

Ps1:主要答疑区在本帖最下方,疑点会标注出来。个人在配置过程中遇到的困难都会此列举。
Ps2:本帖也是我自己原创的,最近从CSDN搬家过来。原帖地址
实验介绍:
本次实验主要介绍了Hadoop平台的两个核心工具,HDFS和Mapreduce,结合这两个核心在Linux下搭建基于YARN集群的全分布模式的Hadoop架构。
实验案例,基于Hadoop平台下的Wordcount分词统计的试验
实验需求:
1、PC机,局域网服务,Linux系统
背景介绍:
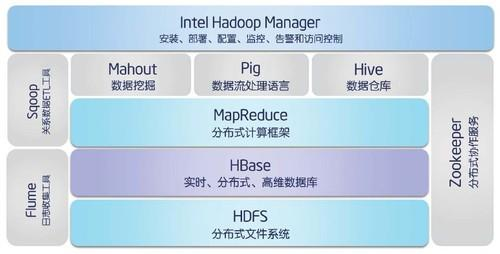
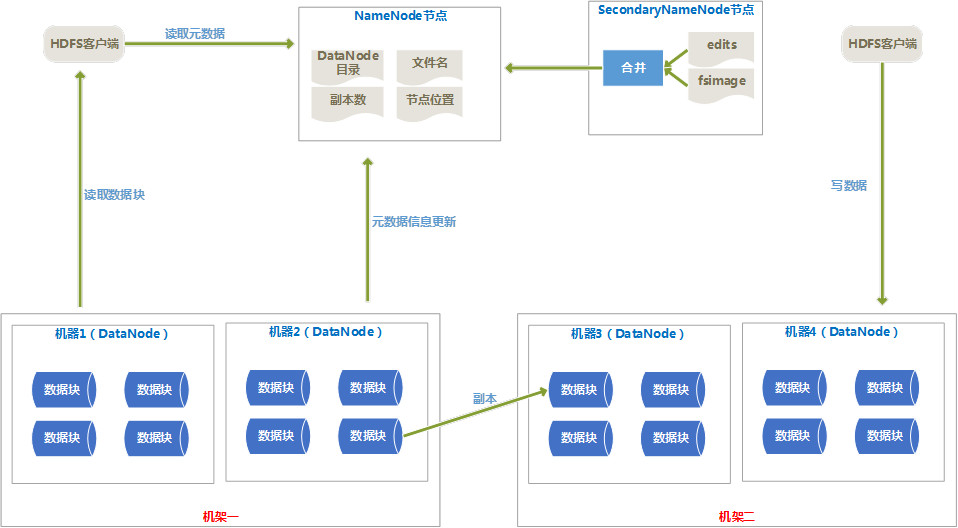
NameNode
DataNode
实验步骤及结果:
1.搭建平台(全分布式hadoop + eclipse Neon.1 + JDK1.8)
集群搭建:
主机两台(可拓展):
(1)两个主机系统均为Ubuntu 16.04 LTS
详情:
master 192.168.:103.26(虚拟机)
slave2 192.168.103.22(物理机)
注:
(1)slave1是在同学的笔记本上,因为他的笔记本总是飘忽不定,所以这次博客上就先不写他的ip地址
(2)master是虚拟机的理由就是第一次尝试怕配错环境,导致崩溃,所以用了VMware为master,方便拯救平台
(2)hadoop平台版本都为最新稳定版2.7.3(解压及安装hadoop)
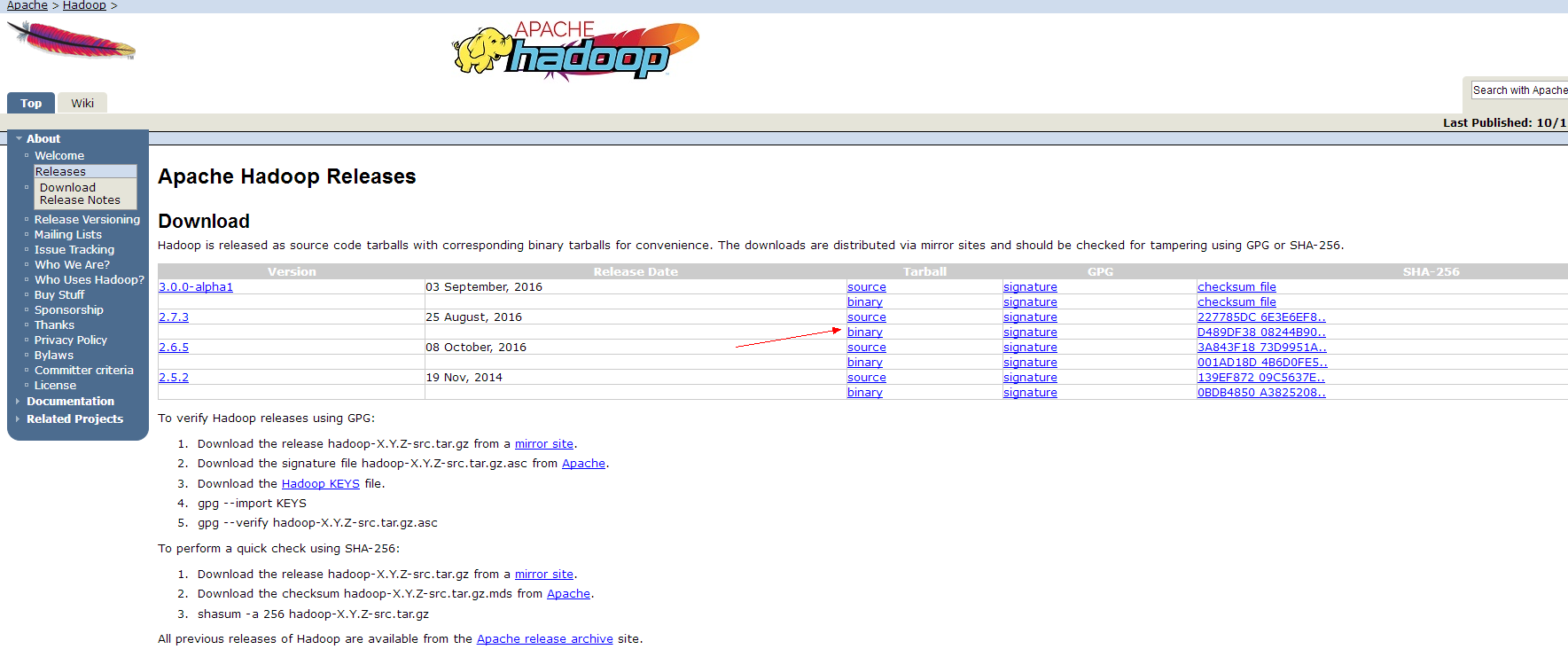
下载地址:Hadoop官网 hadoop.apache.org/releases.ht…
步骤1:点开网页以后,点击红色箭头所指的链接
步骤2:点开后如下图
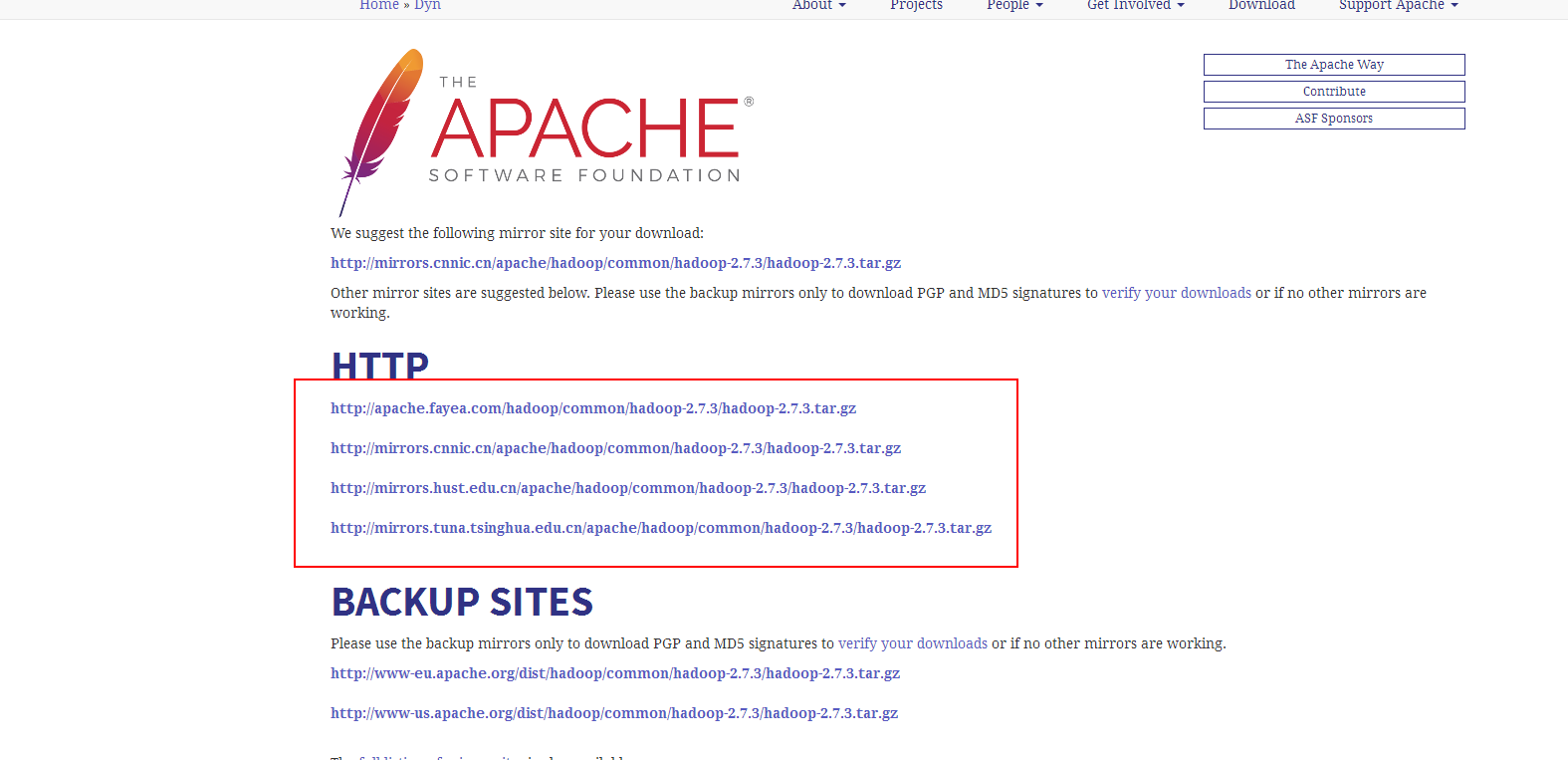
步骤3:选择一个链接下载(个人推荐最后一个 tsinghua.edu.cn 清华大学链接源比较好)
步骤4:下载完后打开文件管理器,选择Downloads文件夹(如果修改主要文件夹名字为中文的,应选择“下载”)
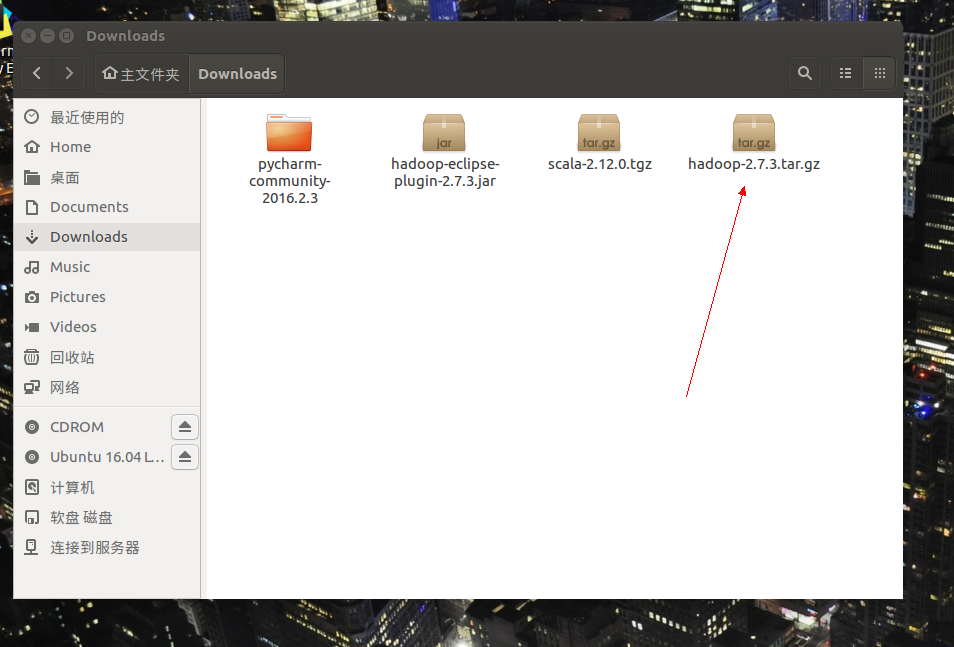
步骤5:解压到指定路径
步骤5.1:在当前文件夹下右键 - 在终端打开 键入su root命令
步骤5.2:输入root用户密码后,如下图所示
步骤5.3:键入解压命令
sudo tar zxvf hadoop-2.7.3.tar.gz -C /usr/local/hadoop
(注意:如果提示hadoop文件夹不存在的,可以在root用户下用cd命令到 /usr/local路径下 键入 sudo mkdir /hadoop 创建夹)
步骤5.4:解压后如下图所示
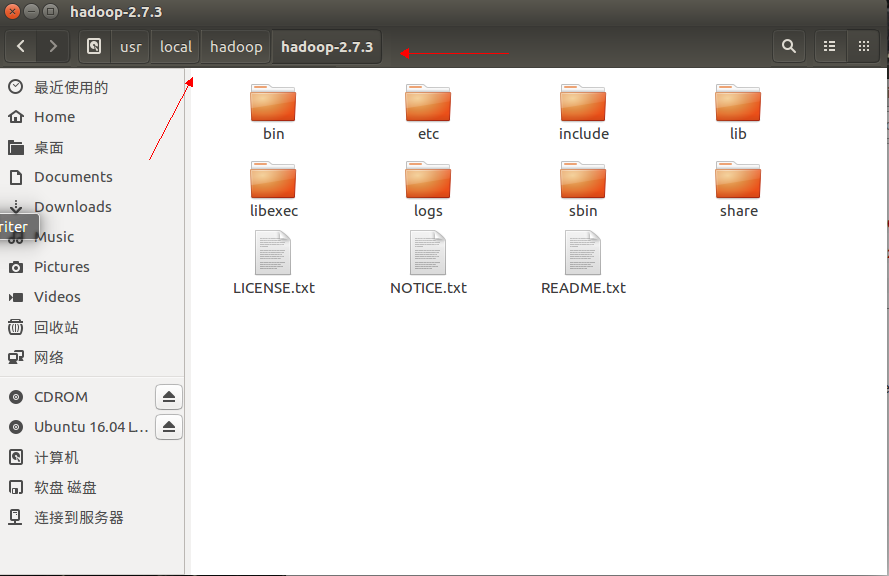
(注意:路径满足如图所示即可,或自行定义)
至此hadoop前期下载准备工作已经完成。接下准备java环境的配置
(3)JDK版本为java8-oracle(配置java环境)
(环境:系统稳定联网状态下)
步骤1:打开终端键入命令(root用户模式可以不用加sudo前缀)
sudo add-apt-repository ppa:webupd8team/java步骤2:出现一段文字后按回车继续
步骤3:继续键入命令
sudo apt-get update步骤4:待系统加载完所有下载源
步骤5:键入安装命令
sudo apt-get install oracle-java8-installer步骤6:等待下载结束(过程稍微有点漫长)
这个版本的java默认安装在 /usr/lib/jvm文件夹下
安装结束后配置环境变量
终端输入:
