

译自:Explore Happiness Data Using Python Pivot Tables
作者:Michal Weizman
面对新的数据集的最大挑战之一就是知道从哪里开始,以及要关注的重点。 能够快速总结数百行和列可以节省大量的时间。 您可以使用一个简单的工具来实现这一点,就是一个数据透视表,可以帮助您以查询速度对数据进行切片,过滤和分组,并以视觉吸引人的方式表示信息。
数据透视表,它有什么好的?
您可能已经熟悉了Excel中的数据透视表的概念,它们在1994年被商标名称数据透视表引入。 该工具使用户能够自动对存储在一个表中的数据进行排序,计数,总计或平均。 在下图中,我们使用数据透视表功能快速总结了泰坦尼克号数据集。 下表中的较大表格显示了数据集的第一行〜30行,较小的表格是我们创建的数据透视表。
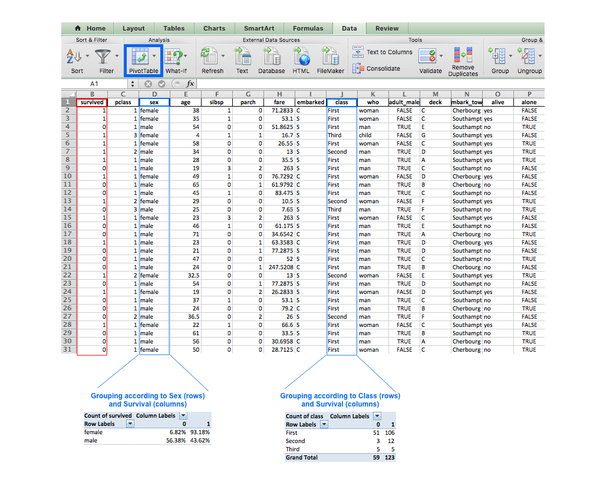
左侧的数据透视表根据“Sex ”和“Survived ”列分组数据。 因此,该表显示了不同生存状态(0:未生存,1:存活)中每个性别的百分比。 这让我们能够快速地看到,妇女的生存机会比男人更好。 右侧的表格也使用了Survived列,但这次数据按”Class“分组。
介绍我们的数据集:世界幸福报告
我们使用Excel作为上述例子,但这篇文章将展示内置Pandas函数的内置函数pivot_table的优点。 我们将使用“世界幸福报告”,这是关于全球幸福状态的调查报告。 该报告按照幸福程度排列了150多个国家,自2012年以来,每年都会发布几乎每年。我们将使用2015年,2016年和2017年收集的数据,如果您想要遵循,可以下载 。
我们正在运行python 3.6和pandas0.19。
我们可能会回答的一些有趣的问题是:
- 哪些是世界上最幸福,最不幸福的国家和地区?
- 幸福是否受到地区的影响?
- 幸福得分在过去三年中有显着变化吗?
