

前言
在中文分词器中, IKAnalyzer 做的是相对不错的,有着细度分割和智能使用两个模式 。
但是,这个版本因为太陈旧,作者不再维护,(项目估计是。。。),所以与现在的Lucene 6.6 版本差距有些大。所以,我就根据网上各位大神的文章,加上自己对 API 与源码的阅读,稍微的进行了改动,可以简单的运行。
注: 这里的简单是指,可以简单的运行源码 中的简单案例。
正文
项目介绍
- IKAnaylzer版本: IK Analyzer 2012FF
感谢提供的分词源码 git.oschina.net/wltea/IK-An… - lucene 版本:lucene 6.60
代码改动
1. 对IKTokenizer的改动
源码
/**
* Lucene 4.0 Tokenizer适配器类构造函数
* @param in
* @param useSmart
*/
public IKTokenizer(Reader in, boolean useSmart) {
super(in);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input, useSmart);
}经查阅 lucene 源码
Tokenizer类的构造器已经不再接收 Reader 源码如下
protected Tokenizer() {
this.input = ILLEGAL_STATE_READER;
this.inputPending = ILLEGAL_STATE_READER;
}
protected Tokenizer(AttributeFactory factory) {
super(factory);
this.input = ILLEGAL_STATE_READER;
this.inputPending = ILLEGAL_STATE_READER;
}因此改动 IKTokenizer 类 ,如下
public IKTokenizer( boolean useSmart) {
super();
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
//传入 IKSegmenter 的 input Reader 流,会被 父类 Tokenizer 类的无参构造器
//初始化为 this.input = ILLEGAL_STATE_READER;
_IKImplement = new IKSegmenter(input, useSmart);
}去除了 Reader 形参 。 默认调用 父类 的 无参构造函数 Tokenizer()
注:在该博客下发现,还需要配置分词器工厂类,因此还要多增加一段构造器代码,如下
//方便创建 工厂类
public IKTokenizer(AttributeFactory factory, boolean useSmart) {
super(factory);
offsetAtt = addAttribute(OffsetAttribute.class);
termAtt = addAttribute(CharTermAttribute.class);
typeAtt = addAttribute(TypeAttribute.class);
_IKImplement = new IKSegmenter(input, useSmart);
}2. 对IKAnalyzer 的改动
源码
/**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in, this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
}lucene 6.6 关于 Analyzer 接口中 关于 createComponents() 方法的源码
protected abstract Analyzer.TokenStreamComponents createComponents(String var1);结合上文中对 IKTokenizer 源码的改动,因此需要去除 参数 Reader in
改动的代码 如下:
/**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName) {
Tokenizer _IKTokenizer = new IKTokenizer(this.useSmart());
return new Analyzer.TokenStreamComponents(_IKTokenizer);
}3. 对SWMCQueryBuilder 的改动
源码如下:
// 借助lucene queryparser 生成SWMC Query
QueryParser qp = new QueryParser(Version.LUCENE_43, fieldName, new StandardAnalyzer(
Version.LUCENE_43));
qp.setDefaultOperator(QueryParser.AND_OPERATOR);
qp.setAutoGeneratePhraseQueries(true);由于新版本的 lucene 已经不在使用 Version 类 进行定义,(我的上一篇lucene6.6 学习心得说的很清楚)因此需要将之移除。
移除后,改动版本如下:
//借助lucene queryparser 生成SWMC Query
QueryParser qp = new QueryParser(fieldName, new StandardAnalyzer());
qp.setDefaultOperator(QueryParser.AND_OPERATOR);
qp.setAutoGeneratePhraseQueries(true);4. 对IKQueryExpressionParser 的改动
IKQueryExpressionParser 类中方法 BooleanQuery ,在近期的 lucene 中有了较大改动,不知道的话,可以 查阅我的上一篇文章lucene6.6 学习心得.