sudo gedit /etc/profile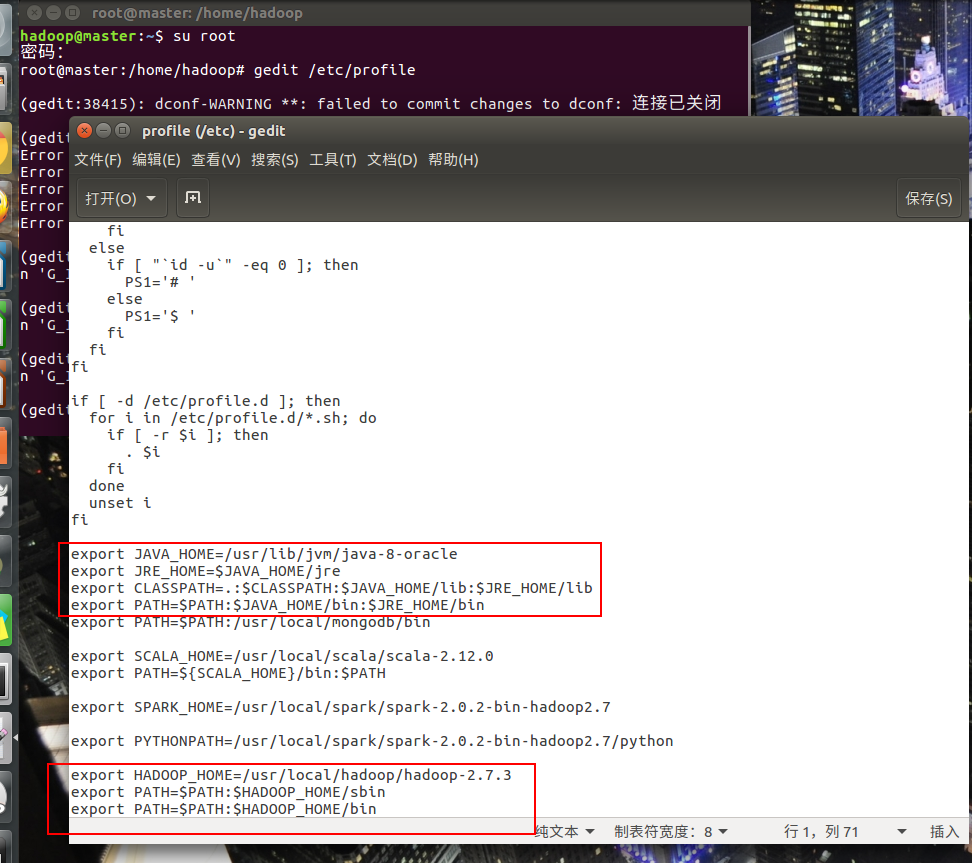
步骤7:配置完后,按 ctrl + s 保存
步骤8:在终端中输入
sudo source /etc/profile使配置的环境变量生效
步骤9:和在Windows下配置一样,在终端测试java和javac命令是否生效,在linux下可以多测试下jps命令看java进程号
至此java环境变量配置完毕
(4)SSH免密配置
SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。
SSH在正确使用时可弥补网络中的漏洞。SSH客户端适用于多种平台。
Ubuntu Linux下配置免密登录主要依靠 ssh localhost的命令
!!注意,如果改过 /etc/hosts 下的内容需要重新配置(下图是我的例子)
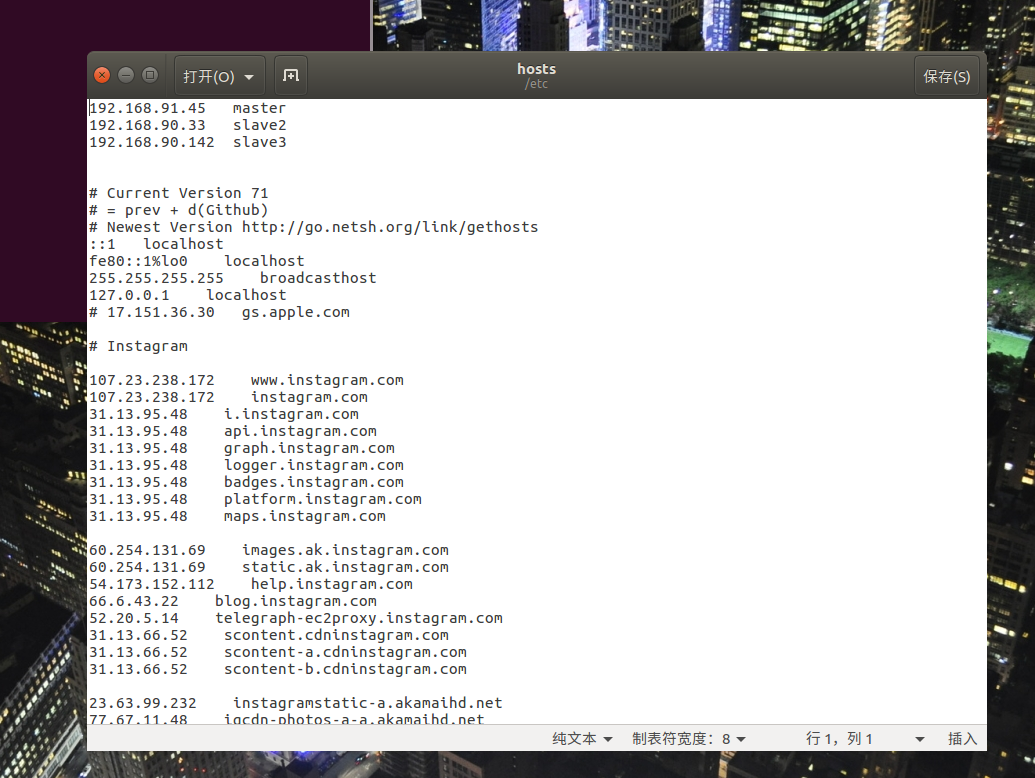
由于后期为了避免hadoop的一些端口和IP错误,所以我把localhost的名字改了,顺带把 /etc/hostname 的名字也改了。
改了上述的 hosts 和 hostname的名字后,记得重启电脑或者虚拟机
192.168.91.45是我虚拟的IP的地址 名字叫master 相当于 没有改变配置文件之前的 127.0.0.1 localhost
所以配置ssh免密的时候是键入 ssh master 而不是 ssh localhost
话不多说!
步骤0:SSH需要安装OpenSSH-server(如果已经安装则无需理会)
sudo apt-get install openssh-server步骤1:在非root用户模式下打开终端键入ssh localhost(或者是定义的用户名)
步骤2:提示输入密码,输入你的ssh密码(自己记得住就好)
步骤3:输入完以后,测试一下ssh localhost(或是自定义名字),输入密码后是否如下图弹出一些信息
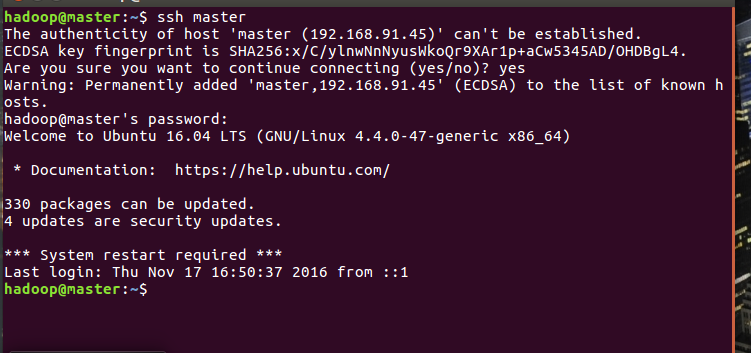
步骤4:如果下午所示后,则创建ssh成功
步骤5:创建免密登录(不需要关闭终端),键入如下命令
ssh-keygen -t rsa
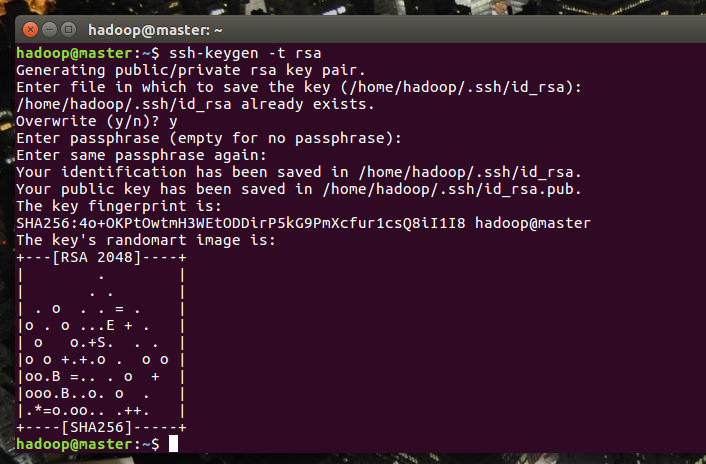
步骤6:一直按回车直至出现RSA窗口即可
步骤7:键入命令
sudo cp .ssh/id_rsa.pub .ssh/authorized_keys步骤8:验证免密登录,输入ssh localhost(或者自定义的名字),是否还需要输入密码登录
root用户下:
步骤1:进入root用户模式(用户模式下在终端键盘入:su root,输入root密码即可)
步骤2:进入ssh配置文件
gedit /etc/ssh/sshd_config
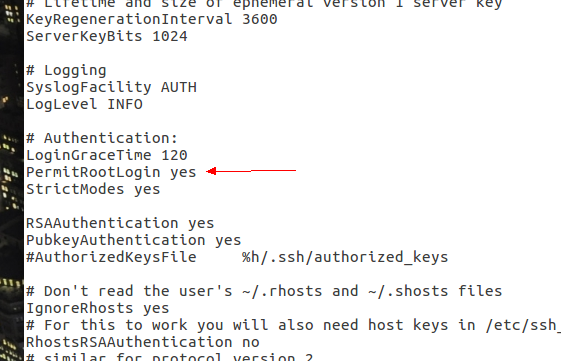
步骤3:把PermitRootLogin的字段改成 yes(原来的好像是Prohibit xxxx的),有点忘记了。总之改成yes就可以了
步骤4:保存退出终端
步骤5:打开新的终端键入命令
sudo service ssh restart重启ssh服务之后,打开终端
步骤6:进入root用户模式下,键入 ssh localhost(或是你的自定义名字)
步骤7:输入自定义ssh密码后,与用户模式下的类似
步骤8:键入 ssh-keygen -t rsa 创建RSA密钥
步骤9:一直回车直至出现RSA密钥图,(如果提示Overwrite 输入 y 即可)
步骤10:键入配置免密的命令
