

Photon是一下Google的广告系统的joiner。我们今天来看一下Photon是如何做到精确的join各种各样的时间的。原文在这里static.googleusercontent.com/media/resea…
我们先来解释一下joiner的概念是什么。假设我是一个吃瓜群众,我登录了淘宝,这个登录是第一个事件。然后我搜索了“薛之谦同款手提箱”,这是第二个事件。我点击了人气排序,这是第三个事件。之后我点击了“超大加厚行李拉杆箱blablabla”,这是第四个事件。然后我点击了立即购买,这是第五个事件。这个过程中,有些厂商会在“搜索薛之谦同款手提箱”那个关键词下面打广告,那么这个时候如果我点击了这个关键词下面的竞价词条,淘宝是要跟厂商收广告费的。在整个过程中,淘宝得知道
- 是谁在什么时候点击了这个广告
- 后面我掏钱是不是因为这个广告
- 这个用户是谁,他有什么特征
这些信息都会需要储存下来,让广告商可以看出来是什么样的人点了他们的广告,他们的广告效益如何,以及淘宝要根据这个用户的喜好,如何优化推荐给用户。在整个过程里面,每一个页面可以都是分开的,我只要确保我的访问至始至终有一个独一无二的标识,每个页面分开在服务器端log自己的数据和id,然后我靠一个joiner系统后面再把我有兴趣的时间跟特征结合起来就可以了
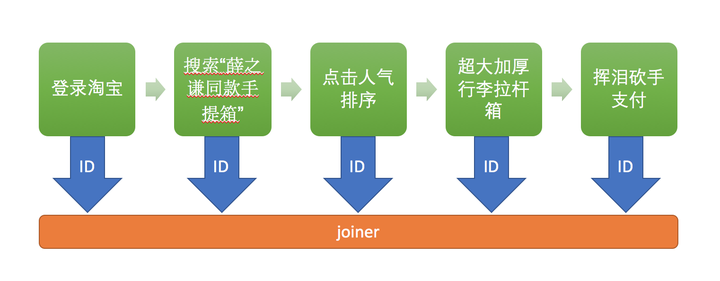
所以这类joiner在任何把推荐作为看家本领的公司里面都是非常重要的。它的availability必须要高,收钱可不能卡壳;它速度可以稍微慢一点但是不能太慢,最好几个小时之内100%需要join的事件可以都join了;它的吞吐必须要大,因为经常特征是需要跟事件一起log下来的;它得能够处理无序的信息流,因为处理我的请求的可能是好几个不同的服务器,每次这些事件被joiner读出来的顺序可能不是用户访问的顺序。
Photon的核心是一个基于Paxos的ID registry。基于paxos一个原因就是这个系统得有高的availability,而且被join的时间可能会被好几个不同的数据中心的机器处理。这个数据库里面存的最终要的东西就是,在过去N天里面,有哪些事件的ID是被join了的。这个N可大可小,具体看业务需求(offline conversion的话N就要大,只是点击的话N就可以很小)。
每次一个joiner要输出一个joined 事件之前,joiner要确认这个事件是不是已经被join过了。如果已经被join过了,那么直接跳过这个事件。如果没有的话,尝试告诉这个paxos的数据库,这个事件要被join了,最后输出join的结果。
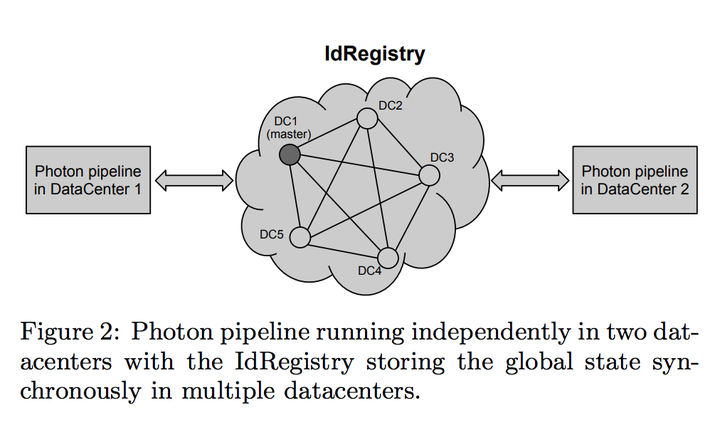
这里我们可以看到这个IdRegistry肯定是整个系统的核心,问题是Google得确保不同的数据中心都可以处理这些事件,数据中心事件可能有百毫秒级别的延迟,这个大的延迟下面如何scale一个基于paxos的数据库呢?
