

参考文章:JS正则表达式一条龙讲解,从原理和语法到JS正则、ES6正则扩展,最后再到正则实践思路
正则方法
RegExp上用来匹配提取的方法——exec()
RegExpObject.exec(String)
new RegExp('\\d+', 'g').exec('123abc1233')
new RegExp('\\d+').exec('123abc1233')
["123", index: 0, input: "123abc1233"]
exec()接收一个字符串参数,不管是否全局匹配,都只返回包含第一个匹配项的信息的数组;或者在没有匹配项的情况下返回null。
RegExp上用来测试匹配成功与否的方法——test()
RegExpObject.exec(String)
new RegExp('\\d+', 'g').test('123abc1233')
truetest()接收一个字符串参数,返回布尔值。
字符串方法(与正则相关)
match()
String.match(string / RegExpObject)
'123abc1233'.match(/\d+/)
["123", index: 0, input: "123abc1233"]
'123abc1233'.match(/\d+/g)
["123", "1233"]
返回值: 存放匹配结果的数组。该数组的内容依赖于 regexp 是否具有全局标志 g。
如果 regexp 没有标志 g,那么 match() 方法就只能在 stringObject 中执行一次匹配。(与exec()方法一样)
如果没有找到任何匹配的文本, match() 将返回 null。
如果 regexp 具有标志 g,则 match() 方法将执行全局检索。
replace()
String.replace(string / RegExpObject, replaceString)
'123abc123'.replace(/\d+/g, 'abc')
'abcabcabc'
返回一个新的字符串
search()
String.search(RegExpObject)
'123abc123'.search(/\d+/g)
0
返回第一个与 RegExpObject相匹配的子串的起始位置。
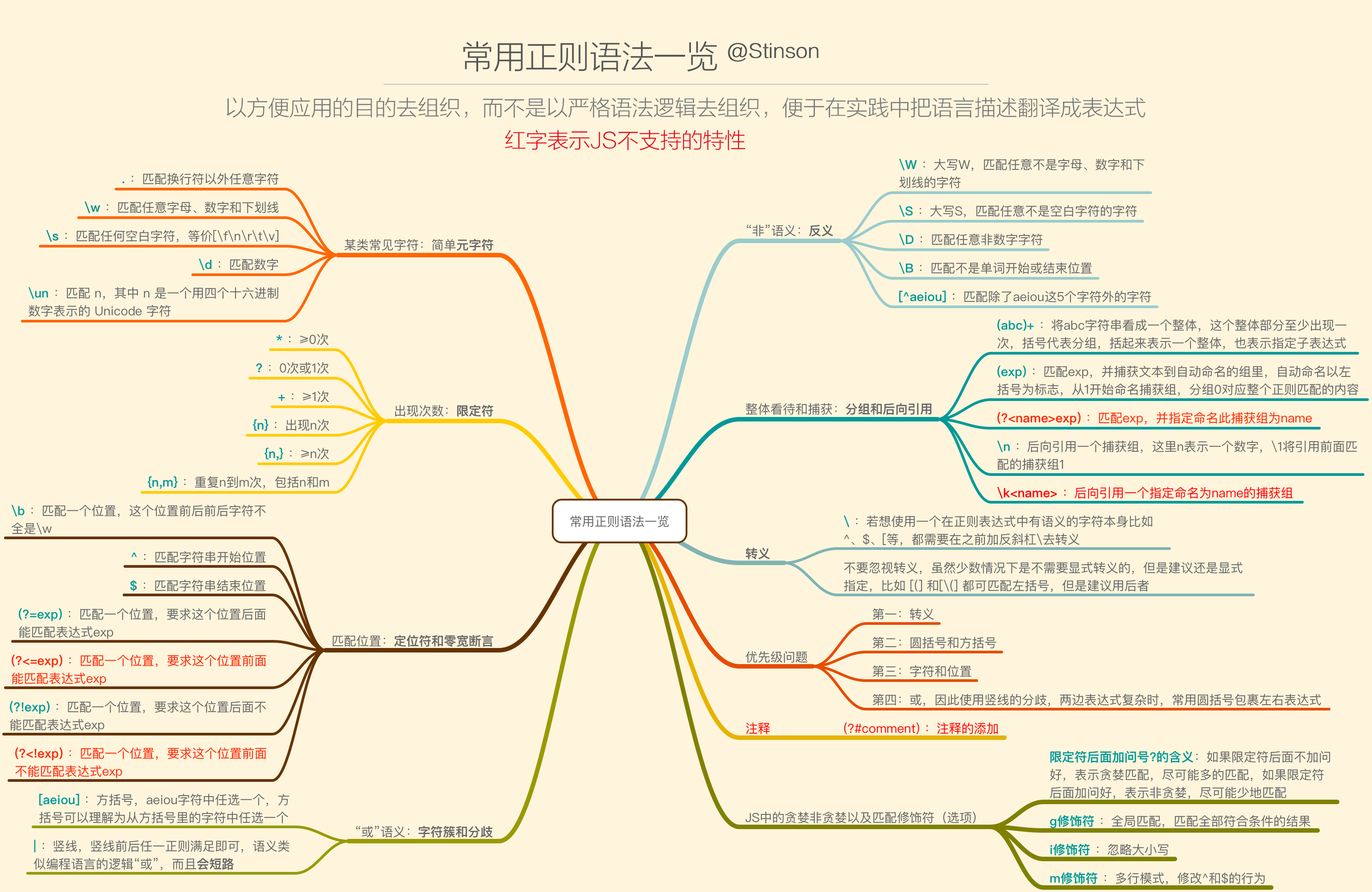
元字符
^ 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a"
$ 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A"
* 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa
+ 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa
? 匹配前面元字符0次或1次,/ba*/将匹配b,ba
(x) 匹配x保存x在名为$1...$9的变量中
x|y 匹配x或y
{n} 精确匹配n次
{n,} 匹配n次以上
{n,m} 匹配n-m次
[xyz] 字符集(character set),匹配这个集合中的任一一个字符(或元字符)
[^xyz] 不匹配这个集合中的任何一个字符
[\b] 匹配一个退格符
\b 匹配一个单词的边界
\B 匹配一个单词的非边界
\cX 这儿,X是一个控制符,/\cM/匹配Ctrl-M
\d 匹配一个字数字符,/\d/ = /[0-9]/
\D 匹配一个非字数字符,/\D/ = /[^0-9]/
\n 匹配一个换行符
\r 匹配一个回车符
\s 匹配一个空白字符,包括\n,\r,\f,\t,\v等
\S 匹配一个非空白字符,等于/[^\n\f\r\t\v]/
\t 匹配一个制表符
\v 匹配一个重直制表符
\w 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9]
\W 匹配一个不可以组成单词的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。
捕获分组与后向引用
'ab123ab|cd123cd|ab123cd|cd123ab'.match(/(ab|cd)123\1/g)
["ab123ab", "cd123cd"]
// 不匹配ab123cd 或者cd123ab js 捕获分组只支持 \ 分组编号 格式,不支持 $ 分组编号 格式,编号从1开始
优先级问题
优先级从高到低是:
- 转义 \
- 括号(圆括号和方括号)
(), (?:), (?=), []- 字符和位置
- 竖线
|
回溯
正则首次尝试匹配整个字符串,如果失败则回退一个字符后再次尝试,直到找到匹配的内容或没有字符尝试
贪婪模式与非贪婪模式
// 贪婪
'abbb'.match(/ab*/g)
["abbb"]
// 非贪婪
'abbb'.match(/ab*?/g)
["a"]
如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
量词:
- {m,n}:m到n个
- *:任意多个
- +:一个到多个
- ?:0或一个
零宽度断言(零宽度匹配)
作用:( js目前只支持正向前瞻断言和反向前瞻断言,即?= 和 ?!)
是给指定位置添加一个限定条件,用来规定此位置之前或之后的字符必须满足限定条件才能是正则匹配成功
// 正向前瞻断言
'abcdef'.match(/bc(?=de)/g)
["bc"]
'abcdef'.match(/bc(?=deg)/g)
null
// 后向前瞻断言
'abcdef'.match(/bc(?!de)/g)
null
'abcdef'.match(/bc(?!deg)/g)
["bc"]
