

前言
前两篇介绍了可读/可写流,那么这两篇文章掌握的话,第三篇文章便不在话下.毕竟这篇介绍的duplex流和transform流都是在继承自可读/可写流的.所以它们具备了二者的所有属性以及方法.因此我们这篇文章只会简单介绍一些之前没有提到的东西,也就是属于它们自己独有的一些东西.
1. Duplex流
duplex流是将可读流和可写流结合一起,看下面代码就知道继承了二者的所有属性和方法:
util.inherits(Duplex, Readable);
var keys = Object.keys(Writable.prototype);
for (var v = 0; v < keys.length; v++) {
var method = keys[v];
if (!Duplex.prototype[method])
Duplex.prototype[method] = Writable.prototype[method];
}
NOTE 因为JS不支持继承多个父类,所以上面的代码是原型式继承stream.Readable以及寄生式继承stream.Writable,但是我们如果使用instanceof来验证两个基类也是没问题的,因为我们在stream.Writable上重写了Symbol.hasInstance.
相关代码是在_stream中的这么一段:
// Test _writableState for inheritance to account for Duplex streams,
// whose prototype chain only points to Readable.
var realHasInstance;
if (typeof Symbol === 'function' && Symbol.hasInstance) {
realHasInstance = Function.prototype[Symbol.hasInstance];
Object.defineProperty(Writable, Symbol.hasInstance, {
value: function(object) {
if (realHasInstance.call(this, object))
return true;
return object && object._writableState instanceof WritableState;
}
});
} else {
realHasInstance = function(object) {
return object instanceof this;
};
}
具体验证可以看下面的demo
1.1 新建duplex流
使用最最基本的语法来新建duplex流:
const { Duplex } = require('stream');
class MyDuplex extends Duplex {
constructor(options) {
super(options);
// ...
}
}
1.2 操作双工流
关于duplex流需要知道一个最重要的点是可读流和可写流是完全独立,我们可以通过下面的实例来验证:
class MyDuplex extends Duplex {
constructor(options) {
super(options);
// ...
}
_write(chunk, encoding, callback) {
console.log('we write: ', chunk)
callback();
}
_read(size) {
this.push('read method')
this.push(null)
}
}
const dp = new MyDuplex({
readableObjectMode: true
})
console.log(dp instanceof Writable)
console.log(dp instanceof Readable)
dp.on('data', (chunk) => {
console.log('we read: ', chunk)
