

PAI TensorFlow Q&A
目录
如果以上内容无法解决您的问题,请首先查看PAI知识库:help.aliyun.com/product/303…,若问题仍得不到解决请粘贴logview(Tensorflow日志中的蓝色长链接)到PAI工单系统进行提问,工单系统地址:workorder.console.aliyun.com/console.htm…
如何开通PAI的深度学习功能
目前机器学习平台深度学习相关功能处于公测阶段,深度学习组件包含TensorFlow、Caffe、MXNet三个框架,开通方式如下,进入机器学习控制台,在相应项目下勾选GPU资源即可使用。

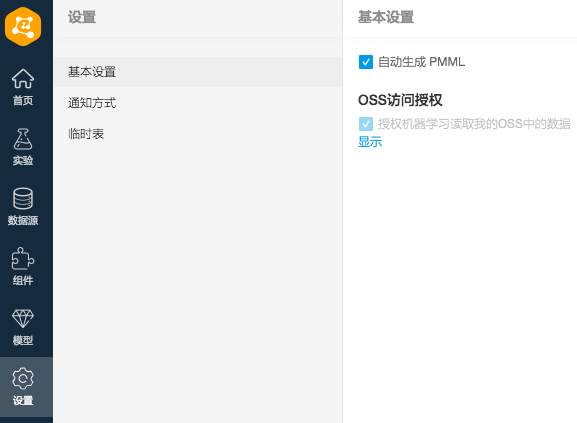
开通GPU资源的项目会被分配到公共的资源池,可以动态的调用底层的GPU计算资源。另外需要在设置中设置OSS的访问权限:
如何支持多python文件脚本引用
很多时候我们通过python 模块文件组织训练脚本。可能将模型定义在不同的Python文件里,将数据的预处理逻辑放在另外一个Python文件中,最后有一个Python文件将整个训练过程串联起来。例如:在test1.py中定义了一些函数,需要在test2.py文件使用test1.py中的函数,并且将test2.py作为程序入口函数,只需要将test1.py和test2.py打包成tar.gz文件上传即可。
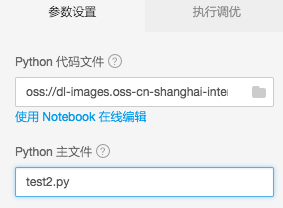
Python代码文件为定义的tar.gz包
Python主文件定义入口程序文件
如何上传数据到OSS
可以观看视频:help.aliyun.com/video_detai…
使用深度学习处理数据时,数据先存储到OSS的bucket中。第一步要创建OSS Bucket。 由于深度学习的GPU集群在华东2,建议您创建 OSS Bucket 时选择华东2地区。这样在数据传输时就可以使用阿里云经典网络,算法运行时不需要收取流量费用。Bucket 创建好之后,可以在OSS管理控制台 来创建文件夹,组织数据目录,上传数据了。
OSS支持多种方式上传数据, API或SDK详细见:help.aliyun.com/document_de…
OSS还提供了大量的常用工具用来帮助用户更加高效的使用OSS。工具列表请参见:help.aliyun.com/document_de…
建议您使用 ossutil 或 osscmd ,这是两个命令行工具,通过命令的方式来上传、下载文件,还支持断点续传。
注:在使用工具时需要配置 AccessKey 和ID,登录后,可以在Access Key 管理控制台创建或查看。
如何使用PAI读取OSS数据
Python不支持读取oss的数据, 故所有调用pythonOpen()os.path.exist()等文件, 文件夹操作的
函数的代码都无法执行.如**Scipy.misc.imread()**,**numpy.load()** 等
那如何在PAI读取数据呢, 通常我们采用两种办法.
方法一
如果只是简单的读取一张图片, 或者一个文本等, 可以使用**tf.gfile**下的函数, 具体成员函数如下

具体的文档可以参照这里(可能需要翻墙)
方法二
如果是一批一批的读取文件, 一般会采用**tf.WhoFileReader()** 和tf.train.batch()或
tf.train.shuffer_batch()
接下来会重点介绍常用的tf.gfile.Glob,tf.gfile.FastGFile,tf.WhoFileReader()和
tf.train.shuffer_batch()
读取文件一般有两步:
获取文件列表
读取文件
如果是批量读取, 还有第三步:创建batch
从代码上手:
在使用PAI的时候, 通常需要在右侧设置读取目录, 代码文件等参数, 这些参数都会通过--XXX的形式传入,**tf.flags**可以提供了这个功能

接下来就分两种情况了
小规模读取时建议:tf.gfile.FastGfile()

大批量读取时建议:tf.WhoFileReader()
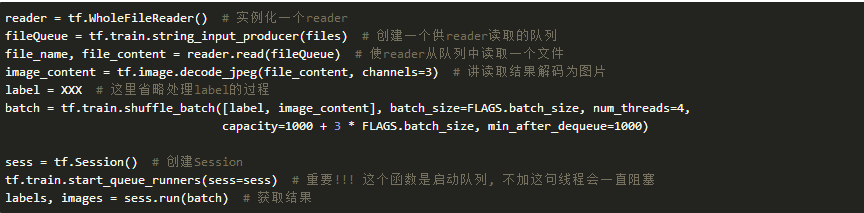
现在解释下其中重要的部分
1.tf.train.string_input_producer, 这个是把files转换成一个队列, 并且需要tf.train.start_queue_runners来启动队列
2.tf.train.shuffle_batch 参数解释
3.batch_size批大小, 每次运行这个batch, 返回多少个数据
4.num_threads运行线程数, 在PAI上4个就好
5.apacity随机取文件范围, 比如你的数据集有10000个数据, 你想从5000个数据中随机取, capacity就设置成5000.
6.min_after_dequeue维持队列的最小长度, 这里只要注意不要大于**capacity**即可
如何使用PAI写入数据到OSS
直接使用tf.gfile.FastGFile()写入

通过tf.gfile.Copy()拷贝

通过这两种方法, 文件都会出现在 '输出目录/model/example.txt' 下
PAI平台关于Tensorflow的案例有哪些
案例一:如何使用TensorFlow实现图像分类
视频地址:help.aliyun.com/video_detai…
文档介绍:yq.aliyun.com/articles/72…
代码下载:help.aliyun.com/document_de…
案例二:如何使用TensorFlow自动写歌
文档介绍:yq.aliyun.com/articles/13…
代码下载:help.aliyun.com/document_de…
如何查看Tensorflow的相关日志
具体请参考:yq.aliyun.com/articles/72…
