

上一篇,主要是在说给一个分类‘打分’。这篇来讲一个分类的方法。
《机器学习实战》书中叫做‘决策树’。我理解的意思就是,满足条件A的就是A类,剩下的对象们再比较条件B,满足条件B的就是B,如果还有剩下的,就再比较条件C,条件D……以此类推。
举个例子:有5种海洋生物,判断是否是鱼类。这里有2个条件“不浮出水面是否可以生存”和“是否有脚蹼”。
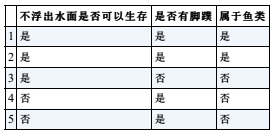
用到的“决策树”如下:
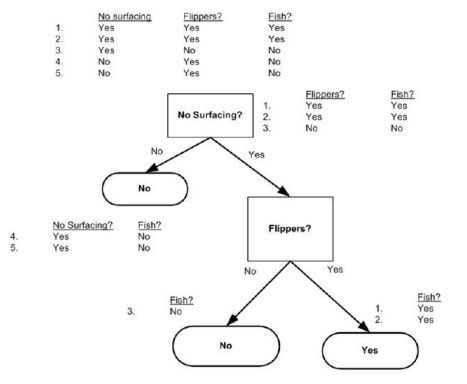
我们这里只讨论第一步“满足条件A的就是A类”。
把上面的数据转化为能被程序理解的结构:
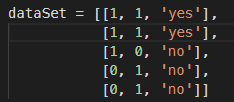
#给数据分类
def splitDataSet(dataSet , axis ,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #取每行的第0个到第axis-1个的数据
reducedFeatVec.extend(featVec[axis+1:]) #取每行的第axis+1个到最后一个的数据
# 上面两行,正好去掉了featVec[axis]这个数据
retDataSet.append(reducedFeatVec)
return retDataSet这里说一下3个参数的意义,dataSet 是原始的数据;axis 的意思使用哪个条件,是“不浮出水面是否可以生存”还是“是否有脚蹼”,也就是数据中的第0列还是第1列;value是比较的值。
调用一下:splitDataSet(dataSet , 0,1),意思是取出所有dataSet 中第0列值等于1的数据。即取出“不浮出水面可以生存”的生物。很明显结果是:[[1, 'yes'], [1, 'yes'], [0, 'no']],然后这里就用到了上一篇讲的香农熵,计算出香农熵(0.9182958340544896),然后作为此种分类与其他分类孰优孰劣的比较依据。
我们再试一下另一种分类条件
splitDataSet(dataSet , 0,0),即取出“不浮出水面不可以生存”的生物。结果是[[1, 'no'], [1, 'no']],计算出香农熵(0.0)。
很明显第二种的香农熵比第一种小,所以划分的结果更理想。
我们这里只使用了第一个条件,但是为了找到最优的划分分类的方法,我们最好还是做一个遍历。遍历每一条件,和该条件的每个生物的值做比较。看看使用哪个条件做划分比较好。
# 分割数据集
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet) # 整个数据集的原始香农熵
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
# 拿出第i列的数据
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
# 拿该列中的每一个值去做分割
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
# 计算香农熵的和
newEntropy += prob* calcShannonEnt(subDataSet)
# 如果香农熵减少的多,说明越好,就要保存下来这个值(保存下来第i列)
infoGain = baseEntropy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature代码运行结果是:0,也就是使用第0列划分的最优的。即第0列的值是1的是一类(两个属于鱼类,一个属于非鱼类),第0列的值是0的是另一类(完全属于非鱼类)。
我们再目测一下如果使用第1列进行分类,第一组有2个是鱼类,2个是非鱼类,另一组只有一个,是非鱼类。
明显,使用第0列进行分类比较好。虽然这仍然不是最优的结果,因为还是有一些非鱼类‘混进’了鱼类。但是注意,我们这里只进行了‘决策树’的第一步‘满足条件A的就是A类’。下一步就需要‘递归构建决策树’了。
