

《机器学习实战》是一本很好的机器学习相关的入门书籍。
但是上面的很多代码的注释不是很详细,向我这样还不是很熟徐Python语法的新手来说理解起来有很多麻烦。
我的读到了K-近邻算法,我敲了敲书上的示例代码,并且加上了详细的注释。
import operator
from numpy import *
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classsify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# 以下三行,计算距离
# tile:将inX在行方向重复dataSetSize次,列方向重复1次,也就是生成与dataSet行列数相同的矩阵
diffFMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffFMat**2
# 矩阵 axis=1 每一行相加,axis=0,是每一列相加
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
# 将distances中的元素从小到大排列,提取其对应的index(索引),然后输出到sortedDistIndicies
sortedDistIndicies = distances.argsort()
classCount = {}
# 计算最小的k个点中,有几个A,有几个B,放到一个字典里面
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 将字典排序
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
print(classsify0([0, 0], group, labels, 3))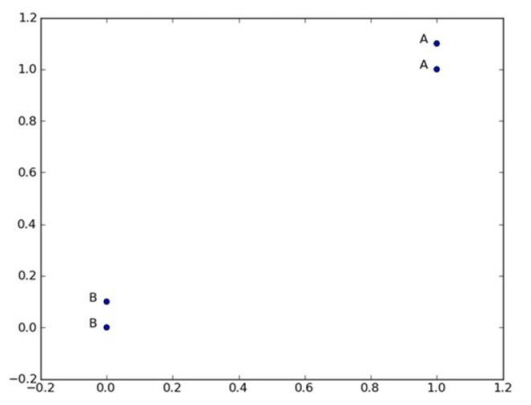
这里解决的问题是,已知在二维坐标系中有4个点,其中有两个A,两个B,已知它们的坐标,求坐标[0, 0]的点是属于A还是B。
答案是:B
K近邻算法解决这个问题的思路是,选择K个(代码中是3个)距离[0, 0]最近的点,看这K个点中到底是A的数量多,还是B的数量多。最终:([('B', 2), ('A', 1)]),B的数量多。
