

在写 《从 Swift 中的 max(::) 看设计哲学》的过程中,产生了这样一个想法: 既然 max(_:_:) 可以用来对比任何 Comparable ,而 String 是符合 Comparable 的,那么用它来比较两个字符串"谁大谁小"会怎么样呢?
由于实验结果的捉摸不定,于是产生了一探究竟的念头。过程很有趣,结果让人感叹计算机科学之深厚。同时也是典型的 How I Resolve A Problem,故记。
用 max 来对比 String
The Comparable protocol is used for types that have an inherent order, such as numbers and strings.
Swift 标准库已经为 Sting 实现了 Comparable, max 可以用在 String 上。猜猜下面两个字符串谁更大?
let maxString = max("bc", "abc")
答案是 maxString == "bc"
Why?
根据结果我们猜测,String 的大小应该不是根据长度来判断的,有可能是按照首字母的 Unicode 编码大小来判断的。为了证实这一猜测,我们去翻翻相关资料。
首先看 String 的头文件。
我们只看到了实现了 Comparable 的声明。
extension String : Equatable {
}
extension String : Comparable {
}
嗯。 好歹证实了 String 的确实现了 Comparable 嘛。既然 Swift 是开源的,我们去源代码里找找,继续深挖。
首先 Google swift standard library source code,
我们访问 Swift 官网上的 Source Code 一节,其中中有两块资源可能会有我们的答案,一块是 Swift 源码 ,另一块是 Foundation源码。
我们把两部分都 Clone 下来看看。
首先看可以直接打开工程文件的 Foundation 源码,找到 String.swift 文件, 一共 70 行代码。类声明是这样的
extension String : _ObjectTypeBridgeable
原来这个工程是为了和 Objective - C 的库桥接而生的。看来只能到 Swift 源码中找答案了。
去 Swift 源码中找答案
Swift 的 README 中有这么一句话
Another source of documentation is the standard library itself, located in stdlib. Much of the language is actually implemented in the library (including Int)
既然这样,在 stdlib 文件夹里面,肯定也有 String 的实现。
我们在 stdlib/public/core 下找到 String.Swift 并打开。
