

- 原文地址:Scaling Node.js Applications
- 原文作者:Samer Buna
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:mnikn
- 校对者:shawnchenxmu,reid3290
扩展 Node.js 应用
你应该知道的在 Node.js 内置模块的应用于扩展的工具

来自 Pluralsight 课程中的截图 - Node.js 进阶
可扩展性在 Node.js 并不是事后添加的概念,这一概念在前期就已经体现出其核心地位。Node 之所以被命名为 Node 的原因就是强调一个想法:每一个 Node 应用应该由多个小型的分散 Node 应用相互联系来构成。
你曾经在你的 Node 应用上运行多个 Node 应用吗?你曾经试过让生产环境上的机器的每个 CPU 运行一个 Node 程序,并且对所有的请求进行负载均衡处理吗?你知道 Node 有一个内置模块能做上述事情吗?
Node 的 cluster 模块不只是提供一个黑箱的解决方案来充分利用机器中的 CPU,同时它也能帮助你提高 Node 应用的可用性,提供一个瞬时重启整个应用的选项,这篇文章将阐述其中的所有好处。
这篇文章是 Pluralsight Node.js 课程 中的一部分,我从视频中整理出了相关的内容。
实现扩展的策略
我们扩展一个应用的最主要的原因是应用的负载,但是不只是这一个原因。我们同时通过让应用具备可扩展性来提高应用的可用性和容错性。
我们可以通过三种主流的方式来拓展应用:
1 — 克隆
扩展一个大型应用最简单的方法就是多次克隆它,并让每一个克隆实例处理一部分工作(例如,使用负载均衡器)。这种做法不会占用开发周期太多时间,并且真的很管用。想要在最低限度上实现扩展,你可以使用这种方法,Node.js 有个内置模块 cluster 来让你在一个单一的服务器上更简单地实现克隆方法。
2 — 分解
同时我们也可以通过 分解 来扩展一个应用,这种方法取决于应用的函数和服务。这意味着我们有多个不同的应用,各有着不同的基架代码,有时还会有其独自的数据库和用户接口。
这个策略一般和微服务联系在一起,其中的微是指每个服务应该越小越好,但实际上,服务的规模无关紧要,为的是强迫人们解耦和让服务之间高内聚。实现这个策略并不容易,并有可能带来一系列预想不到的问题,但是其益处也是很显著的。
3 — 分离
我们同时也可以把应用分成多个实例,每个实例只负责应用的一部分数据。这个方法在数据库领域内通常被称为横向分割或碎片化。数据分割要求每一步操作前都需要查找当前在使用哪一个实例。例如,我们也许想要根据用户所在的国家或者所用的语言进行分区,首先我们需要查找相关信息。
成功扩展一个大型应用最终应该实现这三个策略。Node.js 让这一切变得简单,因此这篇文章我将会把注意力集中在克隆策略上,看看 Node.js 有什么可用的内置工具来实现这个策略。
请注意到在读这篇文章前你需要理解好 Node.js 的子进程。如果你不太了解,我建议你可以先读这篇文章:
cluster 模块
想要在同一环境下多个 CPU 的情况开启负载均衡,我们可以使用 cluster 模块。这基于子进程模块的 fork 方法,基本上它允许我们多次 fork 主应用并用在多个 CPU 上。然后它接管所有的子进程,并将所有对主进程的请求负载均衡到子进程中去。
Node.js 的 cluster 模块帮助我们实现可拓展性克隆策略,但是这只适用于在只有一台服务器上的情况。如果你有一台可以储存着大量的资源的服务器,或者在一台服务器上添加资源比增添新服务器更容易和便宜时,采用 cluster 模块来快速执行克隆策略是一个不错的选择。
即使是一个小型的服务器通常也会有多个内核,甚至如果你不担心 Node 服务器负载过重的话,可以任意开启 cluster 模块来提高服务器的可用性和容错性。执行这一步操作很简单,当你使用像 PM2 这样的进程管理器,你要做的就只是简单地给启动命令提供一个参数而已!