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys步骤11:完成后,在root用户模式输入 ssh localhost(或自定义名字)后,如下图所示即可。
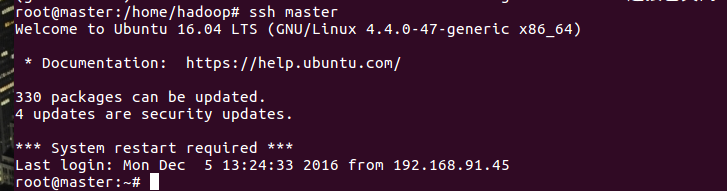
至此,root用户和普通用户模式的ssh免密配置完成。
(4.1)SSH免密配置(节点篇)
需求:如果每个节点都需要下载安装hadoop ,则大量耗费人力物力。
解决:所以需要一个SSH来远程发送hadoop包分发给每个节点。
接下来来讲解master打通每个节点的连接方式(单节点和多节点一样,只要配置好就可以进行连接)
步骤1:在hosts文件中配置好各子节点的ip地址以及名称(如下图)
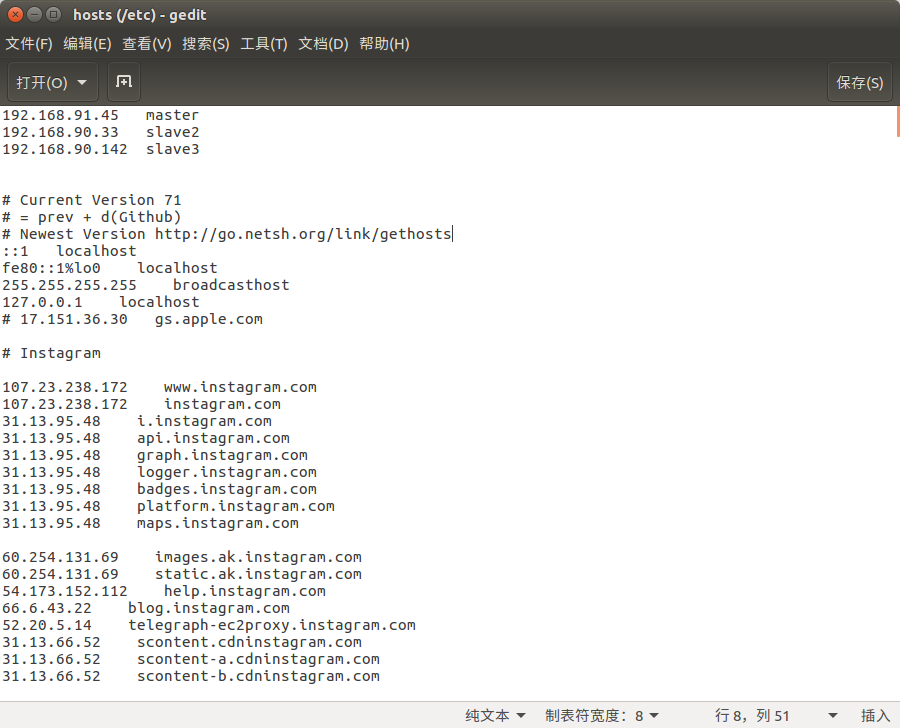
步骤2: 编辑好hosts文件保存并关闭,(root用户模式下)打开终端输入
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave*
(星号代表子节点号码,或者把slave*换成自定义的名称)步骤3:提示输入,子节点的登录密码,输入完成后,等待命令完成
步骤4:在终端中输入 ssh slave*(或者自定义名字),如下图:
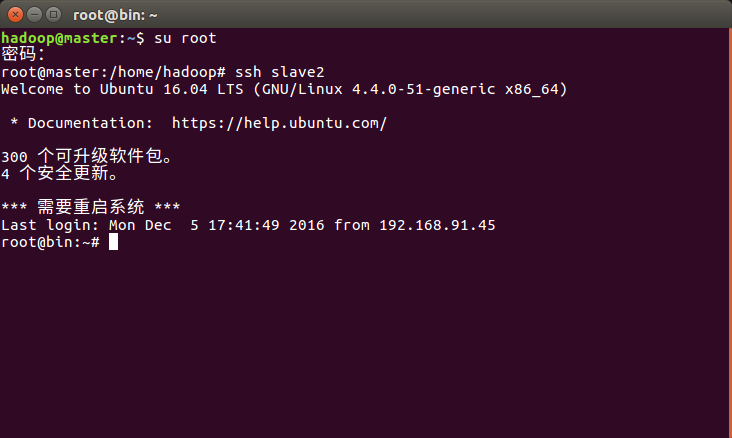
步骤5:ssh打通master和子节点的通道,可以通过scp命令传输数据了。
至此,完成对于子节点的ssh免密访问配置。
(5)hadoop平台版本都为最新稳定版2.7.3(解压及安装hadoop)
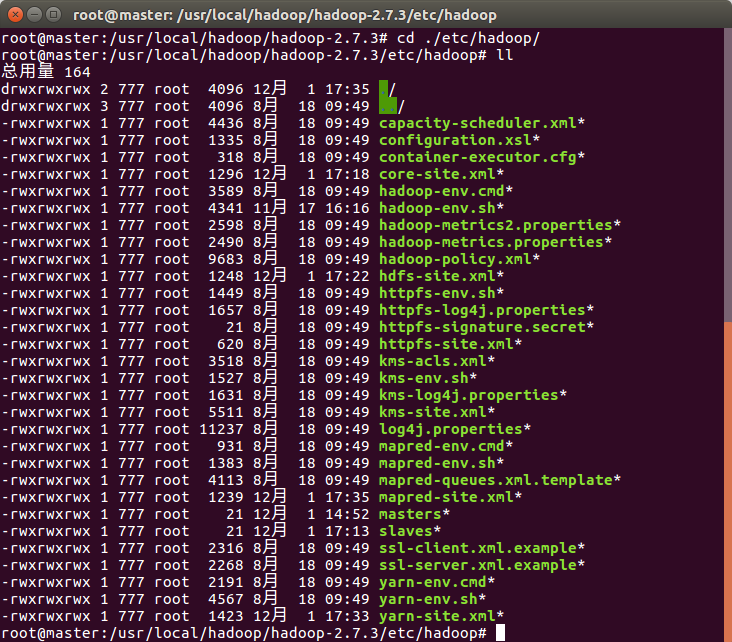
hadoop配置下主要注意配置文件路径的问题
主要包括:hadoop根目录下 /etc/hadoop 里面的xml配置文件
例:hadoop-env.sh , hdfs-site.xml, mapred-site.xml , core-site.xml , yarn-site.xml
注:mapred-site.xml需要复制出来到本路径,原本是mapred-site.xml.template 需要用 cp 命令复制并改名字
或者可以通过 gedit 命令创建一个新的mapred-site.xml,把模板内的内容复制过去,然后再进行配置
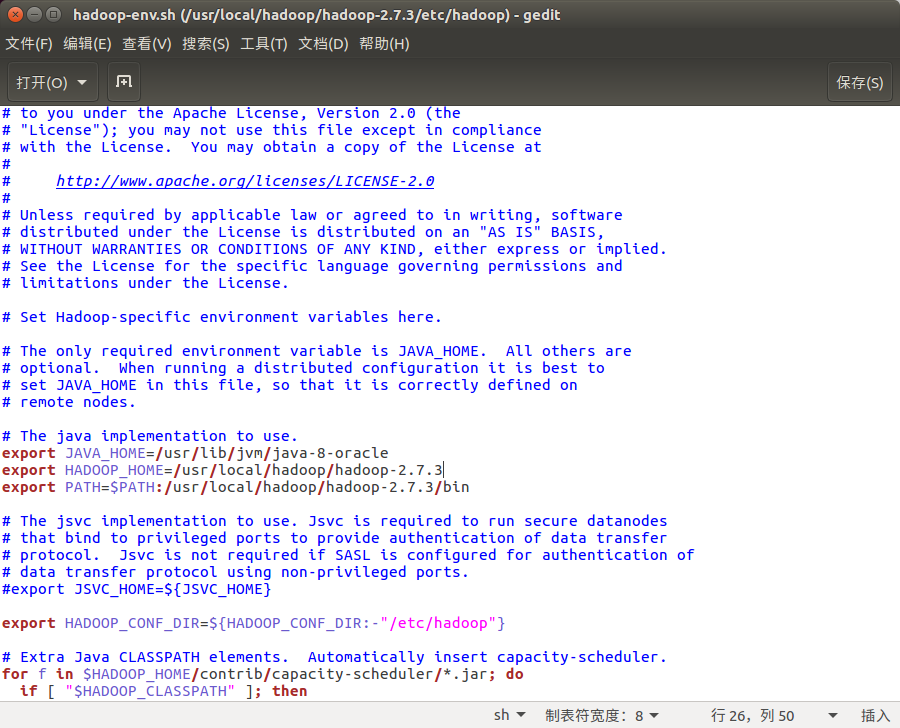
配置文件1:hadoop-env.sh(配置环境变量,让hadoop识别)
配置文件2:core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.group</name>
<value>*</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
配置文件3:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件4: mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置文件5:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
!!!注:如果是master节点(即服务器)需要添加多一个slaves文件指定slave
配置文件6:slaves(选)
slave2 192.168.90.33
最后步骤:以上配置文件配置完毕后打开终端窗口,输入
hadoop namenode -format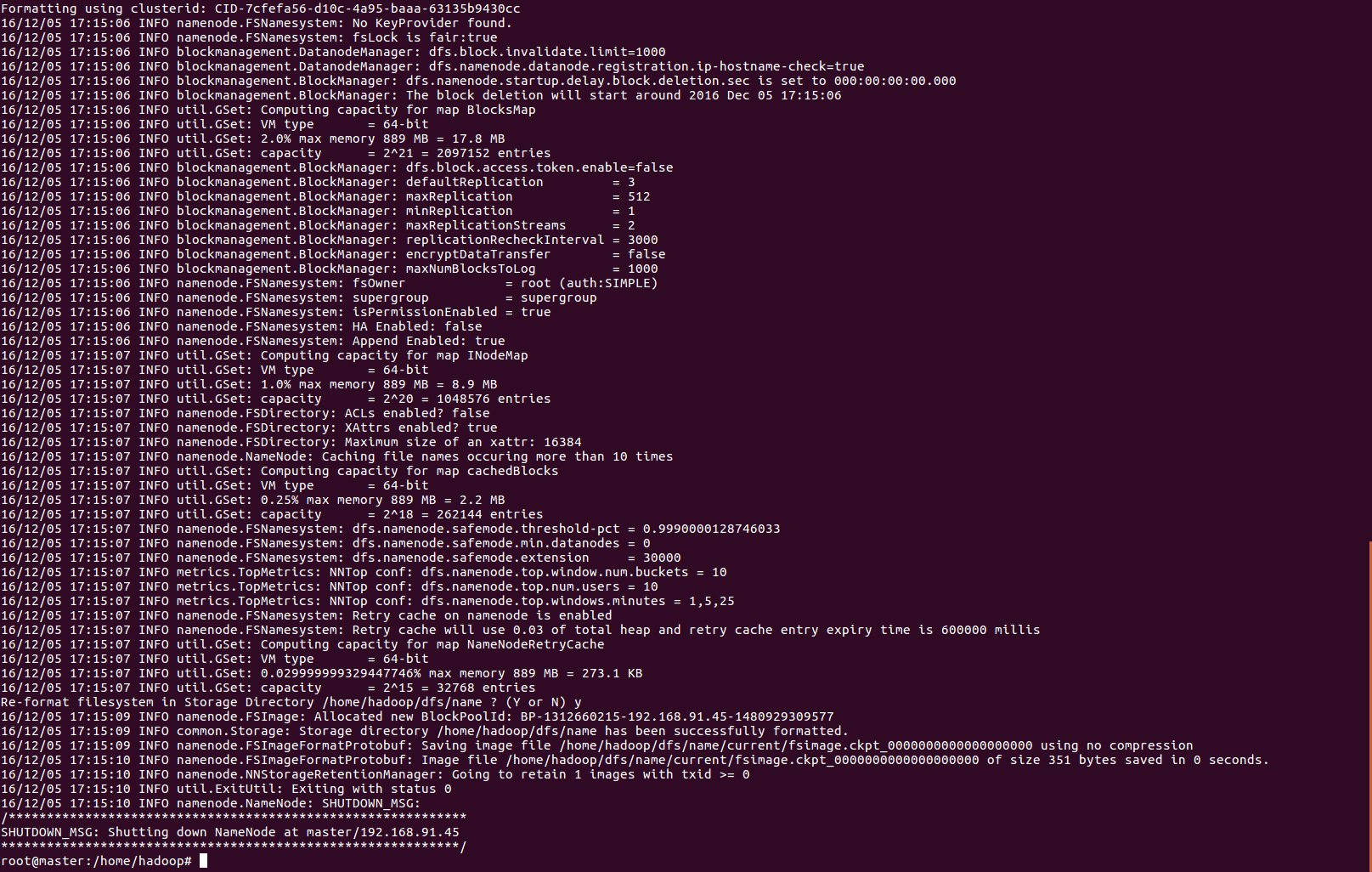
出现如下结果,没有JAVA报错即可
初始化hadoop namenode节点成功!