我们来汇总我们的数据,快速浏览一下:
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('data.csv', index_col=0)
# 通过Year和Happiness Score排序
data.sort_values(['Year', "Happiness Score"], ascending=[True, False], inplace=True)
#展示前10个数据
data.head(10)
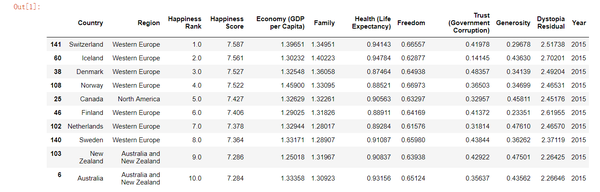
每个国家的”Happiness Score“是通过对表中的其他七个变量求和来计算的。 这些变量中的每一个都显示了从0到10的人口加权平均得分,随着时间的推移跟踪,并与其他国家进行了比较。
这些变量是:
- Economy:人均实际GDP
- Family:社会支持
- Health:健康的预期寿命
- Freedom:让生活选择的自由
- Trust:对腐败的看法
- Generosity:慷慨的感觉
- Dystopia:将每个国家与一个假设国家进行比较,这个国家代表每个关键变量的最低国家平均水平,并与残差有差异,用作回归基准
每个国家的Happiness Score决定了它的Happiness Rank - 这是其特定年份其他国家的相对位置。 例如,第一行表示,瑞士在2015年被评为最幸福的国家,幸福得分为7.587。 瑞士在冰岛前排名第一,得分为7.561。 丹麦在2015年排名第三,依此类推。 有趣的是,西欧在2015年排名前八的排名中排名第七。
我们将专注于最终的Happiness Score,以展示数据透视表的技术方面。
# 预览数据
print("Our data has {0} rows and {1} columns".format(data.shape[0], data.shape[1]))
# 检查缺失值
print("Are there missing values? {}".format(data.isnull().any().any()))
data.describe()
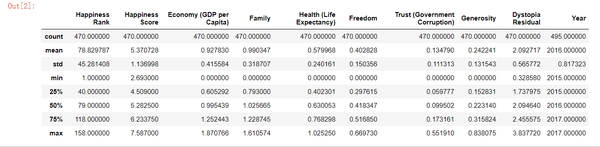
describe() 方法表明,“Happiness Rank”的范围从1到158,这意味着一年中受访国家的最大数量为158个。值得注意的是,“幸福排名”最初是int类型。 事实上,它显示为浮点,这意味着我们在这个列中有NaN值(我们也可以通过计数行来确定这个值,而这个行数只有470,而不是我们的数据集中的495行)。
“Year ”列没有任何缺失值。 首先,因为它在数据集中显示为int,而且 - Year的计数为495,这是我们的数据集中的行数。 通过将Year的计数值与其他列进行比较,似乎我们可以预期每列中有25个缺省值(在所有其他列中的年VS470中为495)。
按年份和地区分类数据
关于pandas pivot_table的有趣的事情是您只需一行代码即可获得数据的另一个观点。 大多数的pivot_table参数使用默认值,因此必须添加的唯一必需参数是数据和索引。 虽然这不是强制性的,但我们还将在下一个示例中使用value参数。