接着让我来跟你讲讲该如何使用原生的 cluster 模块,并且我会解释它是怎么工作的。
cluster 模块的结构很简单,我们创建一个 master 进程,并且让这个 master 进程 fork 多个 worker 进程并管理它们,每一个 worker 进程代表需要可拓展的应用的实例。所有请求都由 master 进程处理,这个进程会给每个 worker 进程分配其中一部分需要处理的请求。
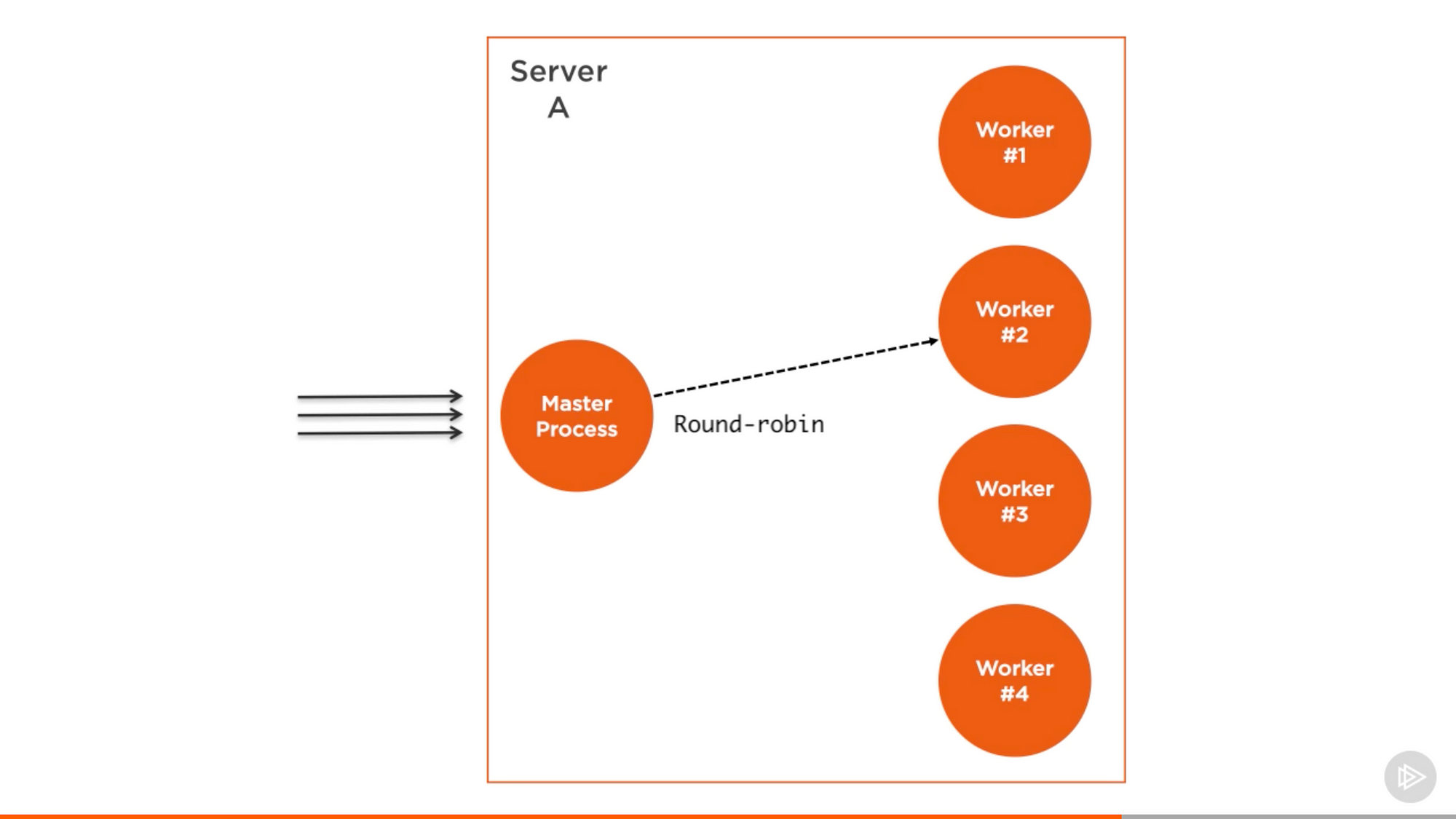
Pluralsight 课程上的截图 — Node.js 进阶
master 进程的工作很简单,实际上它只是使用轮替算法来挑选 worker 进程。除了 Windows 以外的操作系统都默认开启了这个算法,并且它能通过全局修改来让操作系统本身来处理负载均衡。
轮替算法让负载轮流地均匀分布在可用进程。第一个请求会指向第一个 worker 进程,第二个请求指向列表上的下一个进程,以此类推。当列表已经遍历完,算法会从头开始。
这是其中一种最简易并且也是最常用的负载均衡算法,但是并不是只有这一个。还有很多各具特色的算法能分配优先级和抽选负载最小或者响应速度最快的服务器。
HTTP 服务器上的负载均衡
让我们克隆一个简单的 HTTP 服务器并通过 cluster 模块实现负载均衡。这是一个简单的 Node hello-word 例子,我们修改一下让它模拟响应前的 CPU 工作。
// server.js
const http = require('http');
const pid = process.pid;
http.createServer((req, res) => {
for (let i=0; i<1e7; i++); // simulate CPU work
res.end(`Handled by process ${pid}`);
}).listen(8080, () => {