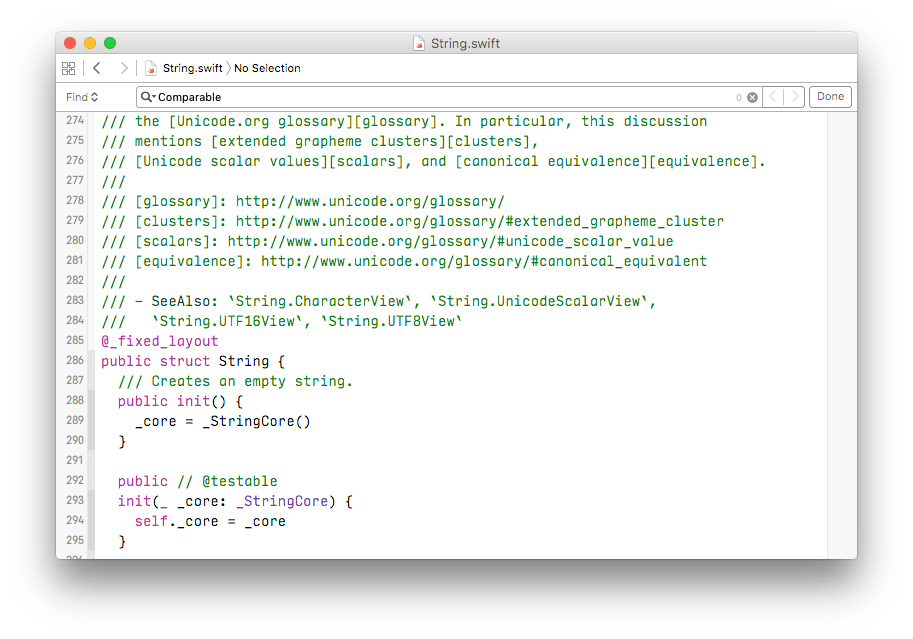
如苹果所说,Swift 标准库的文档基本上都在原代码中了,开头整整 284 行都是文档! Apple 的文档丰富和详细在这里提现得淋漓尽致。
从上图也可以看到,我们尝试搜索 Comparable 关键字,没有发现文件中有对 Comparable 的实现。快速翻阅一下 String 的 extension, 也没有发现相关的实现。
查阅 Apple 的 API Reference 可以得知 Comparable 也是 Swift 标准库的一份。因此,在上述文件夹中肯定能找到相关定义。同时,我们也知道,Swift 可以为 Protocol 添加默认实现。也许找到 Comparable 定义的地方,就能找到答案。
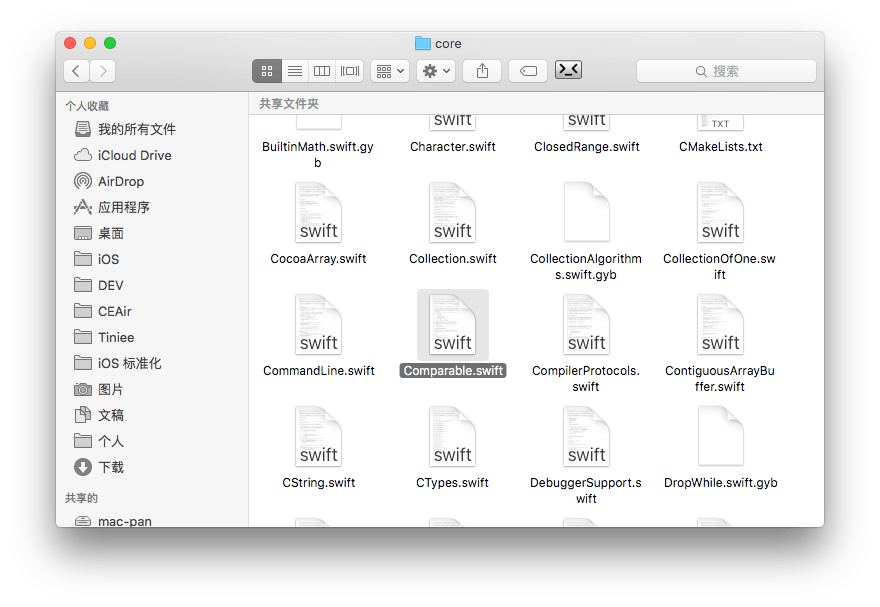
在 String.swift 的同目录下,我们发现了 Comparable.swift 文件,打开文件,我们发现了熟悉的 Comparable 协议的定义,以及最关键的,默认实现:
public func > <T : Comparable>(lhs: T, rhs: T) -> Bool {
return rhs < lhs
}
public func <= <T : Comparable>(lhs: T, rhs: T) -> Bool {
return !(rhs < lhs)
}
public func >= <T : Comparable>(lhs: T, rhs: T) -> Bool {
return !(lhs < rhs)
}
可以看到这里只有针对 >,<=,>= 的实现,并且这些实现都是依赖 < 的实现。这一点印证了接口文档中 Apple 关于严格全序和如何在子类实现 Comparable 的说法。
A type conforming toComparableneed only supply the<and==operators; default implementations of<=,>,>=, and!=are supplied by the standard library
走弯路
那么 < 的实现又在哪儿?
纵览 Comparable 的源码中的文档,基本上是设计思想和使用说明,只字未提 < 的实现。
我们继续翻阅标准库中的文件,在 optinal.swift 等文件中,都有对 == 的重载,但 Command + 左键点击无法跳转到原始实现。一番寻找后,在 Policy.swift 中找到 < 的定义
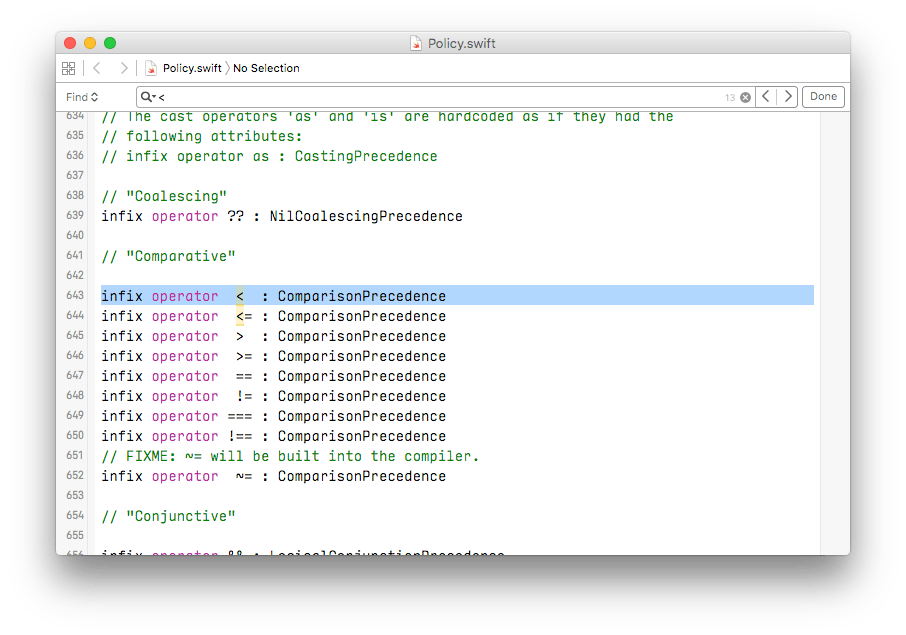
似乎 ComparisonPrecedence 是关键所在。由于是打开单个文件,无法点击跳转到 ComparisonPrecedence 的定义。联想到 Swift 的 README 中说过,可以通过 utils/build-script -x 来将源码构建成 Xcode 工程,那样看起来会方便许多。但考虑到需要安装 CMake、Ninja 等一系列环境,所花费的时间对于解决这个问题来说不划算。先去