打开终端利用 cd 命令进入hadoop启动命令文件下
cd /usr/local/hadoop/hadoop-2.7.3/sbin
键入如下命令启动hadoop(root用户模式下)
./start-all.sh关闭hadoop则键入命令关闭
./stop-all.sh
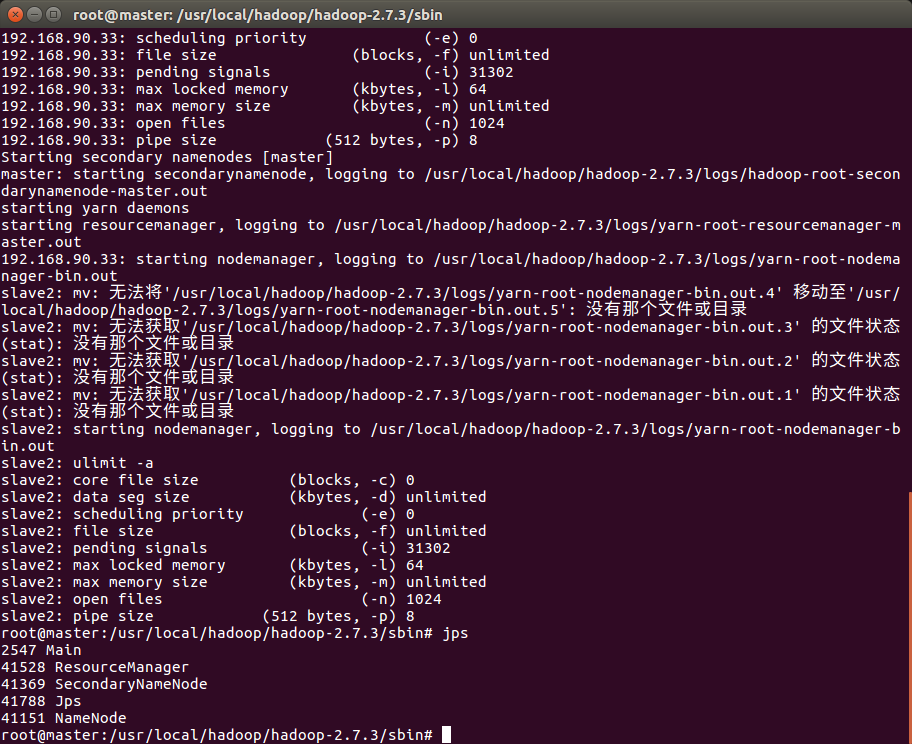
输入jps在master节点测试,如果如上图所示则测试成功
在ssh slave2 节点输入jps测试
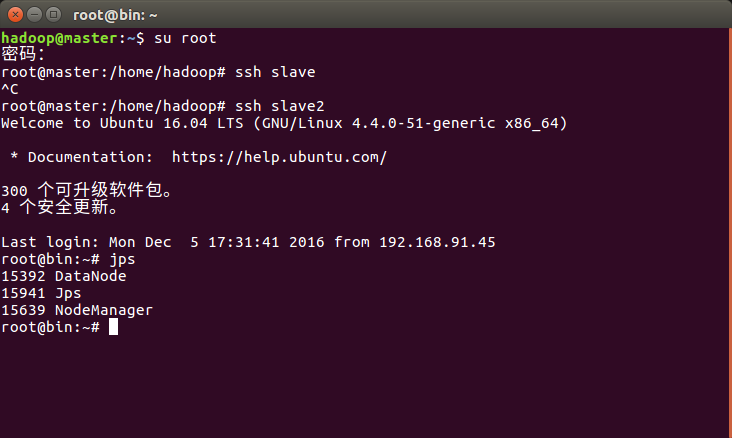
通过hadoop 自带命令
hadoop dfsadmin -report
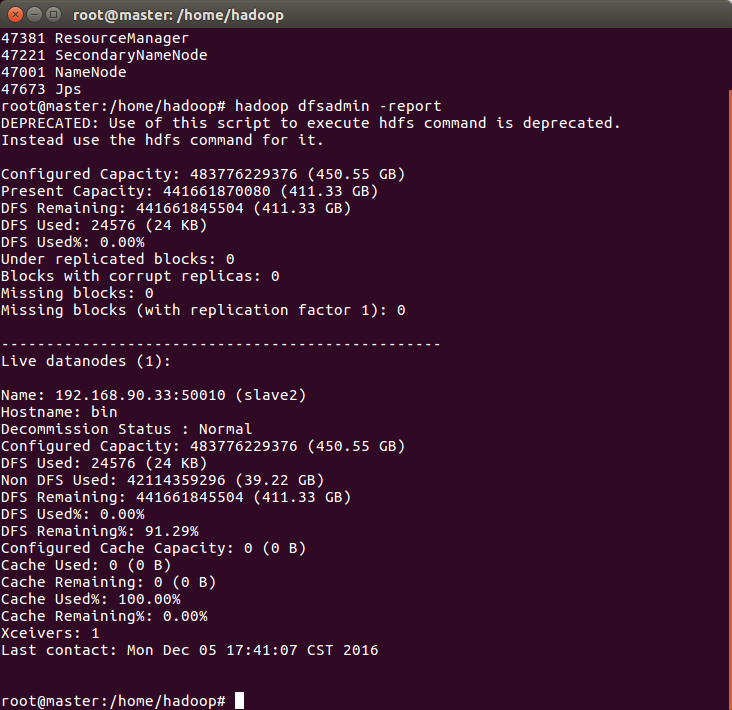
如上图所示输出Live Datanodes,说明有存活节点,死节点为空。
证明集群配置成功!
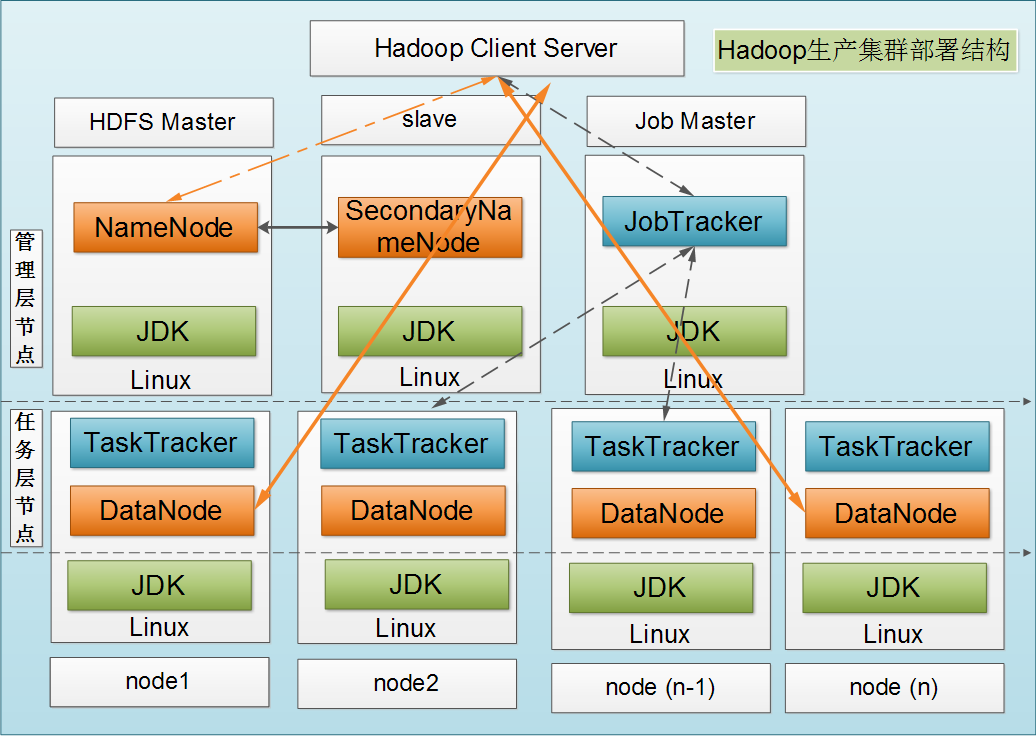
(6)集群安装hadoop(完成Master节点的hadoop安装以及SSH的搭建)
构建好master与各个slave之间的ssh通信,如下图所示
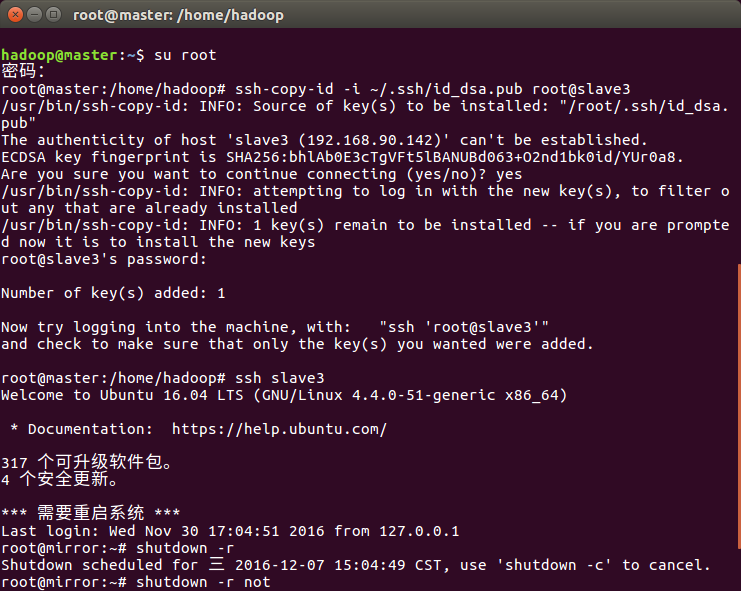
步骤1:测试ssh命令与各节点间的通信
步骤2:确认本机的hadoop安装地址
步骤3:
scp –r /usr/local/hadoop/ root@slaver2:/usr/local/hadoop 把master上的hadoop分发给slave2节点(其他节点依次类推,只要搭好ssh就可以传输)。
传输过程有点久,耐心等候。
步骤4:在slave节点上配置环境变量