- 数据是不言而喻的 - 您需要使用DataFrame
- index是要对数据分组的列,分组器,数组(或上一个列表)。 它将显示在索引列(或列,如果您在列表中传递)
- 值(可选)是您要聚合的列。 如果不指定,那么该函数将聚合所有数字列。
我们先看看输出,然后解释表的生成方式:
pd.pivot_table(data, index= 'Year', values= "Happiness Score")
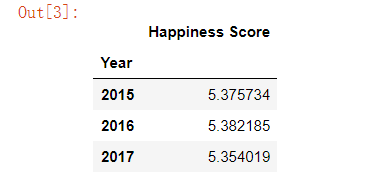
通过将Year作为索引参数,我们选择按Year分组我们的数据。 输出是一个数据透视表,显示Year的三个不同值作为索引,Happiness Score作为值。 值得注意的是,汇总默认值是平均值(或平均值),因此“幸福得分”列中显示的值是所有国家的年平均值。 该表显示,2016年所有国家的平均水平最高,目前是过去三年来的最低水平。
下面是如何创建这个数据透视表的详细图表:

接下来,我们使用Region列作为索引:
pd.pivot_table(data, index = 'Region', values="Happiness Score")
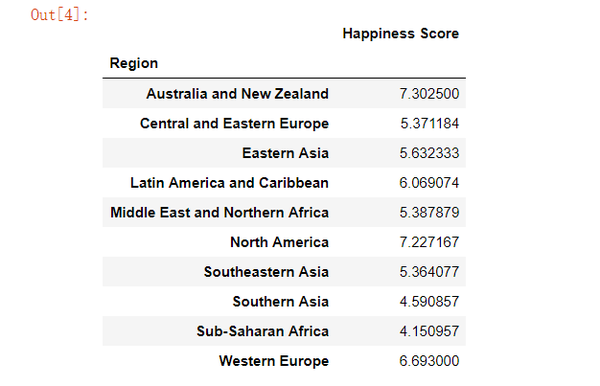
上面的数据透视表中Happiness Score栏中显示的数字是与以前一样的平均值,但这次是每个区域所有年份的平均值(2015年,2016年,2017年)。 这样展示使得澳大利亚和新西兰的平均得分最高,而北美则比较接近。 有趣的是,尽管我们从阅读数据得到的初步印象,这显示西欧在绝大多数顶级地区,但西欧计算过去三年的平均水平确实排在第三位。 排名最低的地区是撒哈拉以南非洲地区,而靠近南亚。
创建多索引数据透视表
您可能已经使用groupby() 来实现某些数据透视表功能(以前我们已经演示了如何使用groupby()来分析数据)。 然而,pivot_table() 内置函数提供了简单的参数名称和默认值,可以帮助简化复杂的过程,如多索引。
为了将数据分组多列,我们要做的就是传递列名列表。 我们按地区和年份对数据进行分类。
pd.pivot_table(data, index = ['Region', 'Year'], values="Happiness Score")
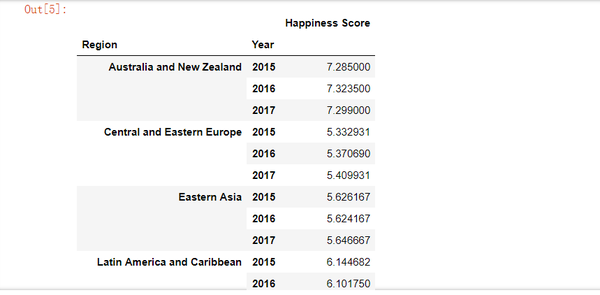
这些示例还显示了数据透视表的名称:它允许您旋转或转动汇总表,并且此旋转为我们提供了不同的数据透视图。 一个可以很好地帮助您快速获得宝贵见解的方法。
这是查看数据的一种方法,但是我们可以使用columns参数来获得更好的显示:
- 列是您希望将数据分组的上一列的列,grouper,array或列表。 使用它将水平扩展不同的值。
使用Year作为Columns参数将显示年份的不同值,并将使得更好的显示,如下所示:
pd.pivot_table(data, index= 'Region', columns='Year', values="Happiness Score")
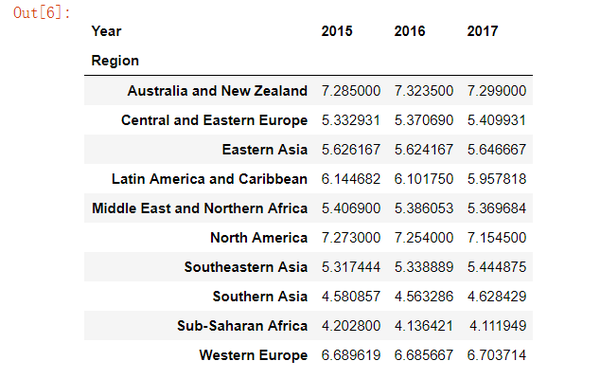