console.log(`Started process ${pid}`);
});为了检验负载均衡器我们需要创建一些东西来让它工作,我已经在 HTTP 响应中引进了程序 pid 来识别目前正在处理请求的应用的实例。
在我们使用 cluster 模块把服务器中的主进程克隆成多个 worker 进程之前,我们应该先调查下服务器每秒能够处理多少个请求。我们可以用 Apache 基准测试工具 来做这件事。在运行 server.js 之前,我们先执行 ab 命令:
ab -c200 -t10 http://localhost:8080/这个命令会在 10 秒内发起 200 个并发连接来测试服务器的负载性能。
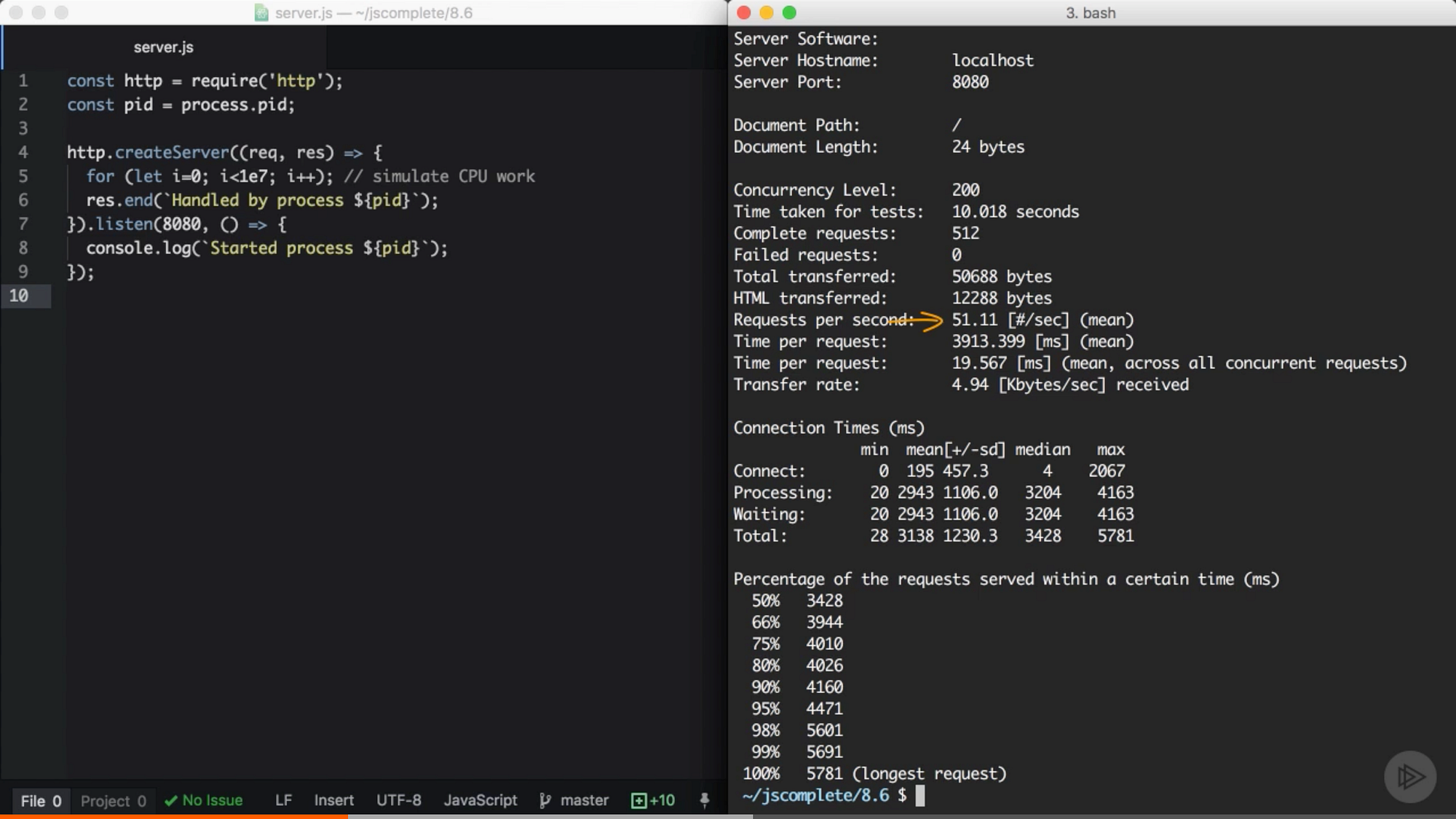
来自 Pluralsight 课程中的截图 — Node.js 进阶
在我的服务器上,单独一个 node 服务器每秒可以处理 51 个请求。当然,结果会随着平台的不同而有所变化,这只是一个非常简化的性能测试,并不能保证结果 100% 准确,但是它将会清晰地显示 cluster 模块给多核的应用环境所带来的不同。
既然我们有了一个参照的基准,我们就可以通过 cluster 模块来实现克隆策略,以此来拓展一个应用的规模。
在 server.js 的同级目录上,我们可以创建一个名叫 cluster.js 的新文件,用来提供 master 进程:
// cluster.js
const cluster = require('cluster');
const os = require('os');
if (cluster.isMaster) {
const cpus = os.cpus().length;
console.log(`Forking for ${cpus} CPUs`);
for (let i = 0; i<cpus; i++) {
cluster.fork();
}
} else {