HADOOP_HOME=/usr/local/Hadoop PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin步骤5:在master启动hadoop进行测试
Namenode界面 50070端口
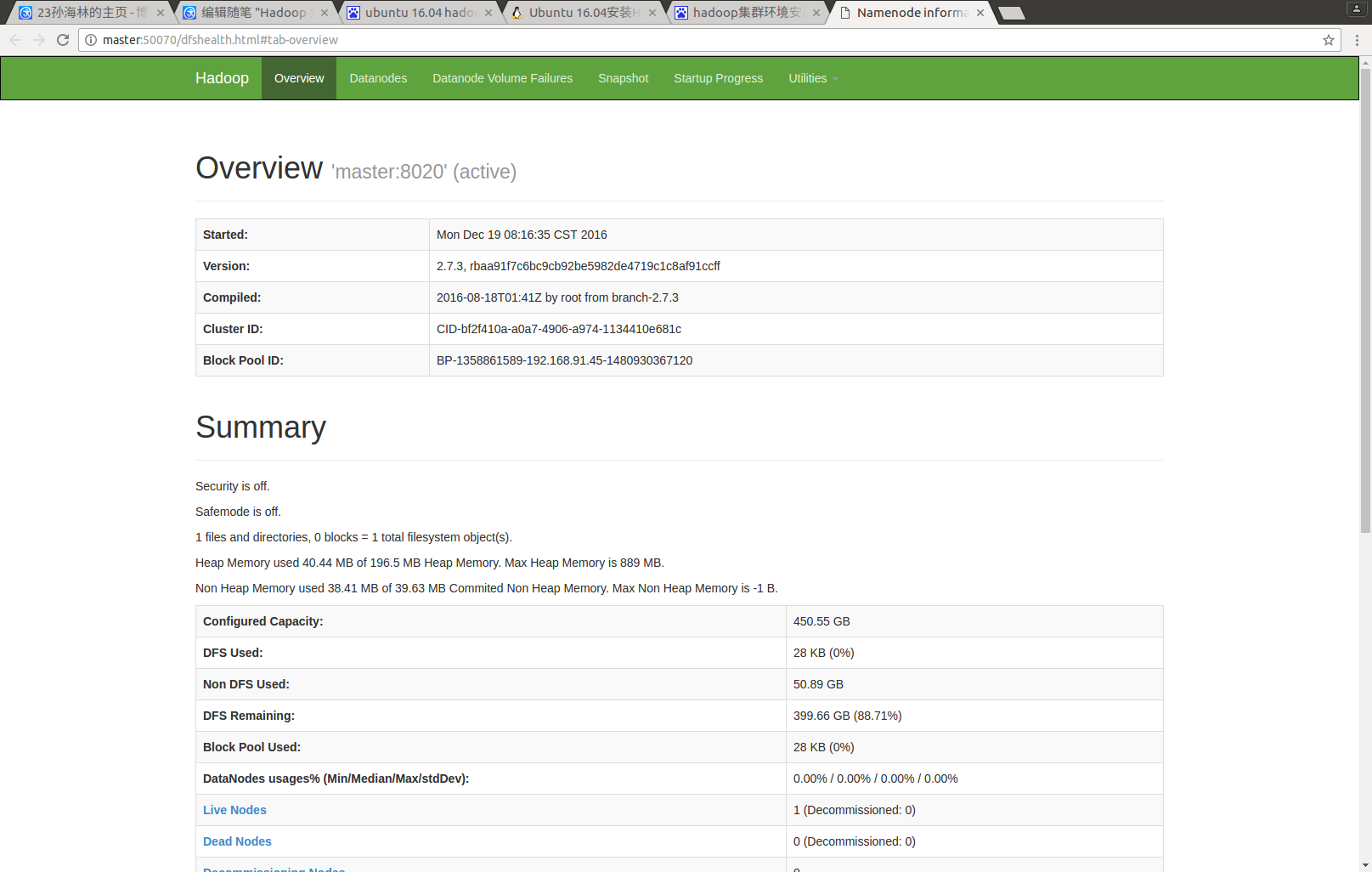
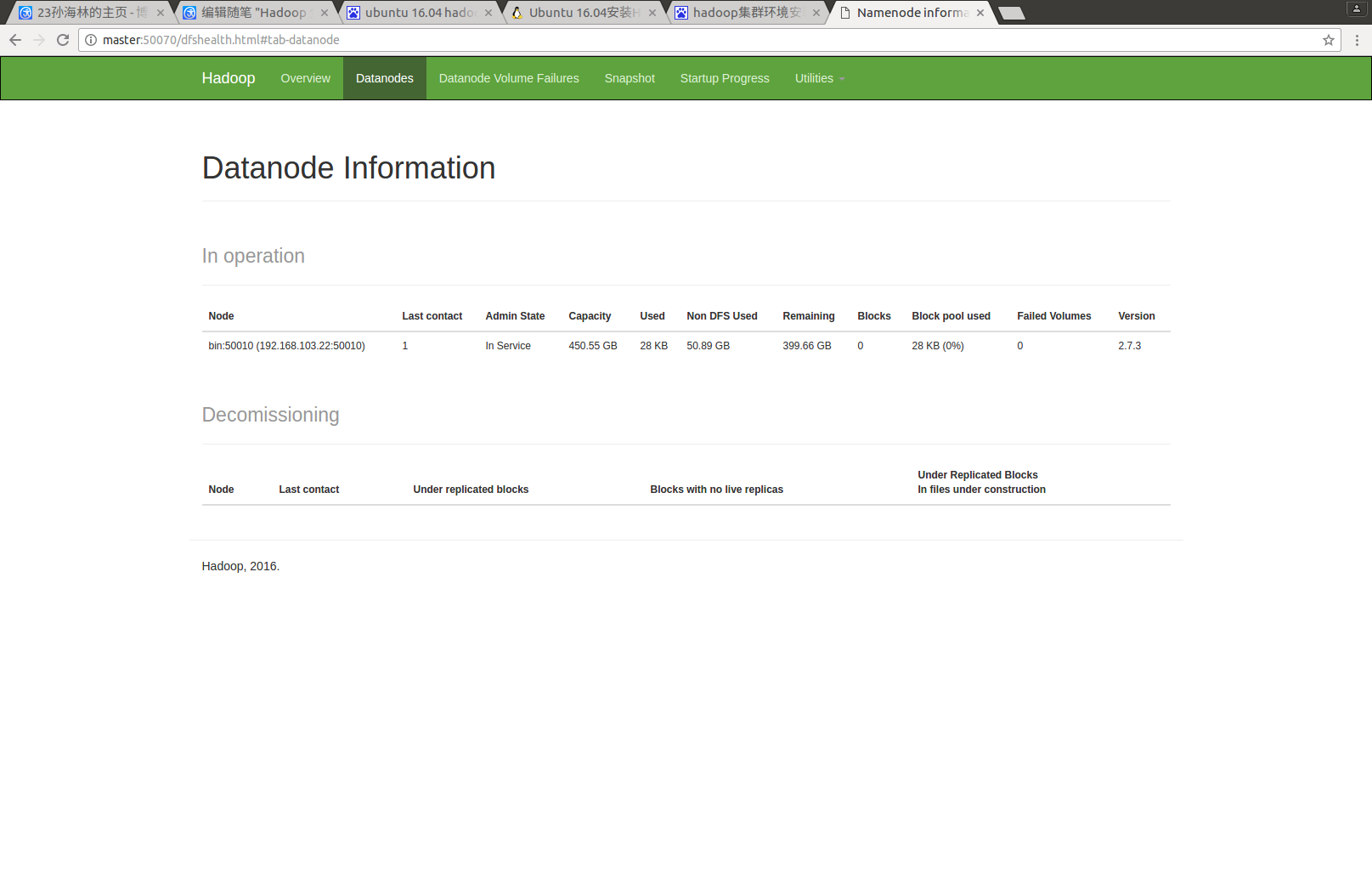
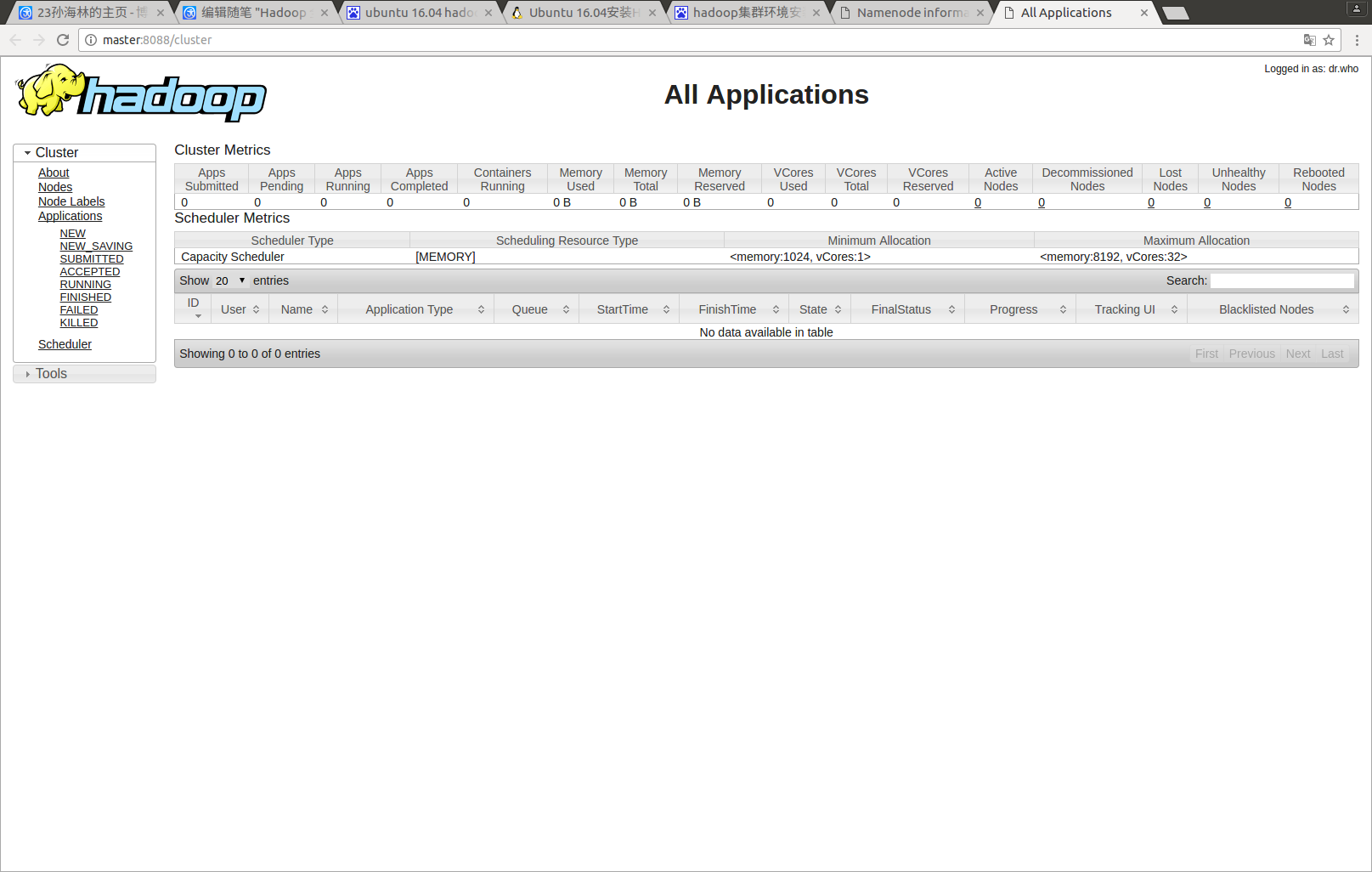
hadoop管理界面 8088端口
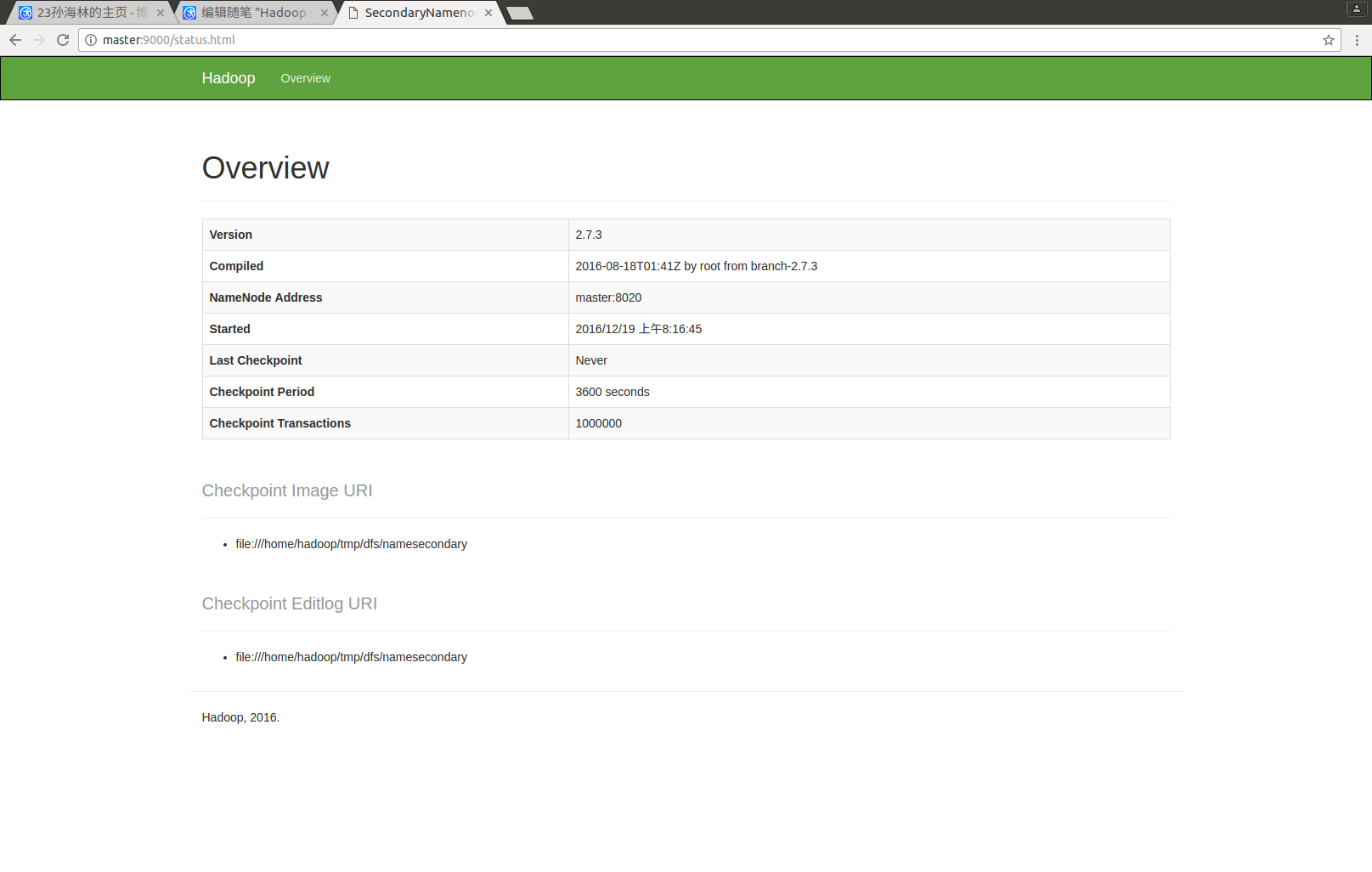
hadoop SecondaryNamenode 管理界面 端口9000
(7)hadoop Wordcount测试(完成eclipse和eclipse hadoop插件安装)
步骤0:安装eclipse和eclipse hadoop插件
步骤0.1:安装eclipse

下载后,解压到自定义路径,解压后如所示
在此给出eclipse hadoop插件下载(pan.baidu.com/s/1mi6UP5I)
下载后,把jar放到eclipse根目录的dropins的目录
在根目录进入终端,进入root用户模式,输入
./eclipse进入eclipse界面,完成安装。
步骤1:启动hadoop完成上述集群测试
步骤2:通过终端把测试数据 test.txt上传到hdfs中 (test.txt为hadoop跟目录下的NOTICE.txt)
步骤2.1:在hdfs目录下创建input文件夹
hadoop fs -mkdir /input
hadoop fs -put test.txt /input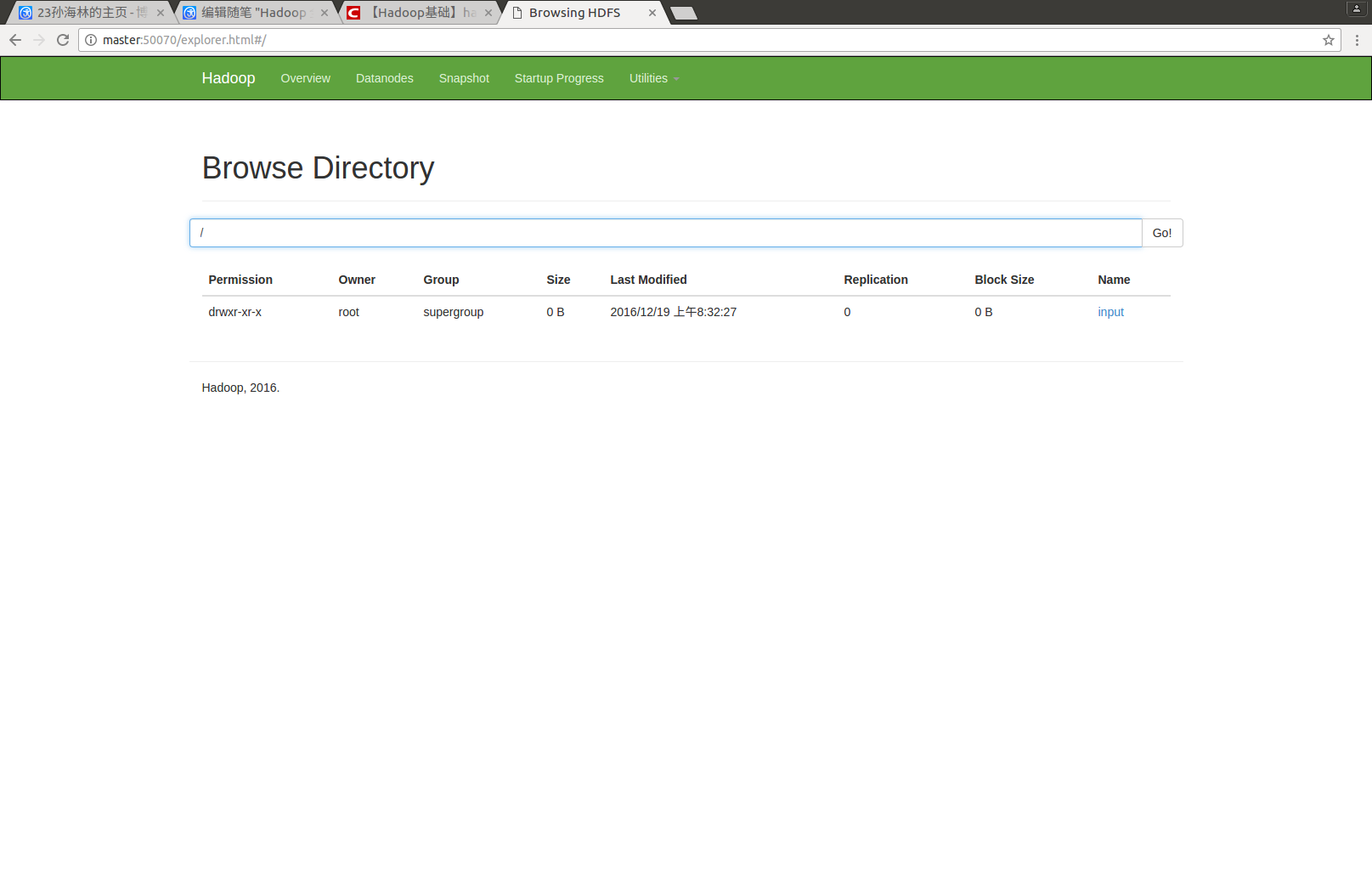
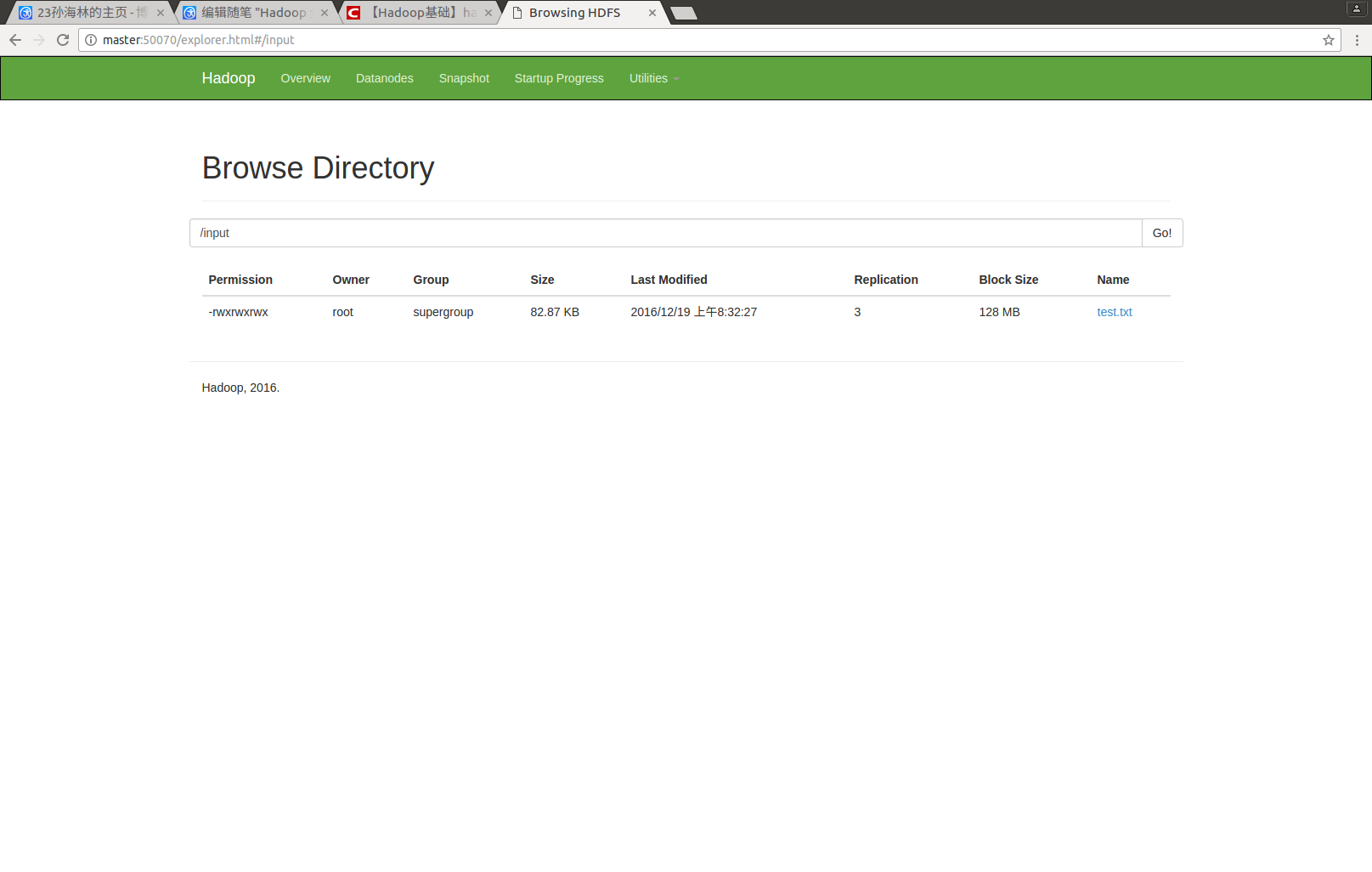
