

在进行Hashtable源码解析之前,我先扔出Hashtable与HashMap有哪些区别?
1.关于null,HashMap允许key和value都可以为null,而Hashtable则不接受key为null或value为null的键值对。
2.关于线程安全,HashMap是线程不安全的,Hashtable是线程安全的,因为Hashtable的许多操作函数都用synchronized修饰。
3.Hashtable与HashMap实现的接口一致,但Hashtable继承Dictionary,而HashMap继承自AbstractMap,即父类不同。
4.默认初始容量不同,扩容大小不同。HashMap的hash数组的默认大小是16,而且一定是2 的指数,增加方式old2;Hashtable中hash数组默认大小是11,增加的方式是old2+1。
之前简要分析过HashMap的代码,关于HashMap可点击:Java集合之HashMap源码解析 .下面我们开始进行Hashtable的分析,先看代码清单1:
public class HashtableTest {
public static void main(String [] args){
Hashtable<String, String> table=new Hashtable<>();
Hashtable<String, String> table1=new Hashtable<>(16);
Hashtable<String, String> table2=new Hashtable<>(16, 0.75f);
HashMap<String,String> map=new HashMap<>();
Hashtable<String,String> table3=new Hashtable<>(map);
table.put("T1", "1");
table.put("T2", "2");
table.put(null, "3");
System.out.println();
System.out.println(table.toString());
}
}我们看到在创建对象上,和HashMap的使用方式相似,我们继续看其内部的构造函数是怎么样的,如代码清单2:
private transient Entry<?,?>[] table;//数组
private transient int count;//键值对的数量
private int threshold;//阀值
private float loadFactor;//加载因子
private transient int modCount = 0;//修改次数
public Hashtable(int initialCapacity, float loadFactor) {//下面的三个构造函数都是调用这个函数,来进行相关的初始化
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];//这里是与HashMap的区别之一,HashMap中table
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);
}
public Hashtable(int initialCapacity) {//指定初始数组长度
this(initialCapacity, 0.75f);
}
public Hashtable() {//从这里可以看出容量的默认值为16,加载因子为0.75f.
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}Hashtable的构造函数主要对table数组进行了初始化,这里没有什么要拿出来详细讲的,我们还是看下put的流程,代码清单3:
public synchronized V put(K key, V value) {//这里方法修饰符为synchronized,所以是线程安全的。
if (value == null) {
throw new NullPointerException();//value如果为Null,抛出异常
}
Entry tab[] = table;
int hash = hash(key);//hash里面的代码是hashSeed^key.hashcode(),null.hashCode()会抛出异常,所以这就解释了Hashtable的key和value不能为null的原因。
int index = (hash & 0x7FFFFFFF) % tab.length;//获取数组元素下标,先对hash值取正,然后取余。
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;//修改次数。
if (count >= threshold) {//键值对的总数大于其阀值
rehash();//在rehash里进行扩容处理
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}