require('./server');
}在 cluster.js 文件里,我们首先引入 cluster 和 os 模块,我们需要 os 模块里的 os.cpus() 方法来得到 CPU 的数量。
cluster 模块给了我们一个便利的 Boolean 参数 isMaster 来确定 cluster.js 是否正在被 master 进程读取。当我们第一次执行这个文件时,我们会执行在 master 进程上,因此 isMaster 为 true。在这种情况下,我们让 master 进程多次 fork 我们的服务器,直到 fork 的次数达到 CPU 的数量。
现在我们只是通过 os 模块来读取 CPU 的数量,然后对这个数字进行一个 for 循环,在循环内部调用 cluster.fork 方法。for 循环将会简单地创建和 CPU 数量一样多的 worker 进程,以此来充分利用服务器可用的计算能力。
当 cluster.fork 这一行在 master 进程中被执行时,当前的 cluster.js 文件会再运行一次,但是这一次是在 worker 进程,其中的 isMaster 参数为 false。实际上在这种情况下,另外一个参数将为 true,这个参数是 isWorker 参数。
当应用运行在 worker 进程上,它开始做实际的工作。我们就在这里定义服务器的业务逻辑,例如,我们可以通过请求已经有的 server.js 文件来实现业务逻辑。
基本就是这样了。这样就能简单地充分利用服务器的计算能力。想要测试 cluster,运行 cluster.js 文件:
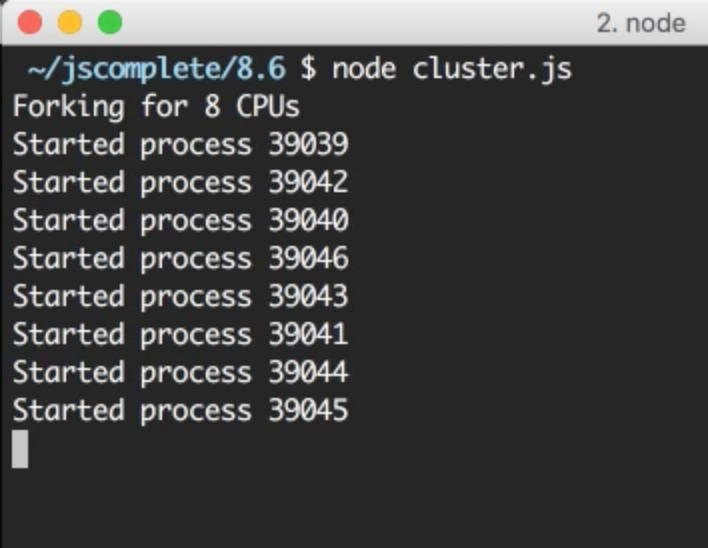
来自 Pluralsight 课程中的截图 — Node.js 进阶
我的服务器有 8 核因此我要开启 8 个进程。其中重要的是要理解它们和 Node.js 里的进程完全不同。每个 worker 进程有其独自的事件循环和内存空间。
