p = nt(1,2,3) >>> p.a 1 >>> p.b 2 >>> p.c 3 namedtuple函数规定了tuple元素的个数,并定义的名字个数与其对应。
3.5.2 deque 当list数据量大时,插入和删除元素会很慢,deque的作用就是为了快速实现插入和删除元素的双向列表。 >>> from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('d') >>> q deque(['a', 'b', 'c', 'd']) >>> q.appendleft(0) >>> q deque([0, 'a', 'b', 'c', 'd']) >>> q.pop() 'd' >>> q.popleft() 0 实现了插入和删除头部和尾部元素。比较适合做队列。 3.5.3 Counter 顾名思义,计数器,用来计数。 例如,统计字符出现的个数: >>> from collections import Counter >>> c = Counter() >>> for i in "Hello world! ": ... c[i] += 1 ... >>> c Counter({'l': 3, 'o': 2, '!': 1, ' ': 1, 'e': 1, 'd': 1, 'H': 1, 'r': 1, 'w': 1}) 结果是以字典的形式存储,实际Counter是dict的一个子类。 3.5.4 OrderedDict 内置dict是无序的,OrderedDict函数功能就是生成有序的字典。 例如,根据前后插入顺序排列:
>>> d = {'a':1, 'b':2, 'c':3} >>> d # 默认dict是无序的 {'a': 1, 'c': 3, 'b': 2}
>>> from collections import OrderedDict >>> od = OrderedDict() >>> od['a'] = 1 >>> od['b'] = 2 >>> od['c'] = 3 >>> od OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# 转为字典 >>> import json >>> json.dumps(od) '{"a ": 1, "b ": 2, "c ": 3}' OrderedDict输出的结果是列表,元组为元素,如果想返回字典格式,可以通过json模块进行转化。
3.6 数据类型转换 3.6.1 常见数据类型转换 # 转整数 >>> i = '1' >>> type(i) <type 'str'> >>> type(int(i)) <type 'int'> # 转浮点数 >>> f = 1 >>> type(f) <type 'int'> >>> type(float(f)) <type 'float'> # 转字符串 >>> i = 1 >>> type(i) <type 'int'> >>> type(int(1)) <type 'int'> # 字符串转列表 方式1: >>> s = 'abc' >>> lst = list(s) >>> lst ['a', 'b', 'c'] 方式2: >>> s = 'abc 123' >>> s.split() ['abc', '123'] # 列表转字符串 >>> s = " " >>> s = ''.join(lst) >>> s 'abc' # 元组转列表 >>> lst ['a', 'b', 'c'] >>> t = tuple(lst) >>> t ('a', 'b', 'c') # 列表转元组 >>> lst = list(t) >>> lst ['a', 'b', 'c'] # 字典格式字符串转字典 方法1: >>> s = '{"a ": 1, "b ": 2, "c ": 3}' >>> type(s) <type 'str'> >>> d = eval(s) >>> d {'a': 1, 'c': 3, 'b': 2} >>> type(d) <type 'dict'> 方法2: >>> import json >>> s = '{"a ": 1, "b ": 2, "c ": 3}'
>>> json.loads(s) {u'a': 1, u'c': 3, u'b': 2} >>> d = json.loads(s) >>> d {u'a': 1, u'c': 3, u'b': 2} >>> type(d) <type 'dict'> 3.6.2 学习两个新内建函数 1) join() join()函数是字符串操作函数,用于字符串连接。 # 字符串时,每个字符作为单个体 >>> s = "ttt " >>> ". ".join(s) 't.t.t' # 以逗号连接元组元素,生成字符串,与上面的列表用法一样。 >>> t = ('a', 'b', 'c') >>> s = ", ".join(t) >>> s 'a,b,c' # 字典 >>> d = {'a':1, 'b':2, 'c':3} >>> ", ".join(d) 'a,c,b' 2) eval() eval()函数将字符串当成Python表达式来处理。 >>> s = "abc " >>> eval('s') 'abc' >>> a = 1 >>> eval('a + 1') 2 >>> eval('1 + 1') 2