})
dp.write('write method', 'utf-8')
因为独立,所以在new一个duplex流的时候需要传递的option有:
- readableObjectMode/writableObjectMode
- readableHighWaterMark/writableHighWaterMark
在option中还有另外一个配置--allowHalfOpen,用来标识是否允许半双工状态,如果置为false的话,当可读流关掉的时候可写流也会自动关掉。
因为是继承了可写流和可读流,所以它要实现的方法就是之前可读流和可写流实现的方法,即:_read, _write, _writev, _final。
具体的用法就不再赘述了。
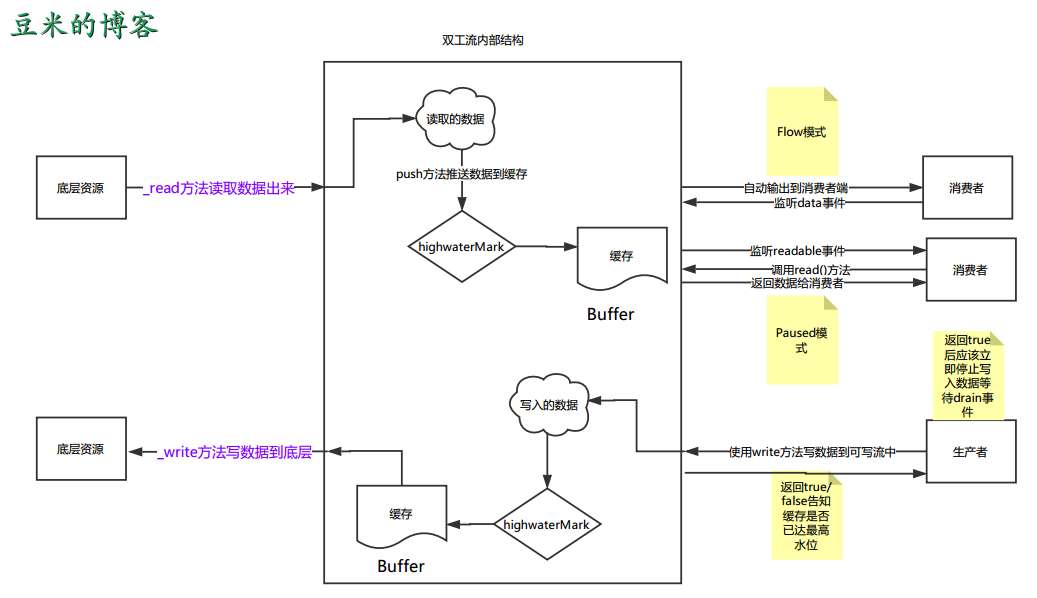
双工流的的大致原理如下:
2. Transform流
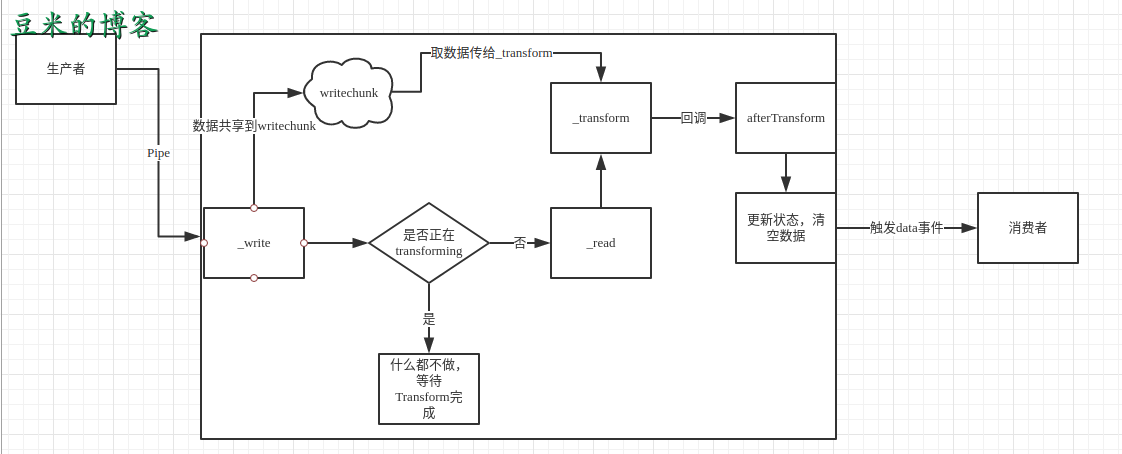
Transform流之所以叫做Transform,就是因为它可以对流数据进行“变形”,也就是说输出的数据与输入的数据是有一个映射关系,是将输入数据进行一定地加工再输出去的。比如zlib/crypto流。比如下面类似的模型:
stream.Transform类原型式地继承自stream.Duplex并且实现了自己的writable._write()和readable._read()
我们实现自定义Transform流必须实现transform._transform()方法,另外可能也需要实现transform._flush()方法。
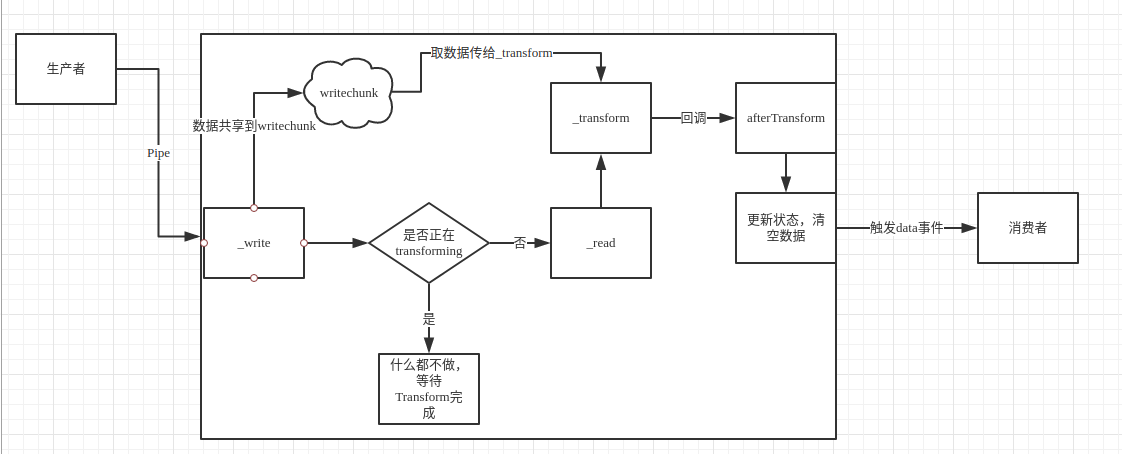
Transform流实现的图示大致如下:
2.1. 新建Transform流
使用ES6的语法新建一个Transform流,如下:
const { Transform } = require('stream')
class myTransform extends Transform {
constructor(options) {
super(options);
}
_transform(data, encoding, done) {}
_flush(cb){}
}
const tss = new myTransform()
在myTransform中有_transform方法以及_flush方法。我们来说说这两种方法的用途。
2.1.1 _transform(chunk, encoding, callback)方法
首先我们需要明确地一点就是加_的方法都是不允许外部直接调用的,有点类似于Typescript的private。
其次该方法是用于接受输入并产生输出的一个中转站,该方法内部实现对写入的字节进行操作,然后计算出一个输出,最后将输出使用readable.push()方法传递给可读流。
callback函数必须在当前块完全消耗完毕之后调用,如果在处理输入的时候发生错误的时候回调的第一个参数必须是一个Error对象,否则是一个null。如果回调有第二个参数的话,它将会转发给readable.push()。
在源码中我们可以看到Transform流重写的_read方法回去调用_transform:
// Doesn't matter what the args are here.
// _transform does all the work.
// That we got here means that the readable side wants more data.
Transform.prototype._read = function(n) {
var ts = this._transformState;
if (ts.writechunk !== null && ts.writecb && !ts.transforming) {
ts.transforming = true;
this._transform(ts.writechunk, ts.writeencoding, ts.afterTransform);