如图所示,则上传成功。
如果权限不对的话可以修改权限
hadoop fs -chmod -R 777 /input/test.txt
步骤3:打开eclipse,并完成mapreduce的wordcount代码,完成eclipse hadoop的配置
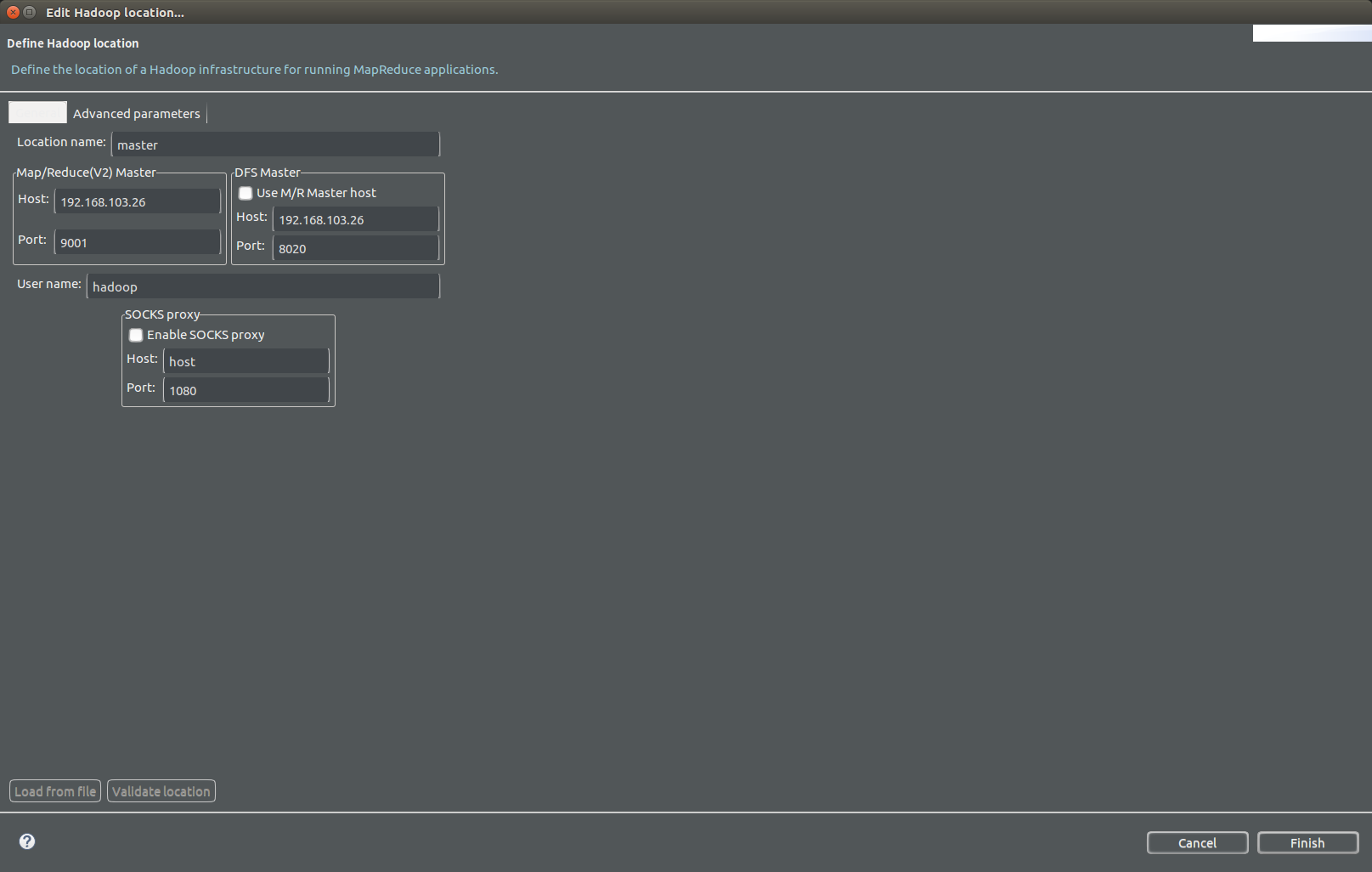
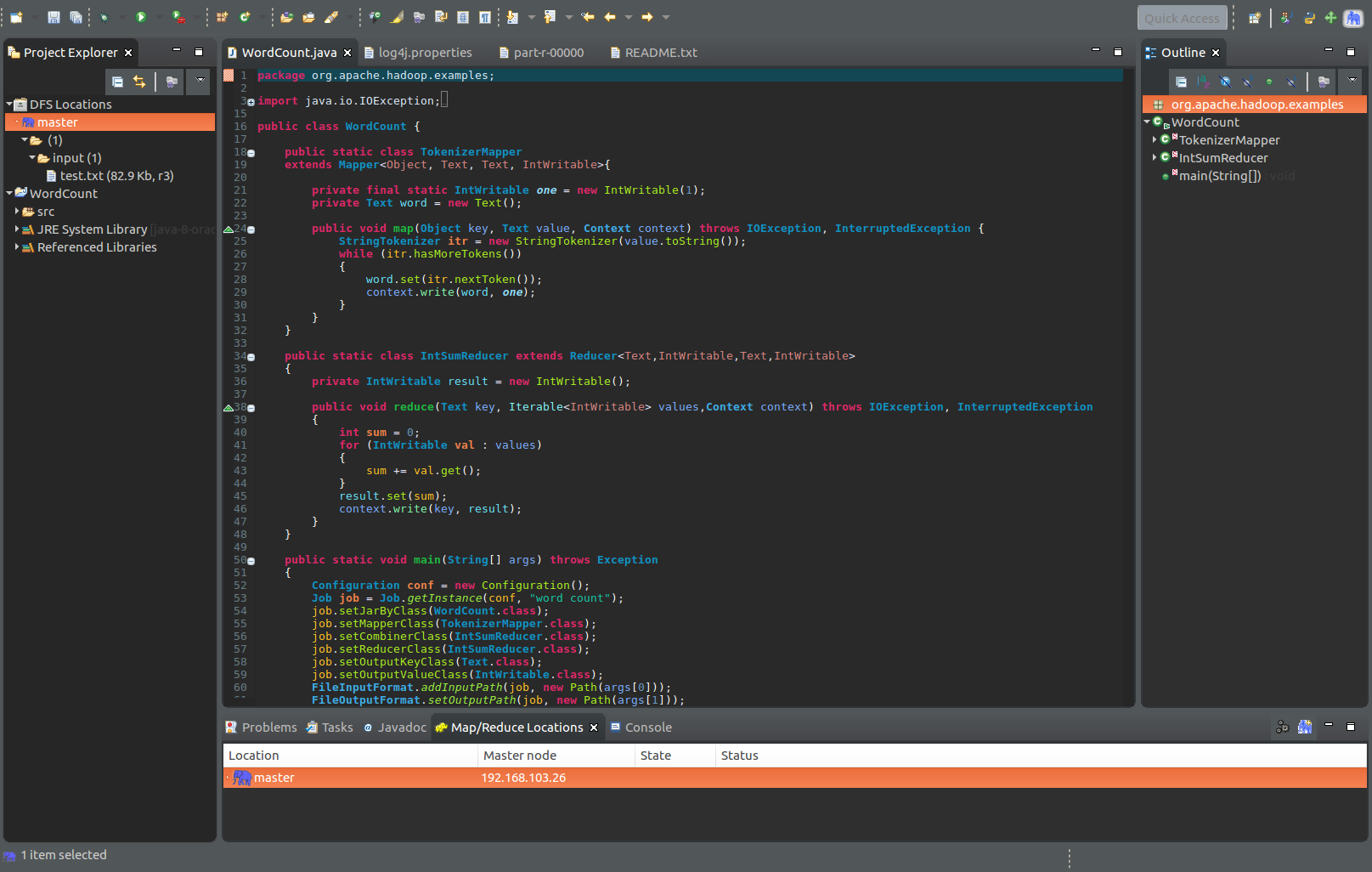
步骤4:确保左上角的DFS Location能够显示hdfs中的文件目录
WordCount代码:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
log4j日志文件:
log4j.rootLogger=debug, stdout, R
#log4j.rootLogger=stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
#log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=log4j.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
#log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.appender.R.layout.ConversionPattern=%d %p [%c] - %m%n
#log4j.logger.com.codefutures=DEBUG
步骤5:配置Run Configuration
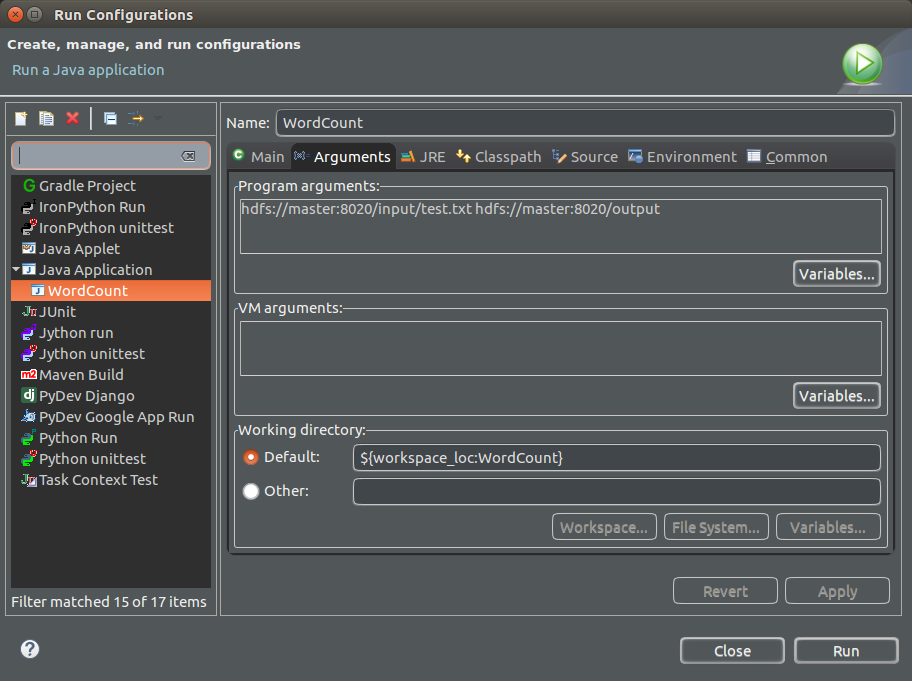
步骤6:右键Run As - Run On Hadoop(日志我选用了DEBUG模式测试,所以会很长,但是方便测试)