private int hash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();//在1.8的版本中,hash就直接为k.hashCode了。
}
protected void rehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
int newCapacity = (oldCapacity << 1) + 1;//扩容,如果默认值是11,则扩容之后,数组的长度为23
if (newCapacity - MAX_ARRAY_SIZE > 0) {//这里的最大值和HashMap里的最大值不同,这里Max_ARRAY_SIZE的是因为有些虚拟机实现会限制数组的最大长度。
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<K,V>[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {//迁移键值对
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
} 通过代码清单2和3,我们可以看到Hashtable的数据结构和HashMap一样是一个Entry的数组,数组元素是一个单链表,这里展示出了一个很明显的区别,即hash值没有扰动处理。那怎么解决冲突呢?Hashtable的索引求值公式其实是:
((hashSeed^k.hashCode())&0x7FFFFFFF)%newCapacity——> hash&0x7FFFFFFF%newCapacity。hash&0x7FFFFFF是为了保证正数,因为hashCode的值有可能为负值,这样说有可能会有同学说,取正数直接用Math.abs不就行了。。。但是你确定所有情况下,abs都能保证输出是正数吗?来来举个例子给你看看:
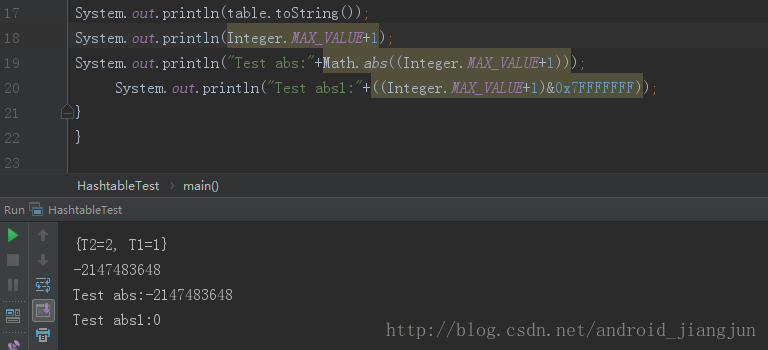
哈哈,你还能说什么。hash&0x7FFFFFFF是为了避免负值的出现,对newCapacity求余是为了使index在数组索引范围之内。看到这估计就有人问了那么HashMap中的hash&(tab.leng-1)怎么解释呢?如果不太明白,还请大家仔细看上篇文章,这里简单说一下,hash&(tab.length-1)其实是对(hash&0x7FFFFFFF)%newCapacity的代码级优化,简而言之就是位运算的性能是优于求余运算的。
细心的读者可能会发现HashMap与Hashtable的最大值是不一样的,上篇文章我们说过HashMap的长度是2的指数值,而HashMap的数组的最大长度是:1<<30=1073741824,这个值是int范围内2的指数值的最大值,不信可以打印1<<31=-2147483648。关于Hashtable的数组的最大值源码注释中有说明,是指虚拟机实现对array的长度有限制,如果大家纠结于这个最大值,why the max value is Integer.MAX_SIZE-8,请参考下面两个链接:
stackoverflow.com/questions/3…
stackoverflow.com/questions/3…
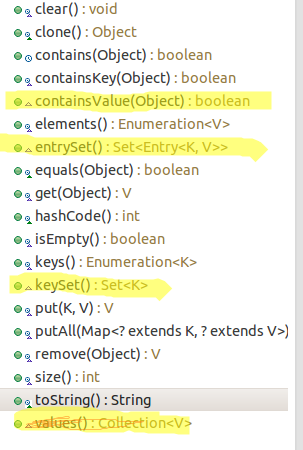
说完了Hash与最大值的梗,我们就要来看看线程安全,Hashtable中的主要方法都加了synchronized关键字来修饰(没有被颜色覆盖的),如下:
前面我们已经分析过存数据的过程,现在我们一起来看看取的过程。
public synchronized V get(Object key) {//没有什么特殊性,就是加了一个synchronized,就是根据index来遍历索引处的单链表。
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}鉴于Hashtable是历史遗留的类,现在很少有人使用它,即使我们在对线程安全有要求的场景中,也是通过使用ConcurrentHashMap来解决,而不是使用Hashtable 。这里可以简要的说一下原因:Hashtable使用synchronized来实现线程安全,效率不高,而ConcurrentHashMap采用锁分段技术来实现线程安全,大大提高了效率。在多线程环境中,当A线程访问Hashtable的put方法时,其他线程是不能访问诸如get,clear这些方法的,但是在ConcurrentHashMap中只要保证A线程与B线程不是持有一个段锁,是可以A线程访问put时其他线程同时访问get操作。
最后我们说一下Hashtable的初始容量为什么是11?Hashtable的扩容方式是:old*2+1,初始容量11,第一次扩容为23,第二次扩容为47,可以看到Hashtable的容量肯定是奇数,有一些更是为质数。到这里就涉及到了哈希算法相关的知识了,这里就不展开说哈希算法相关的内容了。Hashtable之所以初始容量为11(质数)和扩容方式保证为奇数,是为了散列得更均匀,也就是减少碰撞发生的几率。
转载请注明出处:blog.csdn.net/android_jia…