使用plot() 可视化数据透视表
如果要查看我们创建的上一个数据透视表的可视化表示,您需要做的就是在pivot_table函数调用结束时添加plot() 您还需要导入相关的绘图库)。
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# 使用Seaborn
sns.set()
pd.pivot_table(data, index= 'Region', columns= 'Year', values= "Happiness Score").plot(kind= 'bar')
plt.ylabel("Happiness Rank")
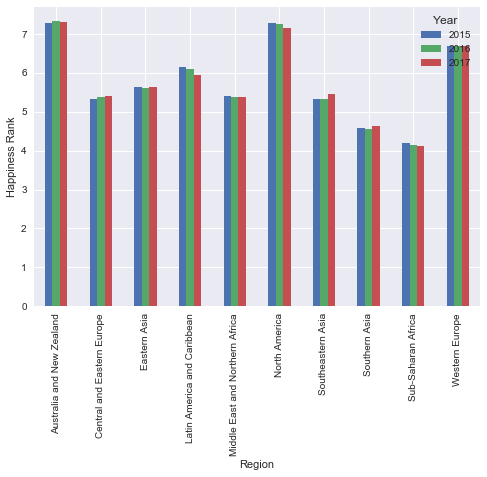
可视化表示有助于揭示差异较小。 话虽如此,这也表明,位于美国的两个地区的幸福级别都在持续下降。
使用aggfunc处理数据
到目前为止,我们已经使用平均值来获取有关数据的见解,但还有其他重要的值要考虑。 尝试使用aggfunc参数的时间:
- aggfunc(可选)接受要在组上使用的函数或函数列表(默认值:numpy.mean)。 如果函数列表被传递,则生成的数据透视表将具有顶层是函数名的分层列。
我们添加每个区域的中位数,最小值,最大值和标准偏差。 这可以帮助我们评估平均值的准确程度,如果它真正代表真实的图像。
pd.pivot_table(data, index= 'Region', values= "Happiness Score",
aggfunc= [np.mean, np.median, min, max, np.std])
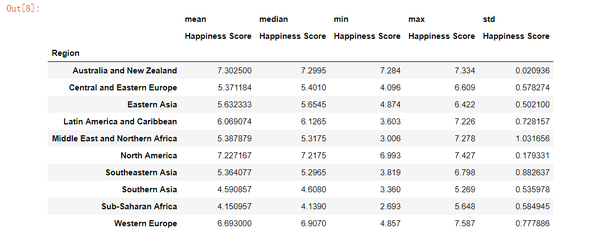
看起来像某些地区的极值值可能会影响我们的平均水平超过我们想要的。
- 例如,中东和北非地区的标准差偏高,所以我们可能想要消除极端的价值。 让我们看看我们为每个地区计算的价值。 这可能会影响我们看到的表示。
- 例如,澳大利亚和新西兰的标准偏差非常低,并且在三年内都是最幸福的,但是我们也可以假设他们仅仅是两个国家。
应用自定义函数来删除异常值
pivot_table允许您将自己的自定义聚合函数作为参数传递。 您可以使用lambda函数,也可以创建一个函数。 我们来计算一个特定年份每个地区的平均国家数。 我们可以轻松地使用lambda函数,就像这样:
pd.pivot_table(data, index = 'Region', values="Happiness Score",
aggfunc= [np.mean, min, max, np.std, lambda x: x.count()/3])
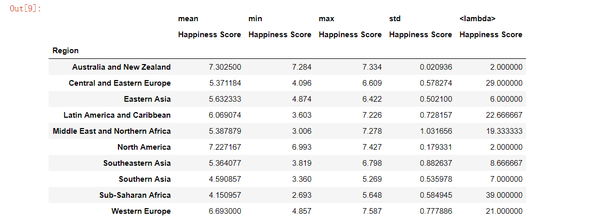
标准差最低的最高排名地区只占两个国家。 另一方面,撒哈拉以南非洲地区的幸福得分最低,但却达43个国家。
下一步有趣的做法是从计算中去除极值,看排名是否发生显着变化。 我们创建一个仅计算介于0.25和0.75之间的值的函数。 我们将使用此函数作为计算每个区域的平均值的方法,并检查排名是否保持不变。
def remove_outliers(values):