- 在服务器端的写入被分批次处理,这样可以确保每次沟通的时候效率更高
- 根据事件ID分不同的shard,这样可以靠增加机器的数量来加大吞吐量
- 为了可以动态加shard,这个数据库的sharding机制是根据时间戳来的;时间点t1可能只有10个shard,t1+100可能是20个shard。服务器端根据访问事件来分这个事件具体该在哪个shard里面
- 因为这个是基于时间戳的,那么这里也是用到的Google的TrueTime系统。这个系统在之前spanner那边有仔细讲过,这里我就先跳过
- 为了确保每个时间的ID是不一样的,ID有三个部分:服务器IP,进程ID,跟时间戳。在每个服务器上面的每个线程的时间戳都是单调递增的(不知道为什么这里没考虑多线程,不过可也以用线程ID),所以可以确保每个事件ID都是独一无二的
- 定期这个系统会吧超过N天的所有event全部备份然后删掉
具体处理业务逻辑的时候是下面的流程
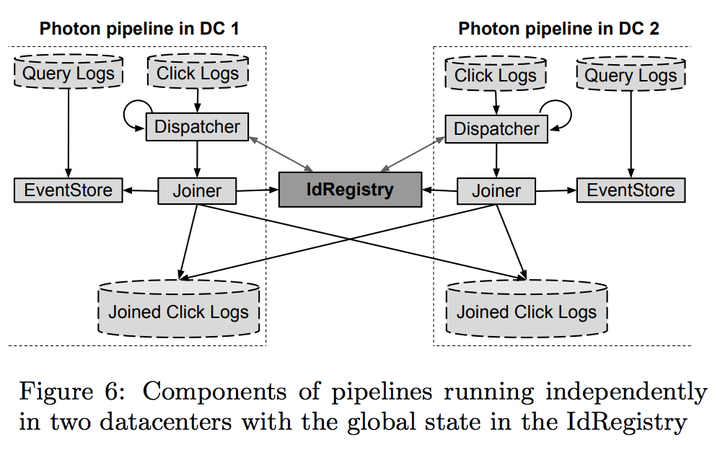
这里可以看到点击的log和访问的log是分开的,因为点击的log小所以joiner是跟的点击的log。joiner的输出是得在多个服务器备份的。这里还有两个部分没有提到,Dispatcher跟EventStore。它们是做什么用的呢?
- EventStore是基于query ID返回这个query信息的服务。EventStore分两部分:实时的部分(因为大部分时间都在短时间内发生),和非实时的部分。实时的部分用的是内存,非实时的部分基于BigTable
- 每次joiner处理业务逻辑的时候,它都会去EventStore去查找这个点击对应的访问。如果没有找到对应的访问,joiner在处理这一条事件的时候会返回失败。
- 如果成功了,joiner会告诉ID registry,然后输出join的结果
- 为了防止joiner跟registry确认的时候registry的RPC因为其他意外失败了,每次joiner尝试写入的时候都会带一个token,服务器端如果在一个ID下面收到了同一个token那么会返回成功,joiner如果受到rpc失败的话重试的时候会用同一个token
- Dispatcher是为了确保at least once。Google服务器端的log最后是存在GFS里面的,Dispatcher会定期去GFS找还没有处理过的文件,然后分批送给joiner,没有处理完的文件Dispatcher会储存进度。Dispatcher每次发送一个时间之前都会跟ID Registry确认这个时间还没有被join
- 如果joiner返回失败,那么Dispatcher会再log一次这个点击,然后晚一点再尝试join
有各种GFS和内存+BigTable加持,Photon的性能还是不错的
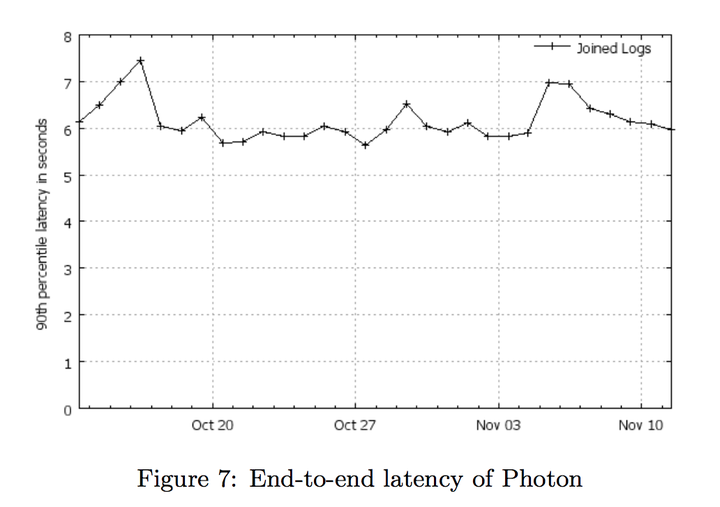
p90延迟是6~7秒左右
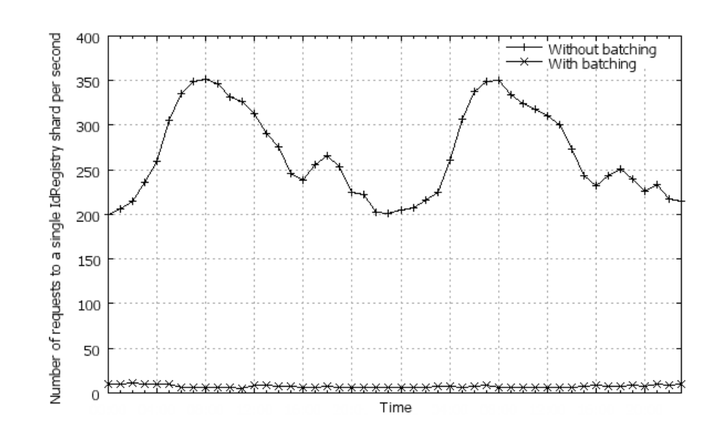
在服务器端分批次处理的加持下,ID Registry服务器的吞吐量大大增加。
说实话这个文章有点水,一下子就写完了,但我一开始看原文还挺长的。下周我还是看一个没有那么水的文章吧,大家有什么推荐可以留言。Photon的原文在这里static.googleusercontent.com/media/resea…