Google 搜索一下答案。
通过 Google 找到了 NSHipster 的 Swift Operators,也仔细阅读了 The Swift Programming Language (Swift 2.2),均没有收获。
转机
就在一筹莫展的时候,想到标准库的源码还没翻完,于是继续一个个地浏览标准库的文件。其中一个文件名让人眼前一亮:
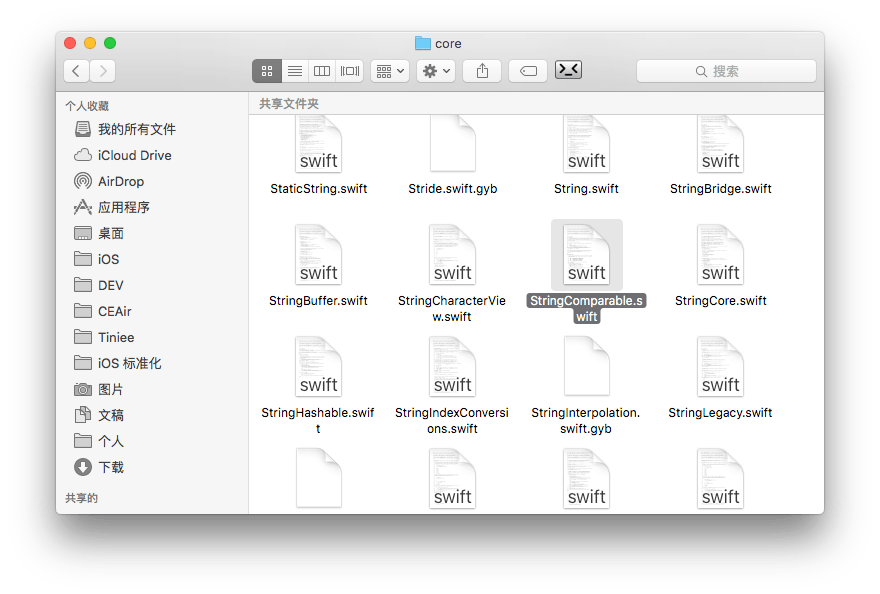
我们找到了 String 关于 Comparable 的实现!
extension String : Comparable {
public static func < (lhs: String, rhs: String) -> Bool {
return lhs._compareString(rhs) < 0
}
}
String 的 < 实现依赖于 Int 的 < 实现。通过 _compareString 生成的整数和 0 比较。至此,我们忽然明白,Swift 标准库中,Comparable 本身并没有提供默认的 < 实现,而是由 String 和 Int 各自提供了 < 的实现。
整数的比较非常好理解了,我们来看看关键的 _compareString 方法是怎么实现的
func _compareString(_ rhs: String) -> Int {
#if _runtime(_ObjC)
// We only want to perform this optimization on objc runtimes. Elsewhere,
// we will make it follow the unicode collation algorithm even for ASCII.
if _core.isASCII && rhs._core.isASCII {
return _compareASCII(rhs)
}
#endif
return _compareDeterministicUnicodeCollation(rhs)
}
}
这个方法对 Objective-C 下的 ASCII 编码的字符串对比做了优化,剩余情况都采用 _compareDeterministicUnicodeCollation 来做比较。
顺藤摸瓜继续看 _compareDeterministicUnicodeCollation 的实现。
func _compareDeterministicUnicodeCollation(_ rhs: String) -> Int {
// Note: this operation should be consistent with equality comparison of
// Character.