因此源码中对 IKQueryExpressionParser 类中关于 BooleanQuery 的方法都需要进行更改。
因为方法中代码过多 , 因此,我选取其中比较关键的几个地方,进行展示。
关键源码如下:
private Query toBooleanQuery(Element op) {
BooleanQuery resultQuery = new BooleanQuery();
Query q2 = this.querys.pop();
Query q1 = this.querys.pop();
BooleanClause[] clauses = ((BooleanQuery) q1).getClauses();
resultQuery.add(c);
return resultQuery;
}改动代码如下:
1.数组版本
private Query toBooleanQuery(Element op){
BooleanQuery.Builder builder = new BooleanQuery.Builder();
Query q2 = this.querys.pop();
Query q1 = this.querys.pop();
//因为,我看源码,并没有发现会增删的地方 ,于是直接转成了数组
//迭代器版本的在下文
if(q1 instanceof BooleanQuery){
BooleanClause[] clauses =(BooleanClause[]) ((BooleanQuery)q1).clauses().toArray();
if(clauses.length > 0
&& clauses[0].getOccur() == Occur.MUST){
for(BooleanClause c : clauses){
builder.add(c);
}
}else{
builder.add(q1,Occur.MUST);
}
return builder.build();
}2.迭代器版本
private Query toBooleanQuery(Element op){
BooleanQuery.Builder builder = new BooleanQuery.Builder();
Query q2 = this.querys.pop();
Query q1 = this.querys.pop();
if(q1 instanceof BooleanQuery){
Iterator<BooleanClause> clauses = ((BooleanQuery) q1).iterator();
while (clauses.hasNext()) {
BooleanClause clause = clauses.next();
if (clause.getOccur() == Occur.MUST) {
builder.add(clause);
} else {
builder.add(q1,Occur.MUST);
}
}
return builder.build();
}5. 项目运行
打开包中的测试代码
1.IKAnalzyerDemo
运行结果如下图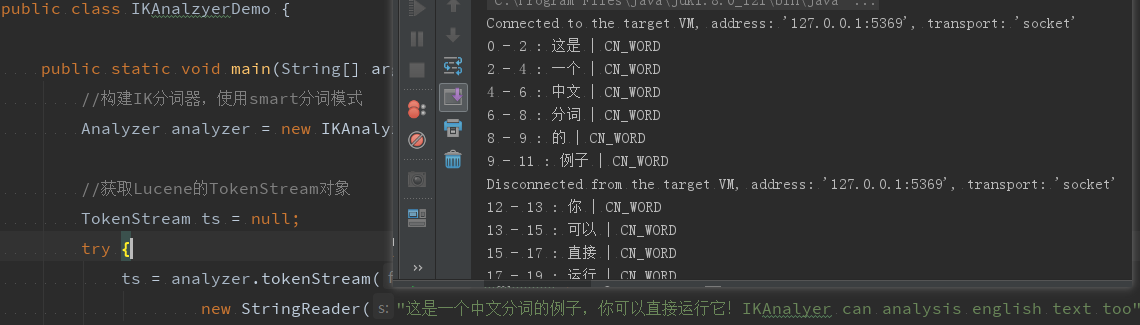
2.LuceneIndexAndSearchDemo
运行结果如下图
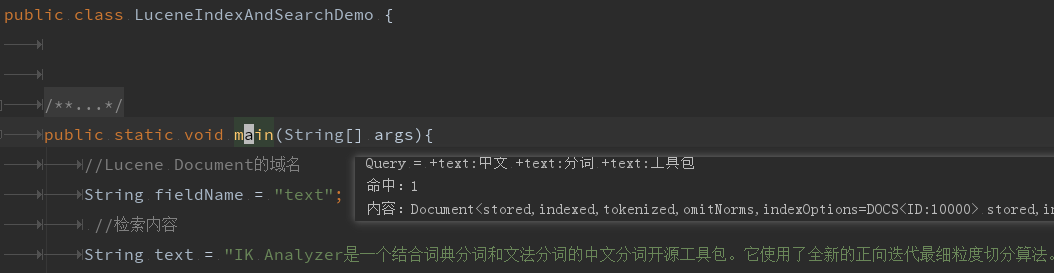
6. 源码与整合包的下载
源码与整合包 已经上传至我的 GitHub 上,有兴趣的可以去那里下载,不嫌弃的话,Star 一下 ,也是可以的哦~
