

分布式系统在可管理性上造成的问题
分布式系统并不是简单的把一堆服务器一起运行起来就能满足需求的。对比单机或少量服务器的集群,有一些特别需要解决的问题等待着我们。
硬件故障率
所谓分布式系统,肯定就不是只有一台服务器。假设一台服务器的可靠运行时间是1%,那么当你有100台服务器的时候,那就几乎总有一台是在故障的。虽然这个比方不一定很准确,但是,当你的系统所涉及的硬件越来越多,硬件的故障也会从偶然事件变成一个必然事件。一般我们在写功能代码的时候,是不会考虑到硬件故障的时候应该怎么办的。而如果在编写分布式系统的时候,就一定需要面对这个问题了。否则,很可能只有一台服务器出故障,整个数百台服务器的集群都工作不正常了。

除了服务器自己的内存、硬盘等故障,服务器之间的网络线路故障更加常见。而且这种故障还有可能是偶发的,或者是会自动恢复的。面对这种问题,如果只是简单的把“出现故障”的机器剔除出去,那还是不够的。因为网络可能过一会儿就又恢复了,而你的集群可能因为这一下的临时故障,丢失了过半的处理能力。
如何让分布式系统,在各种可能随时出现故障的情况下,尽量的自动维护和维持对外服务,成为了编写程序就要考虑的问题。由于要考虑到这种故障的情况,所以我们在设计架构的时候,也要有意识的预设一些冗余、自我维护的功能。这些都不是产品上的业务需求,完全就是技术上的功能需求。能否在这方面提出对的需求,然后正确的实现,是服务器端程序员最重要的职责之一。
资源利用率优化
在分布式系统的集群,包含了很多个服务器,当这样一个集群的硬件承载能力到达极限的时候,最自然的想法就是增加更多的硬件。然而,一个软件系统不是那么容易就可以通过“增加”硬件来提高承载性能的。因为软件在多个服务器上的工作,是需要有复杂细致的协调工作。在对一个集群扩容的时候,我们往往会要停掉整个集群的服务,然后修改各种配置,最后才能重新启动一个加入了新的服务器的集群。

由于在每个服务器的内存里,都可能会有一些用户使用的数据,所以如果冒然在运行的时候,就试图修改集群中提供服务的配置,很可能会造成内存数据的丢失和错误。因此,运行时扩容在对无状态的服务上,是比较容易的,比如增加一些Web服务器。但如果是在有状态的服务上,比如网络游戏,几乎是不可能进行简单的运行时扩容的。
分布式集群除了扩容,还有缩容的需求。当用户人数下降,服务器硬件资源出现空闲的时候,我们往往需要这些空闲的资源能利用起来,放到另外一些新的服务集群里去。缩容和集群中有故障需要容灾有一定类似之处,区别是缩容的时间点和目标是可预期的。
由于分布式集群中的扩容、缩容,以及希望尽量能在线操作,这导致了非常复杂的技术问题需要处理,比如集群中互相关联的配置如何正确高效的修改、如何对有状态的进程进行操作、如何在扩容缩容的过程中保证集群中节点之间通信的正常。作为服务器端程序员,会需要花费大量的经历,来对多个进程的集群状态变化,造成的一系列问题进行专门的开发。
软件服务内容更新
现在都流行用敏捷开发模式中的“迭代”,来表示一个服务不断的更新程序,满足新的需求,修正BUG。如果我们仅仅管理一台服务器,那么更新这一台服务器上的程序,是非常简单的:只要把软件包拷贝过去,然后修改下配置就好。但是如果你要对成百上千的服务器去做同样的操作,就不可能每台服务器登录上去处理。

服务器端的程序批量安装部署工具,是每个分布式系统开发者都需要的。然而,我们的安装工作除了拷贝二进制文件和配置文件外,还会有很多其他的操作。比如打开防火墙、建立共享内存文件、修改数据库表结构、改写一些数据文件等等……甚至有一些还要在服务器上安装新的软件。
如果我们在开发服务器端程序的时候,就考虑到软件更新、版本升级的问题,那么我们对于配置文件、命令行参数、系统变量的使用,就会预先做一定的规划,这能让安装部署的工具运行更快,可靠性更高。
除了安装部署的过程,还有一个重要的问题,就是不同版本间数据的问题。我们在升级版本的时候,旧版本程序生成的一些持久化数据,一般都是旧的数据格式的;而我们升级版本中如果涉及修改了数据格式,比如数据表结果,那么这些旧格式的数据,都要转换改写成新版本的数据格式才行。这导致了我们在设计数据结构的时候,就要考虑清楚这些表格的结构,是用最简单直接的表达方式,来让将来的修改更简单;还是一早就预计到修改的范围,专门预设一些字段,或者使用其他形式存放数据。
除了持久化数据以外,如果存在客户端程序(如受击APP),这些客户端程序的升级往往不能和服务器同步,如果升级的内容包含了通信协议的修改,这就造成了我们必须为不同的版本部署不同的服务器端系统的问题。为了避免同时维护多套服务器,我们在软件开发的时候,往往倾向于所谓“版本兼容”的协议定义方式。而怎样设计的协议才能有很好的兼容性,又是服务器端程序需要仔细考虑的问题。
数据统计和决策
一般来说,分布式系统的日志数据,都是被集中到一起,然后统一进行统计的。然而,当集群的规模到一定程度的时候,这些日志的数据量会变得非常恐怖。很多时候,统计一天的日志量,要消耗计算机运行一天以上的时间。所以,日志统计这项工作,也变成一门非常专业的活动。
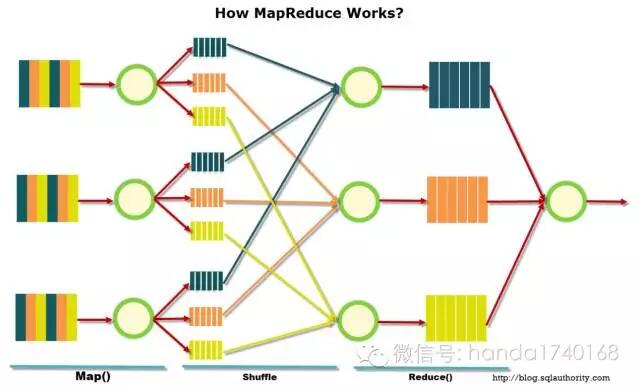
经典的分布式统计模型,有Google的Map Reduce模型。这种模型既有灵活性,也能利用大量服务器进行统计工作。但是缺点是易用性往往不够好,因为这些数据的统计和我们常见的SQL数据表统计有非常大的差异,所以我们最后还是常常把数据丢到MySQL里面去做更细层面的统计。
由于分布式系统日志数量的庞大,以及日志复杂程度的提高。我们变得必须要掌握类似Map Reduce技术,才能真正的对分布式系统进行数据统计。而且我们还需要想办法提高统计工作的工作效率。
本文来自 韩大 微信公众号