#if _runtime(_ObjC)
if self._core.hasContiguousStorage && rhs._core.hasContiguousStorage {
let lhsStr = _NSContiguousString(self._core)
let rhsStr = _NSContiguousString(rhs._core)
let res = lhsStr._unsafeWithNotEscapedSelfPointerPair(rhsStr) {
return Int(
_stdlib_compareNSStringDeterministicUnicodeCollationPointer($0, $1))
}
return res
}
return Int(_stdlib_compareNSStringDeterministicUnicodeCollation(
_bridgeToObjectiveCImpl(), rhs._bridgeToObjectiveCImpl()))
#else
switch (_core.isASCII, rhs._core.isASCII) {
case (true, false):
return Int(_swift_stdlib_unicode_compare_utf8_utf16(
_core.startASCII, Int32(_core.count),
rhs._core.startUTF16, Int32(rhs._core.count)))
case (false, true):
// Just invert it and recurse for this case.
return -rhs._compareDeterministicUnicodeCollation(self)
case (false, false):
return Int(_swift_stdlib_unicode_compare_utf16_utf16(
_core.startUTF16, Int32(_core.count),
rhs._core.startUTF16, Int32(rhs._core.count)))
case (true, true):
return Int(_swift_stdlib_unicode_compare_utf8_utf8(
_core.startASCII, Int32(_core.count),
rhs._core.startASCII, Int32(rhs._core.count)))
}
#endif
}
我们略过优化,直接看关键的两个方法: _stdlib_compareNSStringDeterministicUnicodeCollationPointer 和 _swift_stdlib_unicode_compare_utf8_utf8
看方法名,大概知道如下信息:
在 Objective - C 下,比较两个 String 的 Unicode 集合指针。
在 Swift 下,通过字符串的起始位置指针和字符串的长度综合比较。那么究竟是怎么综合比较的呢?(原来和长度还是有关系的,看来前面的猜测不全对)。
通过方法名中_swift_stdlib的前缀,我们猜测这个方法可能也是 Swift 标准库中的一员。经过一番查找,我们在 /stdlib/public/stubs 路径下的 UnicodeNormalization.cpp 文件的 173 行找到了这个方法。
/// Compares the strings via the Unicode Collation Algorithm on the root locale.
/// Results are the usual string comparison results:
/// <0 the left string is less than the right string.
/// ==0 the strings are equal according to their collation.
/// >0 the left string is greater than the right string.
int32_t
swift::_swift_stdlib_unicode_compare_utf8_utf8(const unsigned char *LeftString,
int32_t LeftLength,
const unsigned char *RightString,
int32_t RightLength) {
UCharIterator LeftIterator;
UCharIterator RightIterator;
UErrorCode ErrorCode = U_ZERO_ERROR;
uiter_setUTF8(&LeftIterator, reinterpret_cast<const char *>(LeftString), LeftLength);
uiter_setUTF8(&RightIterator, reinterpret_cast<const char *>(RightString), RightLength);
uint32_t Diff = ucol_strcollIter(GetRootCollator(),
&LeftIterator, &RightIterator, &ErrorCode);
if (U_FAILURE(ErrorCode)) {
swift::crash("ucol_strcollIter: Unexpected error doing utf8<->utf8 string comparison.");
}
return Diff;
}
代码里的关键算法是 ucol_strcollIter。但到这里,其实我们已经不再需要在源代码中继续翻找了,注释已经给出了答案 -- 通过 Unicode 对照算法来比较两个字符串,结果小于 0 ,则代表左边的字符串小于右边,反之亦然。如果结果等于 0 则代表两个字符串在该对照算法下是相等的。
为了补充一下知识,我们再来看看 Unicode Collation Algorithm 的主算法。
主算法分四步
- 标准化字符串
- 为每个标准化后的字符串生成对照元素数组
- 根据对照元素数组,生成二进制的排序 Key
- 通过对比二进制数据的大小,其结果就是原字符串的"大小"。
算法这块不过多展开, ucol_strcollIter 函数的实现看这里,有兴趣的朋友可以深入研究。
总结
Swift 下字符串的比较是通过计算机科学领域标准的 Unicode 对照算法来的。在不了解算法的情况下,很难从字面上看出两个字符串谁大谁小。因此在日常开发下,应当尽量避免比较两个字符串"谁大谁小"。
Swift 以是否具有统一码等价性 作为判断字符相等的标准。因此在比较两个字符串相等的时候,也需要多考虑细,来避免产生不必要的 BUG。