3.1.2 基本操作 # 追加一个元素 >>> lst.append(4) >>> lst ['a', 'b', 'c', 1, 2, 3, 4] # 统计列表中a字符出现的次数 >>> lst.count('a') 1 # 将一个列表作为元素添加到lst列表中 >>> a = [5,6] >>> lst.extend(a) >>> lst ['a', 'b', 'c', 1, 2, 3, 4, 5, 6] # 查找元素3的索引位置 >>> lst.index(1) 3 # 在第3个索引位置插入一个元素 >>> lst.insert(3, 0) >>> lst ['a', 'b', 'c', 0, 1, 2, 3, 4, 5, 6] # 删除最后一个元素和第3个下标元素 >>> lst.pop() 6 >>> lst.pop(3) 0 >>> lst ['a', 'b', 'c', 1, 2, 3, 4, 5] # 删除元素是5,如果没有会返回错误 >>> lst.remove("5 ") >>> lst ['a', 'b', 'c', 1, 2, 3, 4] # 倒序排列元素 >>> lst.reverse() >>> lst [4, 3, 2, 1, 'c', 'b', 'a'] # 正向排序元素 >>> lst.sort() >>> lst [1, 2, 3, 4, 'a', 'b', 'c'] # 列表连接 >>> a = [1,2,3] >>> b = ['a','b','c'] >>> a + b [1, 2, 3, 'a', 'b', 'c'] 3.1.3 学习新函数对列表排序 # reversed()函数倒序排列 使用此函数会创建一个迭代器,遍历打印才能输出: >>> lst = ['a', 'b', 'c', 1, 2, 3, 4, 5] >>> type(reversed(lst)) <type 'listreverseiterator'> >>> lst2 = [] >>> for i in reversed(lst): ... lst2.append(i) ... >>> lst2 [5, 4, 3, 2, 1, 'c', 'b', 'a'] # sorted()函数正向排列 >>> lst2 = [] >>> for i in sorted(lst): ... lst2.append(i) ... >>> lst2 [1, 2, 3, 4, 5, 'a', 'b', 'c']
这里在讲解一个序列生成器range()函数,生成的是一个列表: >>> type(range(5)) <type 'list'> >>> for i in range(1,5): ... print i ... 1 2 3 4 当然也可以用上面的排序函数来排序这个生成的序列了: >>> for i in reversed(range(1,10,3)): ... print i ... 7 4 1 range()函数用法:range(start,end,step) 说明:是不是和列表内置方法结果一样!区别是内置函数不改动原有序列。
3.1.4 切片 >>> lst [1, 2, 3, 4, 'a', 'b', 'c'] # 返回第一个元素 >>> lst[0] 1 # 返回倒数第一个元素 >>> lst[-1] 'c' # 取出倒数第一个元素 >>> lst[0:-1] [1, 2, 3, 4, 'a', 'b'] # 返回第一个至第四个元素 >>> lst[0:4] [1, 2, 3, 4] 3.1.5 清空列表 方法1: >>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> lst = [] >>> lst [] 方法2: >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst[:] >>> lst [] # 删除列表 >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst >>> lst Traceback (most recent call last): File "<stdin> ", line 1, in <module> NameError: name 'lst' is not defined 3.1.6 del语句 del语句也可以删除一个下标范围的元素 >>> lst = [1, 2, 3, 4, 'a', 'b', 'c'] >>> del lst[0:4] >>> lst ['a', 'b', 'c'] 3.1.7 列表推导式 利用其它列表推导出新的列表。 # 通过迭代对象方法 方法1: >>> lst = [] >>> for i in range(5): ... lst.append(i) ... >>> lst [0, 1, 2, 3, 4] 方法2: >>> lst = [] >>> lst = [i for i in range(5)] >>> lst [0, 1, 2, 3, 4] 说明:方法1和方法2,实现方式是一样的,只是方法2用简洁的写法。for循环在下一章会讲。
# 通过已有的列表生成新列表 >>> lst [0, 1, 2, 3, 4] >>> lst2 = [i for i in lst if i > 2] >>> lst2 [3, 4] 3.1.8 遍历列表 如果既要遍历索引又要遍历元素,可以这样写。 方法1: >>> lst = ['a','b','c',1,2,3] >>> for i in range(len(lst)): ... print i,lst[i] ... 0 a 1 b 2 c 3 1 4 2 5 3 方法2: >>> for index, value in enumerate(lst): ... print index,value ... 0 a 1 b 2 c 3 1 4 2 5 3 又学了一个新函数enumrate(),可遍历列表、字符串的下标和元素。
3.2 元组(Tuple) 元组与列表类型,不同之处在于元素的元素不可修改。 2.1 定义元组 t = ('a','b','c',1,2,3) 用小括号括起来,元素以逗号分隔,字符串用单引号引起来,整数不用。 2.2 基本操作 count()和index()方法和切片使用方法与列表使用一样,这里不再讲解。 3.3 集合(set) 集合是一个无序不重复元素的序列,主要功能用于删除重复元素和关系测试。 集合对象还支持联合(union),交集(intersection),差集(difference)和对称差集(sysmmetric difference)数学运算。 需要注意的是,集合对象不支持索引,因此不可以被切片。