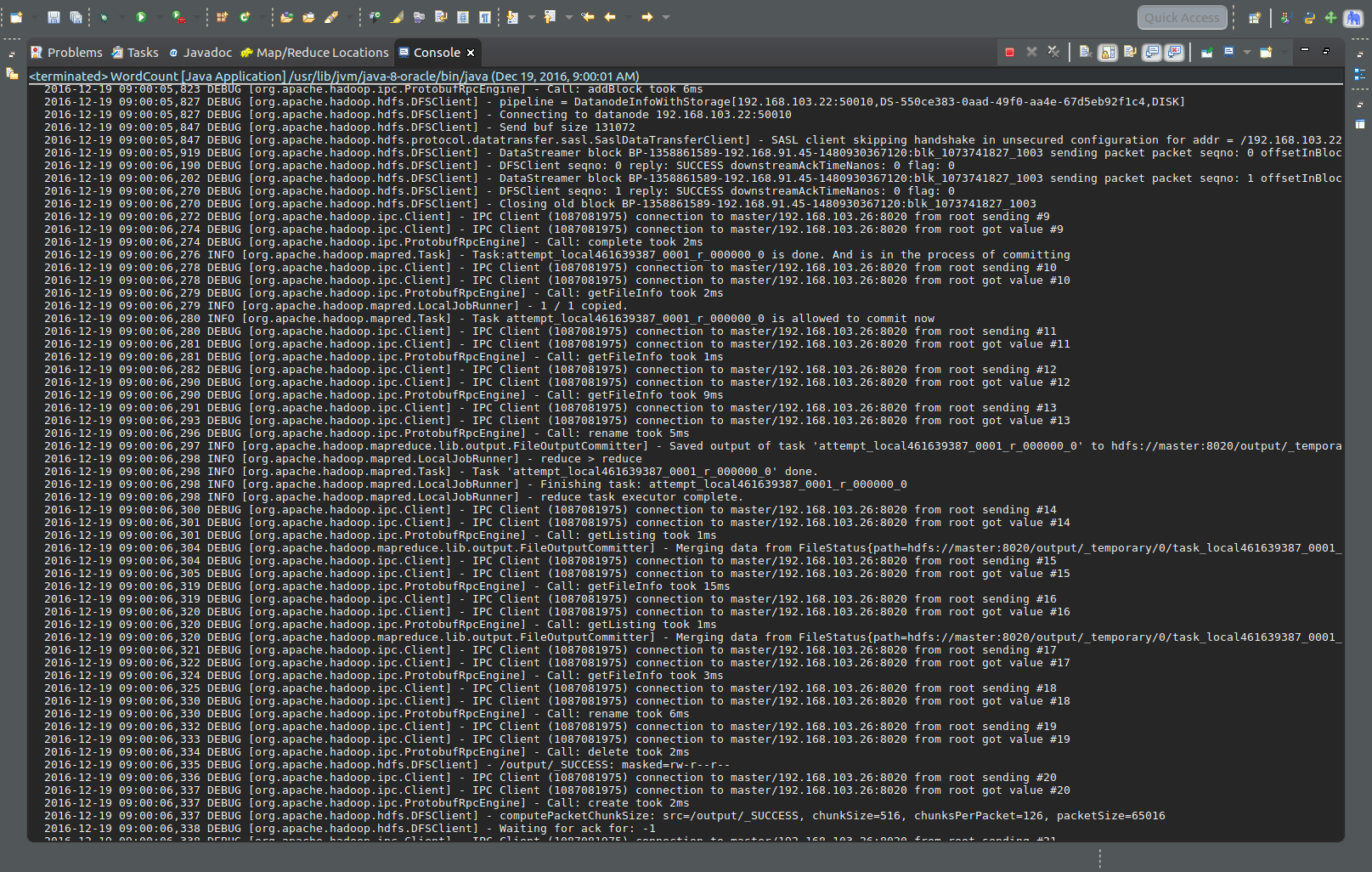
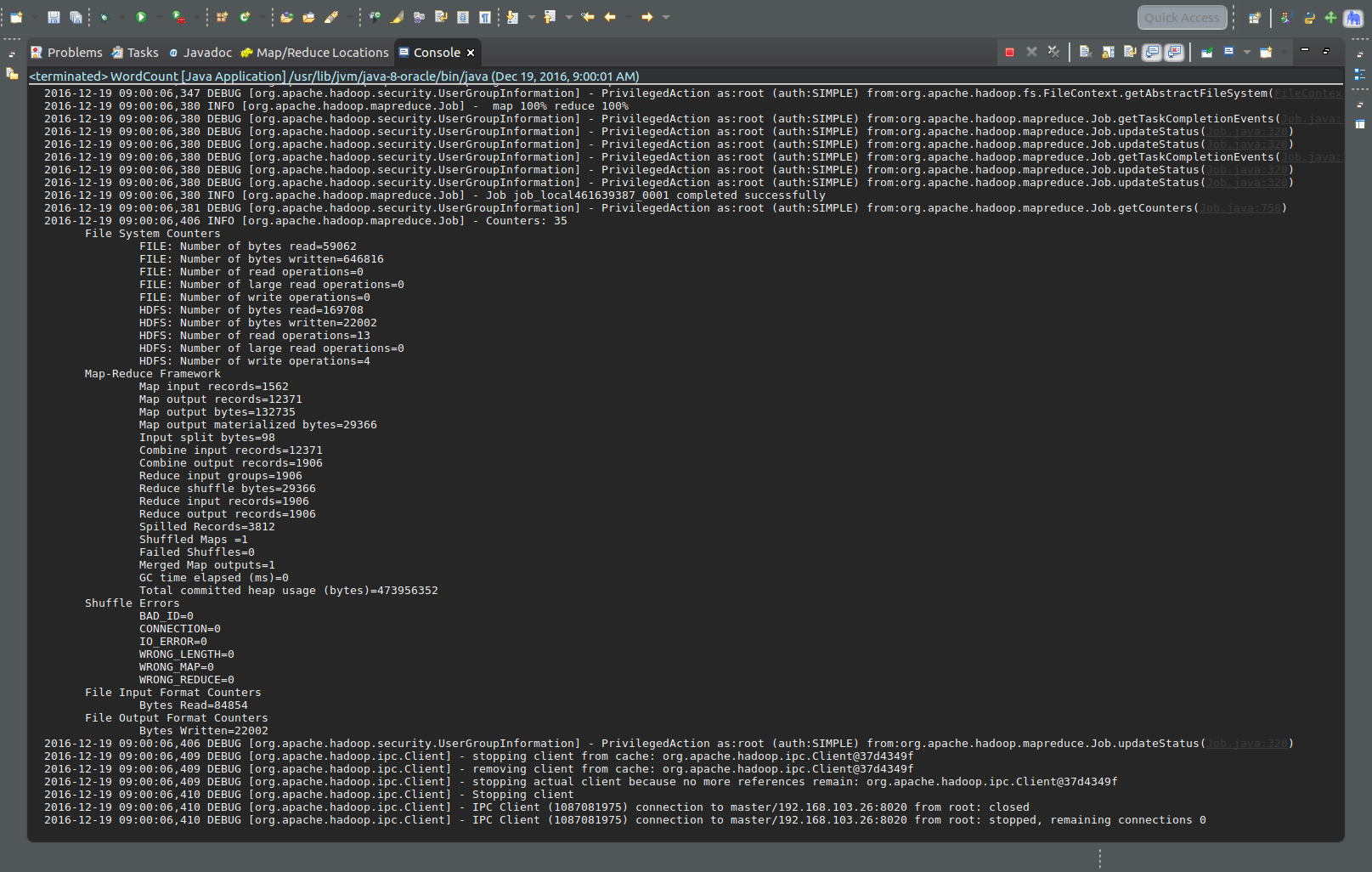
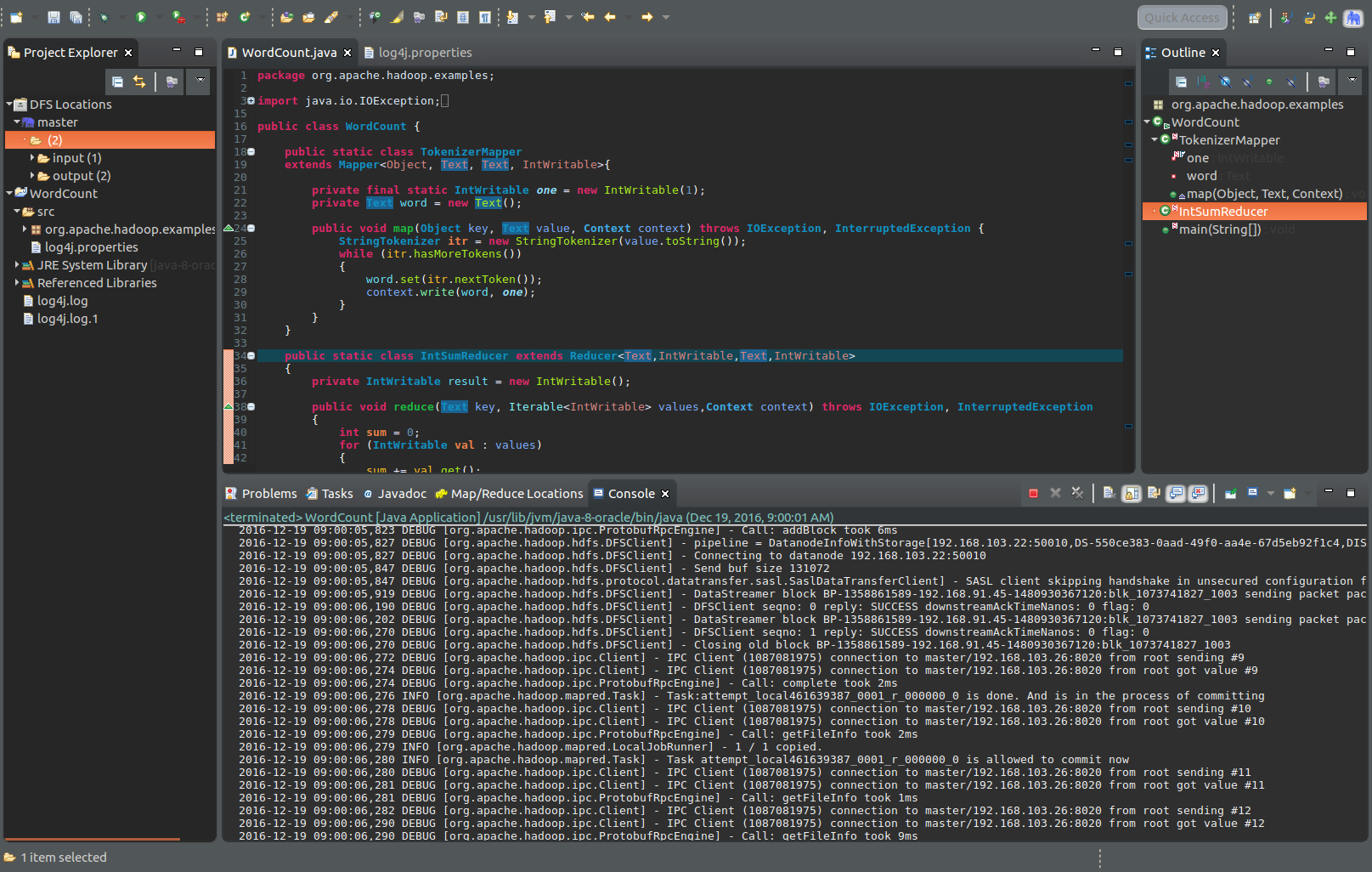
此时,master hdfs多出一个文件夹存放分词结果
下列图为结果部分截图:
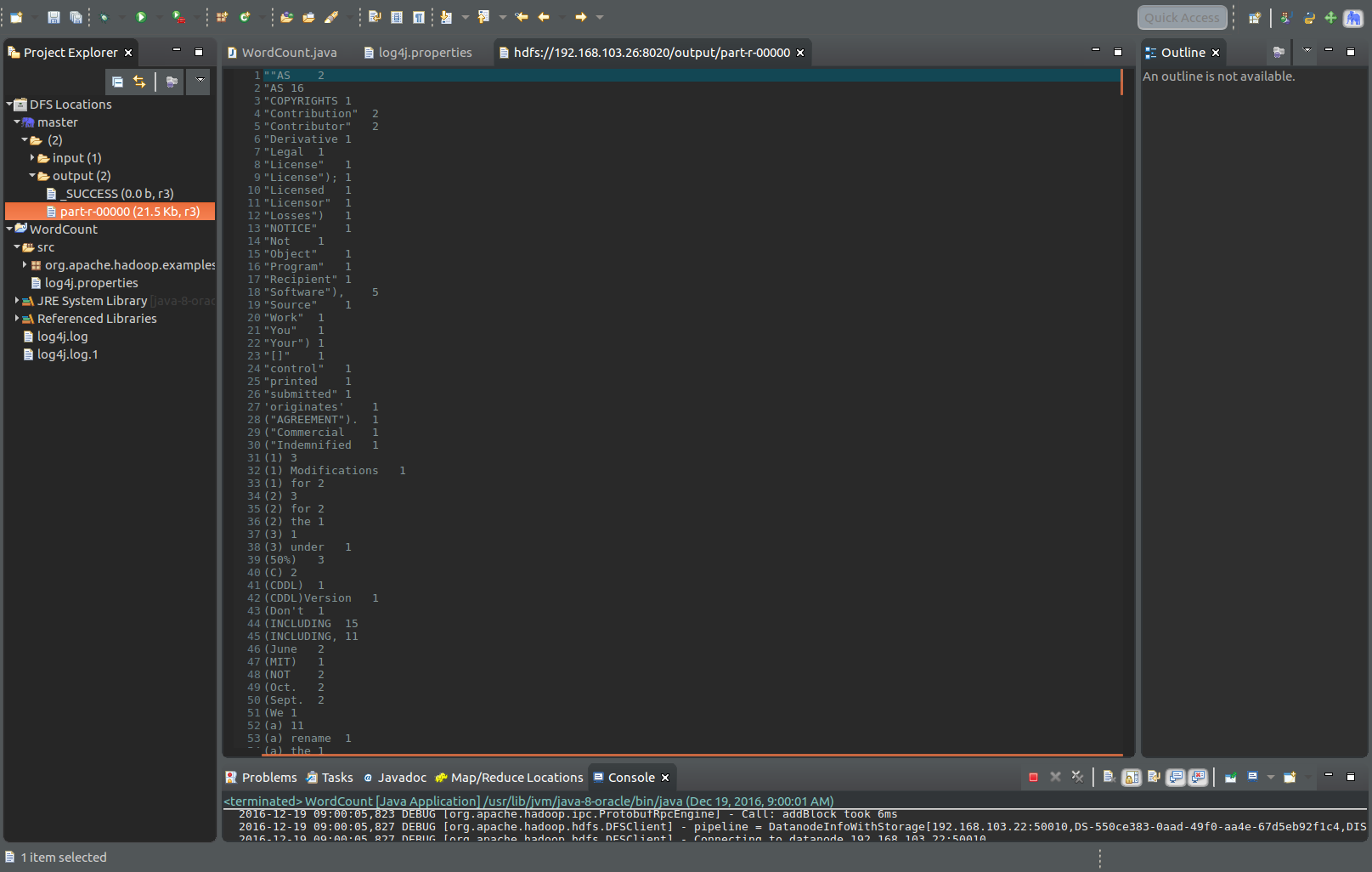
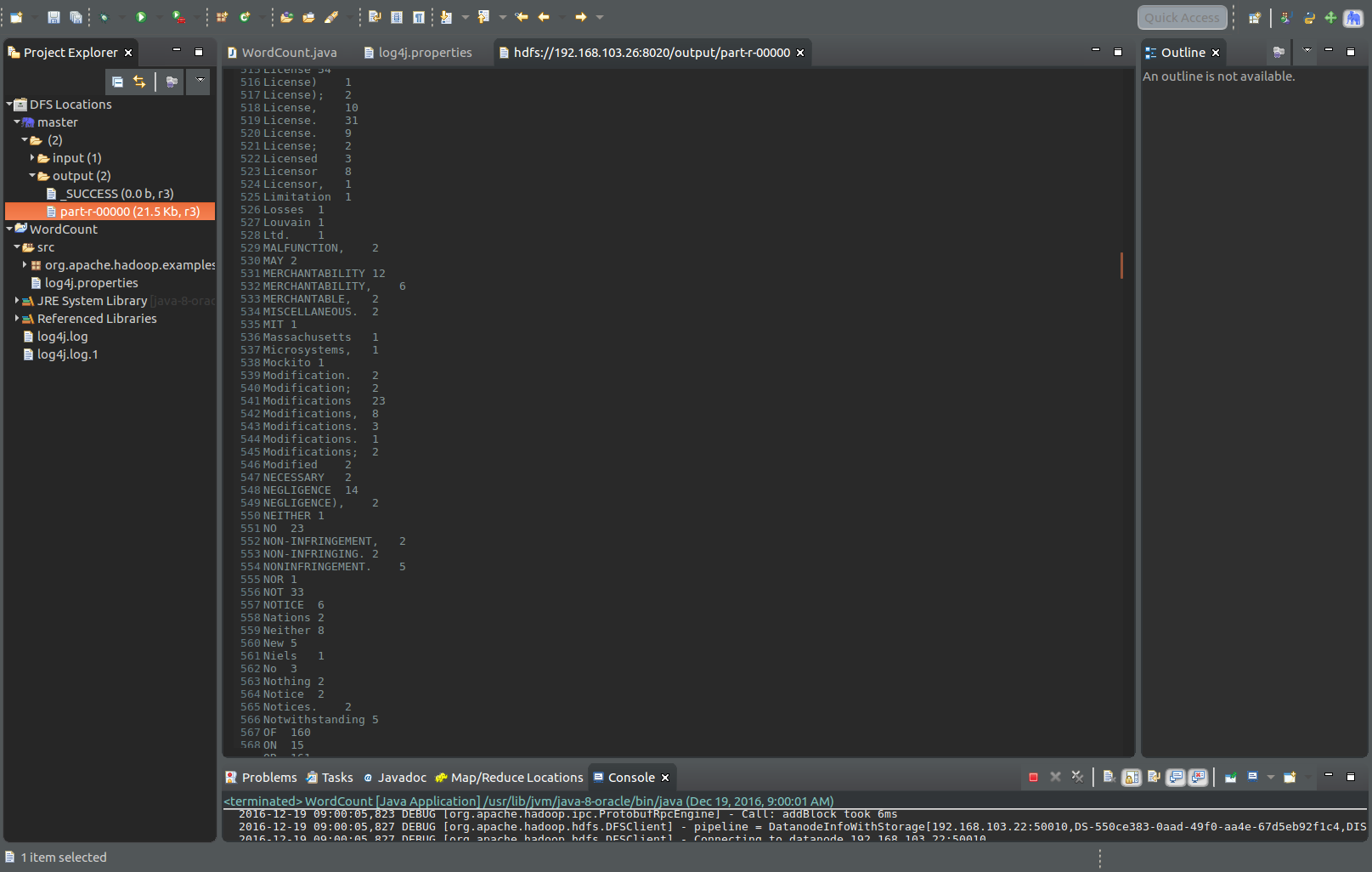
至此,从安装到mapreduce Wordcount测试全部结束了。
hadoop2.7.6全模式下,结合eclipse hadoop插件配置,完成Wordcount测试。
实验结果分析:
1、Wordcount项目代码是结合Map-reduce的核心思想,以及对于Java输入输出流的认识所编写,也参考了一下"大牛"博客编写的,能够基本实现分词-词频统计。
2、小项目的分词的效果显然没有Python Jieba分词来的精确,但是基于Hadoop Mapreduce的运算,分词一篇词汇众多的文档只需要5秒。(如需查看请点开。文档来源:Hadoop LICENSE.txt)
 测试文档
测试文档
心得体会:
1、实验完成结果到达预期目标,在搭建平台的过程耗费了很多学习成本,主要花在安装包的下载以及对于Linux系统的理解和hadoop配置文件的理解。
2、实验完成的过程中与小组成员分工合作,在搭建过程中自学了linux的命令操作以及linux系统的一些工作原理。
3、在搭建hadoop平台时,遇到很多匪夷所思的问题,通过hadoop平台自带的log文件,查看日志文件,百度搜索或者看国外网站的配置方式,再通过自己的尝试,解决问题。
