

最近做了太多的系统的论文,今天我们来看一看一个2016的ML相关的论文:Deep Neural Networks for YouTube Recommendations static.googleusercontent.com/media/resea… 。YouTube在2016年公布的基于deep learning来做的推荐算法,非常地新颖,也给大家指明了一个方向怎么样做这种类型的推荐算法。
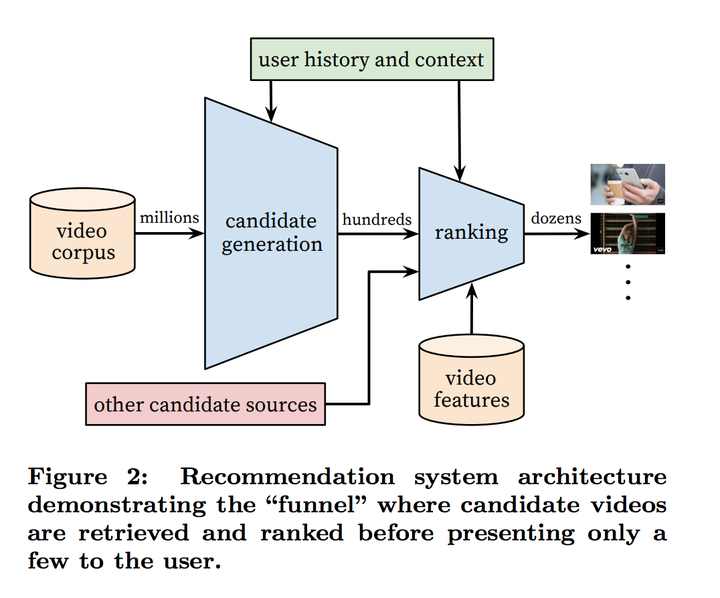
YouTube的整个推荐系统可以被理解为是一个多级排序算法(multistage ranking)。第一级排序算法在这里叫candidate generation,是一个神经网络,主要是比较粗糙地根据用户的喜好先把用户需要的视频分类一下,然后第二级的排序算法会把推荐视频的个数砍到10个左右。排序算法分两级主要是为了节省每次用户访问的时候,节省排序算法所需要用的资源。
要细讲YouTube这两级的排序算法的架构,我们要先来先介绍一下YouTube是如何把推荐算法改成classification的。推荐算法可以被理解为一个极端的multiclass classification;我们要做的是,在某一个时间(t),从所有的视频里面(V),对于某一个视频(i),这个用户(U)在这个context下(C)会不会去选择看这个视频(Wt = i)
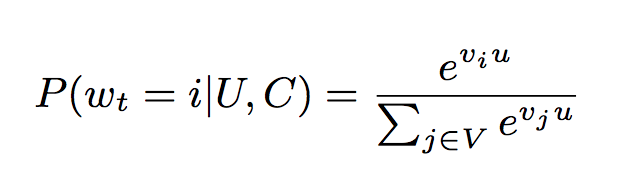
在这里,u是一个用户的embedding,Vi 和Vj 都是视频的embedding。这里所有提到的embedding都是从sparse的特征压缩到一个dense的向量。在上面的定义下,这个算法它需要学习的是user embedding(注意,这里没有提到要学习video embedding,后面会提到video embedding是怎么做的)。这里label都是根据视频观看而不是用户给视频做的点赞啊、反对啊这些用户特地去做的行为,因为视频观看的数据量大,而且很多没有很多人观看的视频点赞和反对的数据太少了。
为了优化训练的速度,因为每一个class会有很多negative,这里选择了去sample negative然后根据importance weighting 去矫正。为了优化用户访问时候的速度,找视频的时候用的是nearest neighbour。
===========================
下面我们来看一下具体在第一级,candidate generation的时候,这个模型的架构
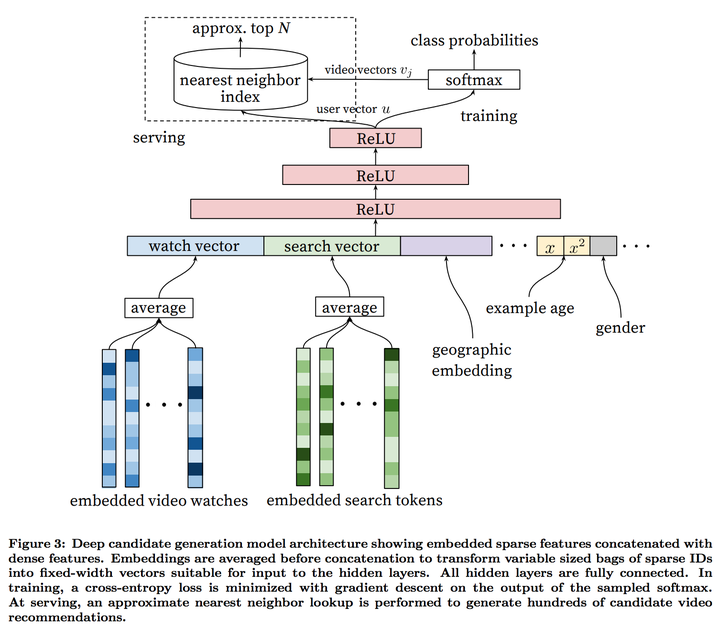
这里每一个用户搜索过的词条跟看过的视频都会变成embeeding,然后取一个均值,来代表这个用户看视频跟搜索的喜好。这里还要注意到的是几个点:
- 所有dense feature跟embedding都是直接被串联的(concatenate)
- embedding是跟着model parameter一起learn的,所以绝对不是generalized embedding
- 之后是几层fully connected ReLU
- 所有的feature都normalize到了[0, 1]的区间内。
整体的deep learning + embedding模型可以理解为generalized matrix factorization,但是这个比matrix factorization 好的一点就是各种各样的dense feature可以直接被加到模型里面。因为embedding是joint trained,新加入的feature会改变这个embedding。论文里提到一个很好的例子就是Example Age;ML系统一般都会bias到老的视频上面,因为它们的特征更多。但是有很多的视频是有时效性的,今天爆火的视频明天就不火了。为了修正推荐系统的时效性,example age被作为一个特征加了进去,这样模型就可以掌握所对应的时效性的分布。

在数据源上面,YouTube也做了不少思考。推荐算法的label是从所有视频播放来的,而不只是被推荐的视频播放来的,以确保如果用户有其他途径导致某一个视频火了,推荐算法能够很快地获得这个信息。还有,推荐算法是不知道这个视频是从哪里搜索来到,否则的话主页推荐会跟用户刚刚结束的搜索关系过度紧密。最后,YouTube每次计算的概率是未来会观看的概率,而不是hold-out的视频被观看的概率。这个问题在视频推荐里面差别非常大,因为视频推荐数据里面本来就有很多的视频观看是有非常高的co-watch概率,比如电视剧和MV。(其实最后一点我不大理解为什么花费这么多地篇幅去解释。。。。)
具体在模型架构的尝试上面,在这个论文里面的模型是3层深度,但是论文是试过0-4层深度,以及不同的特征对精度的贡献
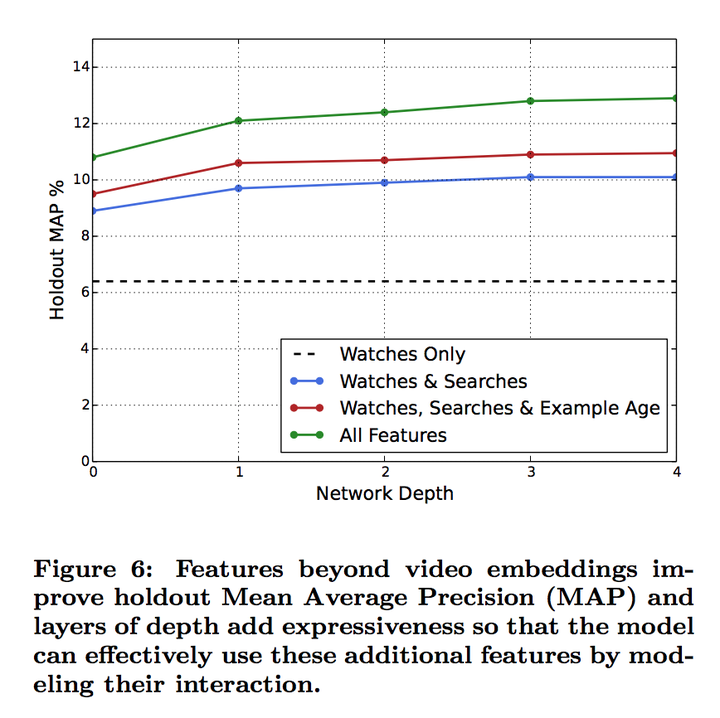
这个图里面可以看出来在加了特征以后模型的精度是有提升的,说明模型考虑了这些dense feature跟embedding的互动。
===========================
接下来我们来看第二级,ranking的模型架构
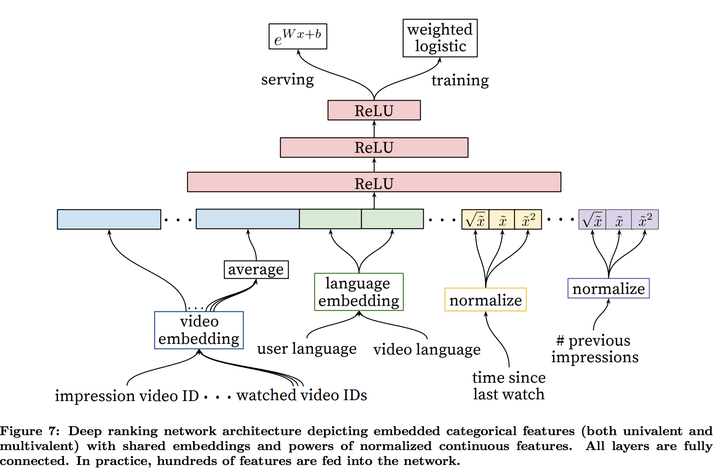
对于第二级的模型跟第一级的模型来说,本质上没有区别,但是因为第二级需要考虑的视频少了很多,所以可以考虑的特征多了很多。这里sparse特征还要分两个:
- univalent,只能有一个值的sparse 特征。比如这个视频的video ID