当我们多次请求网络服务器,这些请求将会由不同的 worker 进程处理,worker 进程的 id 也各不相同。序列里的 worker 进程不会准确地进行轮换,因为 cluster 模块在挑选下一个处理请求的 worker 进程时进行了一些优化,负载会分布在不同的 worker 进程中。
我们同样可以使用先前的 ab 命令来测试 cluster 中的进程的负载:
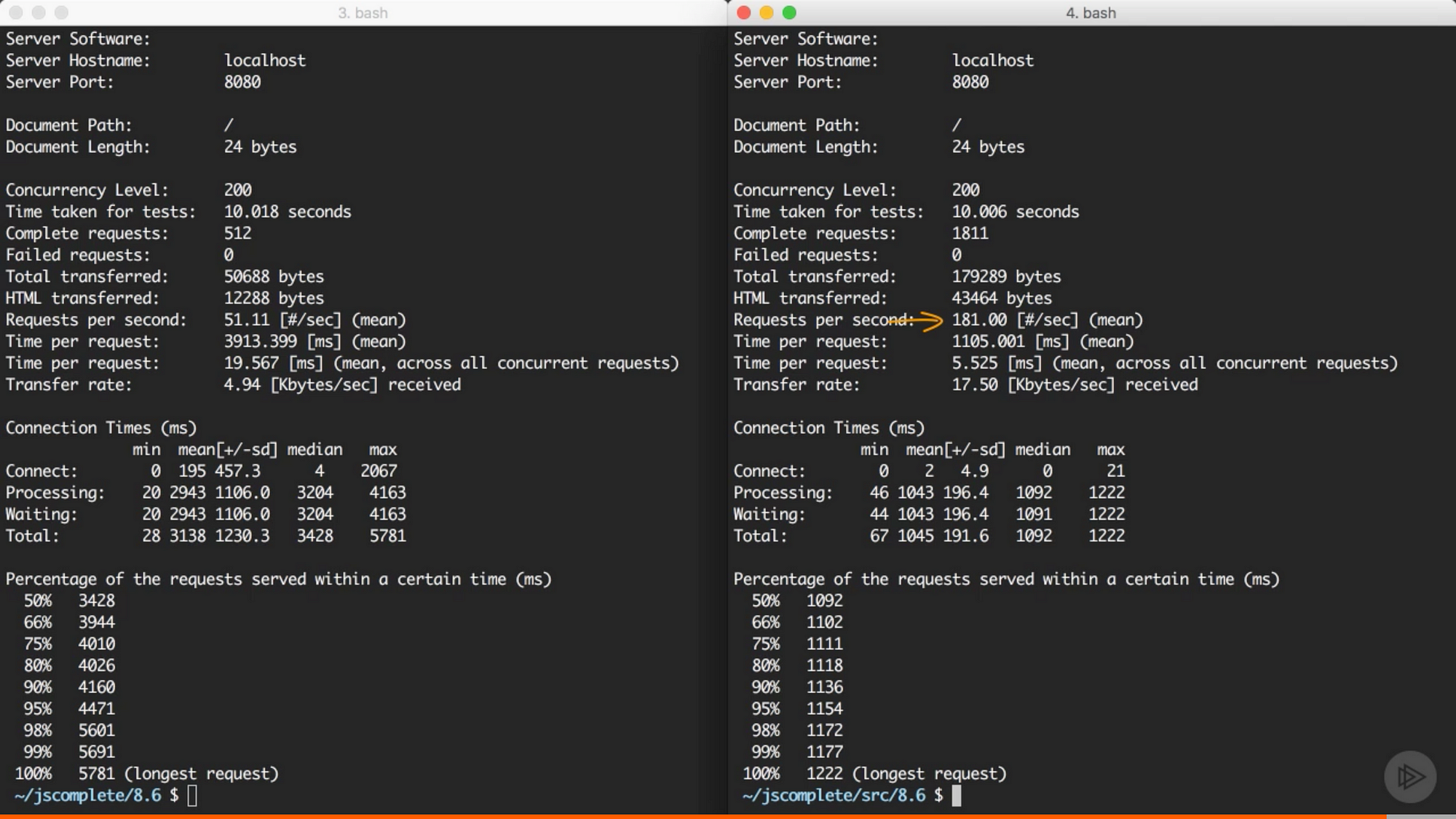
来自 Pluralsight 课程中的截图 — Node.js 进阶
同样是单独的 node 服务器,创建 cluster 后服务器每秒能够处理 181 个请求,没用 cluster 模块之前每秒只能处理 51 个请求。我们只是增加了几行代码,应用的性能就提高了 3 倍。
广播所有 Worker 进程
master 进程与 worker 进程之间能够简单地进行通信,因为 cluster 模块有个 child_process.fork 的 api,这意味着 master 进程与每个 worker 进程之间进行通信是可能的。
基于 server.js/cluster.js 的例子,我们可以用 cluster.workers 获取一个包含所有 worker 对象的列表,该列表持有所有 worker 的引用,并可以通过这个引用来读取 worker 的信息。有了让 master 进程和 worker 进程通信的方法后,想要广播每个 worker 进程,我们只需要简单地遍历所有的 worker。例如:
Object.values(cluster.workers).forEach(worker => {
worker.send(`Hello Worker ${worker.id}`);
});通过 Object.values 可以从 cluster.workers 对象里简单地来获取一个包含所有 worker 的数组。然后对于每个 worker,我们使用 send 函数来传递任意我们要传的值。