} else {
// mark that we need a transform, so that any data that comes in
// will get processed, now that we've asked for it.
ts.needTransform = true;
}
};
并且在源码我们也看到了_transform的回调afterTransform,该函数直接做些状态更新,判断是否还有数据,如果有的话调用push方法。接着判断可读流是否还需要读取,如果需要的话直接读取可读流的最高水位的数据。如下:
var rs = this._readableState;
rs.reading = false;
if (rs.needReadable || rs.length < rs.highWaterMark) {
this._read(rs.highWaterMark);
}
2.2.2 _flush(callback)方法
在一些情况下,当流关闭的时候一个Transform操作也许需要发射一些额外的数据,这个时候就需要调用_flush方法。比如zlib压缩流将会存储大量的内部状态用于更好地压缩输出。当流结束的时候,那些额外的数据需要flushed出去,这样的压缩数据才会是完整的。
该方法在当前没有被写数据需要消费的时候被调用,但是应该在end事件触发告知结束可读流之前。在该方法实现的内部,push方法根据实际情况可能会被调用多次,callback则必须在刷新操作完成之后调用的。
在源码中调用flush方法的地方是:
...
// When the writable side finishes, then flush out anything remaining.
this.on('prefinish', prefinish);
...
function prefinish() {
if (typeof this._flush === 'function') {
this._flush((er, data) => {
done(this, er, data);
});
} else {
done(this, null, null);
}
}
可见当接收到可写流发射的prefinish事件的时候,去执行刷新操作,刷新完毕后调用done函数,done函数会检查当前流是否处于正常的结束状态下,另外如果还有数据会在调用push,最后才执行push(null)。整个流程才正式结束。
2.2.3 例子
综合上面的介绍,我们有这么一个demo,用来转换所有输入的字符变为大写的:
const { Transform } = require('stream')
class myTransform extends Transform {
constructor(options) {
super(options);
}
_transform(chunk, encoding, done) {
const upperChunk = chunk.toString().toUpperCase()
this.push(upperChunk)
done()
}
_flush(cb){
/* at the end, output the our additional info */
this.push('this is flush data\n')
cb(null, 'appending more data\n')
}
}
const tss = new myTransform()
tss.pipe(process.stdout)
tss.write('hello transform stream\n')
tss.write('another line\n')
tss.end()
输出应该是如你所料的了:
HELLO TRANSFORM STREAM
ANOTHER LINE
this is flush data
appending more data
下一篇文章我们将整合当前学习的内容来解决平时应用中的一些问题。