- multivalent,能有有很多值得sparse 特征,比如这个用户之前看的视频ID
对于这个模型的feature engineering最大的挑战是如何表述用户的历史行为,跟如何把这些历史行为跟现在这个视频联系起来。从实验结果来看,最重要地特征是用户跟这个视频还有跟其它视频的互动。文章还特地提到这类特征跟ads里面重要地特征很像。还有一些特征需要表达churn,以确保用户在一个视频被推荐而没有点击之后,算法不会推荐同样的视频。因为用的是NN,还有一个特殊地地方就是输入必须要normalize到[0,1]之间。normalization是用quantile去做的。
这里对于视频embedding还有的细节是:
- embedding的dimensionality是log(ID的个数)
- 特别大的ID space (比如video ID跟search ID)会根据频率来truncate,低频率的ID会直接对应到0
- multivalent的IDs会先去一个均值
- 每一个video ID对应的embedding在一个network里面都是一样的,就算它们想要表达的意义不同。假设这个模型的输入有‘用户之前看过的视频’跟‘给这个用户之前推荐过的视频’有同样的视频,那么这个视频对应的embedding是一样的。后面的ReLU会通过学习来用不同的方式去使用这些embedding
因为YouTube需要优化的是视频观看时间,而现在这个模型的输出是点击与否,跟观看时间有落差。文章里面用了weighted logistic regression
- 每一个有点击的视频(positive example)的weight是观看时间
- 每一个没有点击的视频(negative example)的weight是1(unit weight)
- 模型在数据有这样的weighting情况下学到每一个视频点击的概率是 (SUM(Ti) for all i in N) / N - k,N是training sample的总量,k是点击视频的量,Ti 是第i个视频的观看时间
- 如果观看的视频远少于没有观看的视频,那么模型学到的概率是E[T](1+P),P是点击概率,E[T]是观看时间的预期
- 点击率P是非常小的(绝大部分视频没有被观看),那么模型预测的值大概是E[T],就是对观看时间的预期
- serving的时候用exp(Wx+b)把概率装换成观测时间的预测
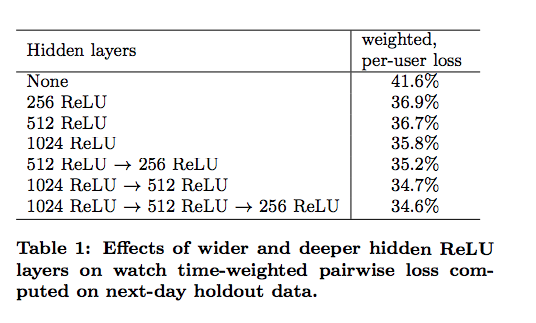
对于hidden layer的尝试,第二级模型跟第一级模型的结论类似,层数多了之后是diminishing return
总的来说,这个paper我觉得讲的非常的清楚,再次推荐大家去看一下原文 static.googleusercontent.com/media/resea…