3.3.1 定义集合 >>> s = set() >>> s set([]) 使用set()函数创建集合。 3.3.2 基本操作 # 添加元素 >>> s.add('a') >>> s set(['a']) >>> s.add('b') >>> s set(['a', 'b']) >>> s.add('c') >>> s set(['a', 'c', 'b']) >>> s.add('c') >>> s set(['a', 'c', 'b']) 说明:可以看到,添加的元素是无序的,并且不重复的。
# update方法事把传入的元素拆分为个体传入到集合中。与直接set('1234')效果一样。 >>> s.update('1234') >>> s set(['a', 'c', 'b', '1', '3', '2', '4']) # 删除元素 >>> s.remove('4') >>> s set(['a', 'c', 'b', '1', '3', '2']) # 删除元素,没有也不会报错,而remove会报错 >>> s.discard('4') >>> s set(['a', 'c', 'b', '1', '3', '2'])
# 删除第一个元素 >>> s.pop() 'a' >>> s set(['c', 'b', '1', '3', '2']) # 清空元素 >>> s.clear() >>> s set([])
# 列表转集合,同时去重 >>> lst = ['a','b','c',1,2,3,1,2,3] >>> s = set(lst) >>> s set(['a', 1, 'c', 'b', 2, 3]) 3.3.3 关系测试
| 符号 | 描述 |
| - | 差集 |
| & | 交集 |
| | | 合集、并集 |
| != | 不等于 |
| == | 等于 |
| in | 是成员为真 |
| not in | 不是成员为真 |
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
3.4 字典{Dict} 序列是以连续的整数位索引,与字典不同的是,字典以关键字为索引,关键字可以是任意不可变对象(不可修改),通常是字符串或数值。 字典是一个无序键:值(Key:Value)集合,在一字典中键必须是互不相同的, 3.4.1 定义字典 >>> d = {'a':1, 'b':2, 'c':3} 用大括号括起来,一个键对应一个值,冒号分隔,多个键值逗号分隔。 3.4.2 基本操作 # 返回所有键值 >>> d.items() [('a', 1), ('c', 3), ('b', 2)] # 返回所有键 >>> d.keys() ['a', 'c', 'b'] # 查看所有值 >>> d.values() [1, 3, 2] # 添加键值 >>> d['e'] = 4 >>> d {'a': 1, 'c': 3, 'b': 2, 'e': 4} # 获取单个键的值,如果这个键不存在就会抛出KeyError错误 >>> d['a'] >>> 1 # 获取单个键的值,如果有这个键就返回对应的值,否则返回自定义的值no >>> d.get('a','no') 1 >>> d.get('f','no') no # 删除第一个键值 >>> d.popitem() ('a', 1) >>> d {'c': 3, 'b': 2, 'e': 4} # 删除指定键 >>> d.pop('b') 2 >>> d {'c': 3, 'e': 4} # 添加其他字典键值到本字典 >>> d {'c': 3, 'e': 4} >>> d2 = {'a':1}
>>> d.update(d2) >>> d {'a': 1, 'c': 3, 'e': 4} # 拷贝为一个新字典 >>> d {'a': 1, 'c': 3, 'e': 4} >>> dd = d.copy() >>> dd {'a': 1, 'c': 3, 'e': 4} >>> d {'a': 1, 'c': 3, 'e': 4} # 判断键是否在字典 >>> d.has_key('a') True >>> d.has_key('b') False 3.4.3 可迭代对象 字典提供了几个获取键值的迭代器,方便我们在写程序时处理,就是下面以iter开头的方法。
d.iteritems() # 获取所有键值,很常用 d.iterkeys() # 获取所有键 d.itervalues() # 获取所有值
# 遍历iteritems()迭代器 >>> for i in d.iteritems(): ... print i ... ('a', 1) ('c', 3) ('b', 2) 说明:以元组的形式打印出了键值 如果我们只想得到键或者值呢,就可以通过元组下标来分别获取键值: >>> for i in d.iteritems(): ... print "%s:%s " %(i[0],i[1]) ... a:1 c:3 b:2 有比上面更好的方法实现: >>> for k, v in d.iteritems(): ... print "%s: %s " %(k, v) ... a: 1 c: 3 b: 2 这样就可以很方面处理键值了!