mid_quantiles = values.quantile([.25, .75])
return np.mean(mid_quantiles)
pd.pivot_table(data, index = 'Region', values="Happiness Score",
aggfunc= [np.mean, remove_outliers, lambda x: x.count()/3])
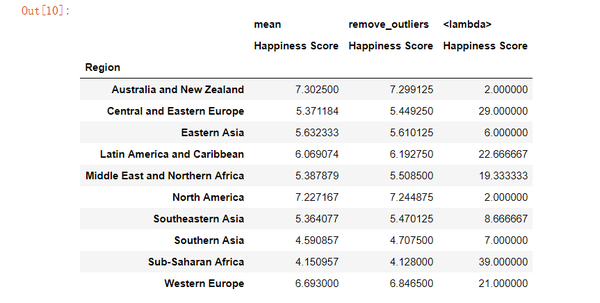
消除异常值主要影响到拥有更多国家的地区,这是有道理的。
我们可以看到西欧(每年接受调查的21个国家的平均水平)提高了排名。 不幸的是,当我们删除离群值时,撒哈拉以南非洲地区(平均每年接受调查的39个国家)获得了更低的排名。
使用字符串操作分类
到目前为止,我们已经根据原始表格中的类别分组了我们的数据。 但是,我们可以搜索类别中的字符串来创建我们自己的组。
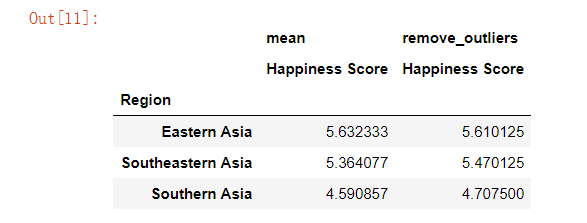
例如,看大陆的结果会很有趣。 我们可以通过查找包含亚洲,欧洲等的区域名称来做到这一点。为此,我们可以先将我们的数据透视表指定给一个变量,然后添加我们的过滤器:
table = pd.pivot_table(data, index = 'Region', values="Happiness Score",
aggfunc= [np.mean, remove_outliers])
table[table.index.str.contains('Asia')]
欧洲的结果:
table[table.index.str.contains('Europe')]

差异表明,两个欧洲地区幸福得分差异较大。 在大多数情况下,去除异常值使得分数更高,但在东亚则不高。
如果要从多个列中提取特定的值,那么最好使用df.query,因为以前的方法不适用于调整多重索引。 例如,我们可以选择查看特定年份,以及非洲地区的具体地区。
table = pd.pivot_table(data, index = ['Region', 'Year'], values='Happiness Score',
aggfunc= [np.mean, remove_outliers])
table.query('Year == [2015, 2017] and Region == ["Sub-Saharan Africa", "Middle East and Northern Africa"]')
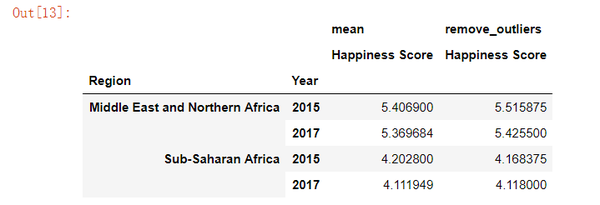
在这个例子中,差异是微不足道的,但有趣的是,自从2012年以来调查报告以来,比较前几年的信息。
处理丢失的数据
迄今为止,我们已经介绍了pivot_table中最强大的参数,因此如果您在自己的项目中使用此方法进行实验,那么您已经可以获得很多参数。 话虽如此,快速浏览剩余的参数(都是可选的,具有默认值)很有用。 首先要谈的是缺少值。
- dropna类型为boolean,用于表示您不想包含条目全部为NaN的列(默认值:True)
- fill_value是类型标量,用于选择替换缺省值的值(默认值:无)