4、在搭建过程体会最深的就是hadoop对于端口的使用很谨慎,第一次在尝试的时候没有仔细看清楚官网文档的端口设置,配置出错,导致进度耽误几天,最后才发现是端口的问题。
5、在搭建完后对于linux系统也有深刻的体会,对于linux的权限设置,SSH,以及基本的文件操作命令等有基本的掌握经验。
6、小组成员在第一次冲刺后决定更改软件工程项目,主要是为了适应目前的学习任务以及工作任务。小组成员目前在分析 学校历年学生体质测试数据 以及 网络招聘岗位数据对应学校各二级学院的专业核心技能
Python Django项目属于python后端项目,初期小组成员定题是为了学习除java后端以外的另外一直后端开发。但是后期因为繁重的分析任务以及报告,所以决定开始寻找新的出路,也顺利在第三次冲刺前几天完成实验。
虽然可能与软件工程的项目关系不太大,但是在搭建平台的过程,小组成员也深刻体会到团队合作的意义。以及对于大数据平台的理解,不再是觉得深不可测,改变对于大数据平台以及云计算的看法。
展望:
1、希望在接下来的寒假或者未来的时间点,完善自己的hadoop平台,通过hadoop平台提交小组的数据分析项目,利用Mapreduce并行化算法以及YARN集群分布式计算,提高数据分析的效率。
2、以及写一个基于hadoop平台的分布式爬虫,提高大数据的读取时间。
3、目前也在学习Spark,掌握与Mapreduce相类似的并行化运算框架,也希望在日后的使用中,结合HBase,Mapreduce/Spark搭建一个云计算平台项目。
4、在未来的时间,花更多时间从理解hadoop的核心架构,到理解hadoop的外沿,学习Spark,HBase,Pig,Mahout,Hive等核心工具的使用。
5、最近时间关注大数据方向注意到关联数据RDF的应用,也希望能尝试利用Sqoop读取关联数据,进行数据分析。