# 遍历其他两个迭代器也是同样的方法 >>> for i in d.iterkeys(): ... print i ... a c b >>> for i in d.itervalues(): ... print i ... 1 3 2 说明:上面用到了for循环来遍历迭代器,for循环的用法在下一章会详细讲解。 3.4.4 一个键多个值 一个键对应一个值,有些情况无法满足需求,字典允许一个键多个值,也就是嵌入其他数组,包括字典本身。 # 嵌入列表 >>> d = {'a':[1,2,3], 'b':2, 'c':3} >>> d['a'] [1, 2, 3] >>> d['a'][0] # 获取值 1 >>> d['a'].append(4) # 追加元素 >>> d {'a': [1, 2, 3, 4], 'c': 3, 'b': 2} # 嵌入元组 >>> d = {'a':(1,2,3), 'b':2, 'c':3} >>> d['a'][1] 2 # 嵌入字典 >>> d = {'a':{'d':4,'e':5}, 'b':2, 'c':3} >>> d['a'] {'e': 5, 'd': 4} >>> d['a']['d'] # 获取值 4 >>> d['a']['e'] = 6 # 修改值 >>> d {'a': {'e': 6, 'd': 4}, 'c': 3, 'b': 2}
3.5 额外的数据类型 colloctions()函数在内置数据类型基础上,又增加了几个额外的功能,替代内建的字典、列表、集合、元组及其他数据类型。 3.5.1 namedtuple namedtuple函数功能是使用名字来访问元组元素。 语法:namedtuple("名称 ", [名字列表])
>>> from collections import namedtuple >>> nt = namedtuple('point', ['a', 'b', 'c']) >>> p = nt(1,2,3) >>> p.a 1 >>> p.b 2 >>> p.c 3 namedtuple函数规定了tuple元素的个数,并定义的名字个数与其对应。
3.5.2 deque 当list数据量大时,插入和删除元素会很慢,deque的作用就是为了快速实现插入和删除元素的双向列表。 >>> from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('d') >>> q deque(['a', 'b', 'c', 'd']) >>> q.appendleft(0) >>> q deque([0, 'a', 'b', 'c', 'd']) >>> q.pop() 'd' >>> q.popleft() 0 实现了插入和删除头部和尾部元素。比较适合做队列。 3.5.3 Counter 顾名思义,计数器,用来计数。 例如,统计字符出现的个数: >>> from collections import Counter >>> c = Counter() >>> for i in "Hello world! ": ... c[i] += 1 ... >>> c Counter({'l': 3, 'o': 2, '!': 1, ' ': 1, 'e': 1, 'd': 1, 'H': 1, 'r': 1, 'w': 1}) 结果是以字典的形式存储,实际Counter是dict的一个子类。 3.5.4 OrderedDict 内置dict是无序的,OrderedDict函数功能就是生成有序的字典。 例如,根据前后插入顺序排列:
>>> d = {'a':1, 'b':2, 'c':3} >>> d # 默认dict是无序的 {'a': 1, 'c': 3, 'b': 2}
>>> from collections import OrderedDict >>> od = OrderedDict() >>> od['a'] = 1 >>> od['b'] = 2 >>> od['c'] = 3 >>> od OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# 转为字典 >>> import json >>> json.dumps(od) '{"a ": 1, "b ": 2, "c ": 3}' OrderedDict输出的结果是列表,元组为元素,如果想返回字典格式,可以通过json模块进行转化。
3.6 数据类型转换 3.6.1 常见数据类型转换 # 转整数 >>> i = '1' >>> type(i) <type 'str'> >>> type(int(i)) <type 'int'> # 转浮点数 >>> f = 1 >>> type(f) <type 'int'> >>> type(float(f)) <type 'float'> # 转字符串 >>> i = 1 >>> type(i) <type 'int'> >>> type(int(1)) <type 'int'> # 字符串转列表 方式1: >>> s = 'abc' >>> lst = list(s) >>> lst ['a', 'b', 'c'] 方式2: >>> s = 'abc 123' >>> s.split() ['abc', '123'] # 列表转字符串 >>> s = " " >>> s = ''.join(lst) >>> s 'abc' # 元组转列表 >>> lst ['a', 'b', 'c'] >>> t = tuple(lst) >>> t ('a', 'b', 'c') # 列表转元组 >>> lst = list(t) >>> lst ['a', 'b', 'c'] # 字典格式字符串转字典 方法1: >>> s = '{"a ": 1, "b ": 2, "c ": 3}' >>> type(s) <type 'str'> >>> d = eval(s) >>> d {'a': 1, 'c': 3, 'b': 2} >>> type(d) <type 'dict'> 方法2: >>> import json >>> s = '{"a ": 1, "b ": 2, "c ": 3}'
>>> json.loads(s) {u'a': 1, u'c': 3, u'b': 2} >>> d = json.loads(s) >>> d {u'a': 1, u'c': 3, u'b': 2} >>> type(d) <type 'dict'> 3.6.2 学习两个新内建函数 1) join() join()函数是字符串操作函数,用于字符串连接。 # 字符串时,每个字符作为单个体 >>> s = "ttt " >>> ". ".join(s) 't.t.t' # 以逗号连接元组元素,生成字符串,与上面的列表用法一样。 >>> t = ('a', 'b', 'c') >>> s = ", ".join(t) >>> s 'a,b,c' # 字典 >>> d = {'a':1, 'b':2, 'c':3} >>> ", ".join(d) 'a,c,b' 2) eval() eval()函数将字符串当成Python表达式来处理。 >>> s = "abc " >>> eval('s') 'abc' >>> a = 1 >>> eval('a + 1') 2 >>> eval('1 + 1') 2