我们没有任何所有条目都是NaN的列,但是值得一提的是,如果我们做了pivot_table,那么默认情况下会根据dropna定义删除它们。
我们一直让pivot_table根据默认设置对待我们的NaN。 fill_value的默认值为None,这意味着我们没有在数据集中替换缺少的值。 为了证明这一点,我们需要生成一个具有NaN值的数据透视表。 我们可以将每个地区的幸福得分分为三个分位数,并检查有多少个国家属于三个分位数(希望至少有一个分位数将缺少值)。
要做到这一点,我们将使用qcut(),它是一个内置的熊猫功能,可以让您将数据分割成您选择的任何数位数。 例如,指定 pd.qcut(data["Happiness Score"], 4)将导致四个分位数:
- 0-25%
- 25%-50%
- 50%-75%
- 75%-100%
# 将Happiness Score分为3个分位数
score = pd.qcut(data["Happiness Score"], 4)
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count').head(9)
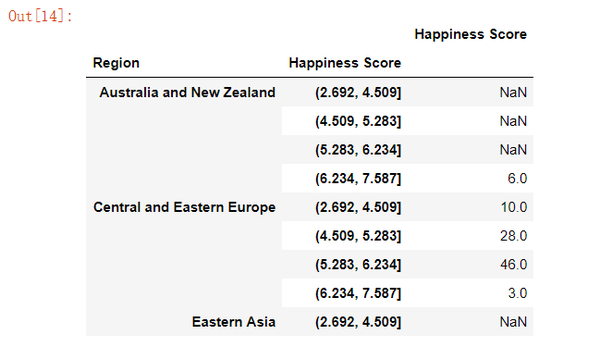
没有国家的地区在特定的分位数显示NaN。 这不是理想的,因为等于NaN的计数不给我们任何有用的信息。 显示0不太困惑,所以让我们使用fill_value替换NaN:
# 将幸福分数分为3个分位数
score = pd.qcut(data["Happiness Score"], 3)
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count',
fill_value= 0)
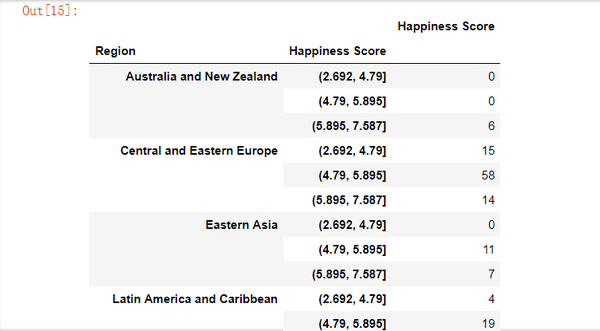
添加总行/列
最后两个参数既可选,也可用于改进显示:
- margins 是布尔型,允许您添加所有行/列,例如。 小计/总计(默认False)
- marginins_name是类型字符串,并接受当边距为True时将包含总计的行/列的名称(默认为“All”)
让我们用这些来添加一个我们最后一个表。
# 将幸福分数分为3个分位数
score = pd.qcut(data['Happiness Score'], 3)
# 创建一个数据透视表,只显示前9个值
pd.pivot_table(data, index= ['Region', score], values= "Happiness Score", aggfunc= 'count', fill_value= 0,
margins = True, margins_name= 'Total count')
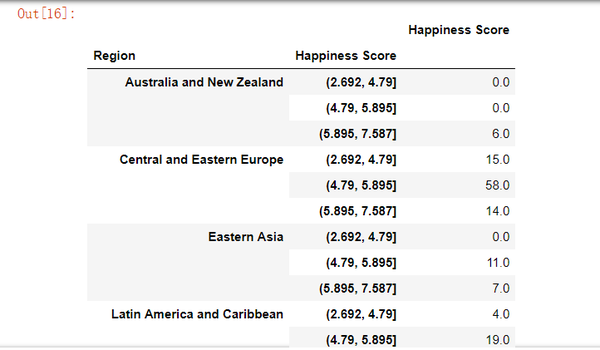
总结
如果您正在寻找从不同角度检查数据的方法,那么pivot_table就是答案。 它很容易使用,它对数字和分类值都有用,它可以通过一行代码获得结果。
如果您喜欢挖掘这些数据,并且您有兴趣进一步调查,那么我们建议添加前几年的调查结果,和/或将其他列与国家信息相结合,如贫困,恐怖,失业等。随时分享您的 笔记本在下面的评论中,享受你的学习!