在一个 worker 文件里,在我们的例子中 server.js 要读取从 master 进程中收到的消息,我们可以在全局 process 对象中给 message 事件注册一个 handler。
process.on('message', msg => {
console.log(`Message from master: ${msg}`);
});当我在 cluster/server 上测试这两项新加的东西时所看到:
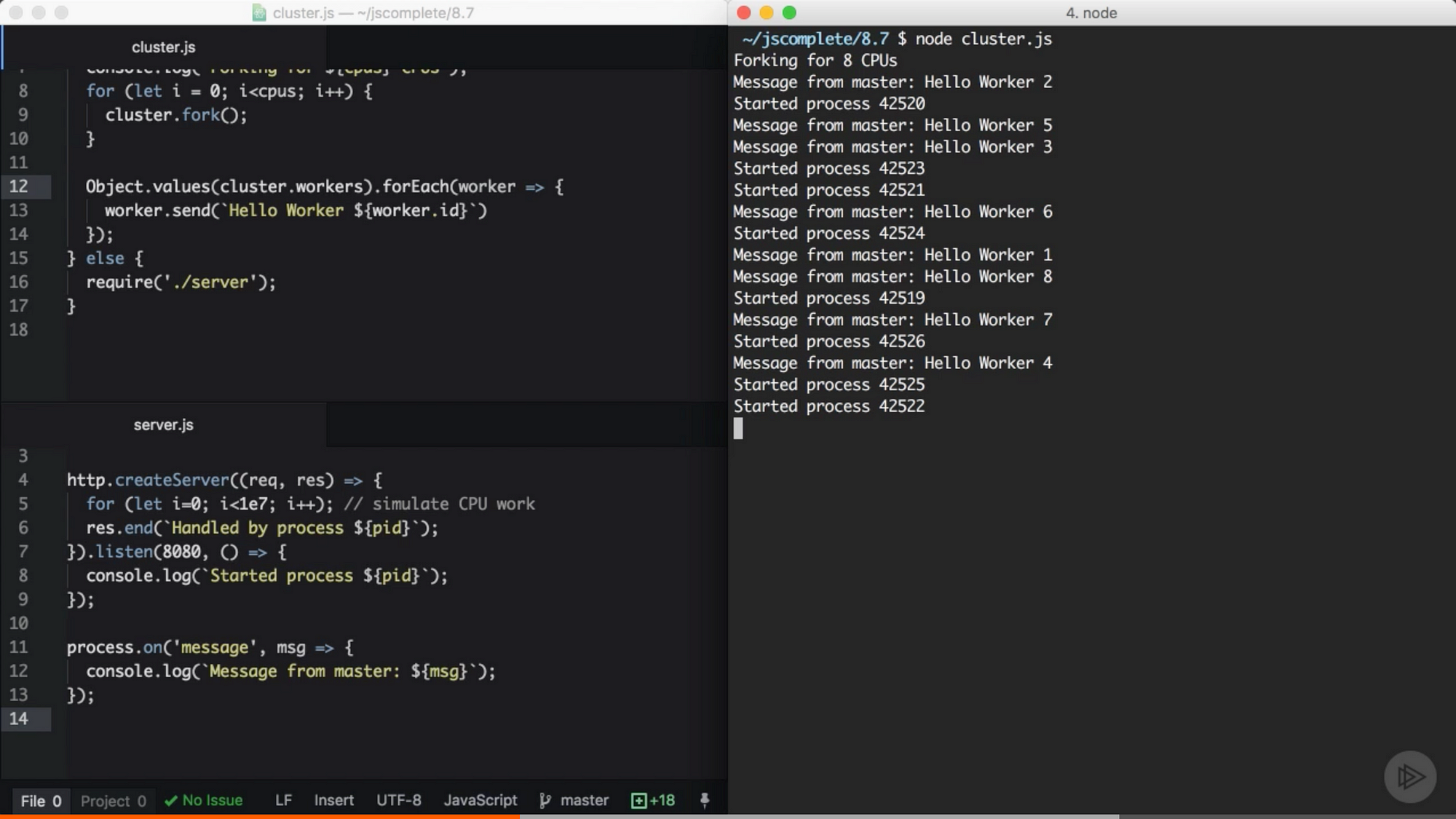
来自 Pluralsight 课程中的截图 — Node.js 进阶
每个 worker 都收到了来自 master 进程的消息。注意到 worker 的启动是乱序的。
这次我们让通信的内容变得更实际一点。这次我们想要服务器返回数据库中用户的数量。我们将会创建一个 mock 函数来返回数据库中用户的数量,并且每次当它被调用时对这个值进行平方处理(理想情况下的增长):
// **** 模拟 DB 调用
const numberOfUsersInDB = function() {
this.count = this.count || 5;
this.count = this.count * this.count;
return this.count;
}
// ****每次 numberOfUsersInDB 被调用,我们会假设已经连接数据库。我们想要避免多次数据库的请求,因此我们会根据一定时间对调用进行缓存,例如每 10 秒缓存一次。然而,我们仍然不想让 8 个 forked worker 使用独自的数据库连接和每 10 秒关闭 8 个数据库连接。我们可以让 master 进程只请求一次数据库连接,然后通过通信接口告诉这 8 个 worker 用户数量的最新值。
例如,在 master 进程模式中,我们同样可以遍历所有 worker 来广播用户数量的值:
// 在 isMaster=true 的状态下进行 fork 循环后
const updateWorkers = () => {
const usersCount = numberOfUsersInDB();
Object.values(cluster.workers).forEach(worker => {
worker.send({ usersCount });
});
};
updateWorkers();
setInterval(updateWorkers, 10000);这里第一次我们调用了 updateWorkers,然后通过 setInterval 每 10 秒调用这个方法。这样的话,每 10 秒所有的 worker 会以通信的形式收到用户数量的值,并且我们只需要创建一次数据库连接。
在服务端的代码,我们可以从同样的 message 事件 handler 中拿到 usersCount 的值。我们简单地用一个模块全局变量缓存这个值,这样我们在任何地方都能使用它。
例如:
const http = require('http');
const pid = process.pid;
let usersCount;
http.createServer((req, res) => {
for (let i=0; i<1e7; i++); // simulate CPU work
res.write(`Handled by process ${pid}\n`);
res.end(`Users: ${usersCount}`);
}).listen(8080, () => {
console.log(`Started process ${pid}`);
});
process.on('message', msg => {
usersCount = msg.usersCount;
});上面的代码让 worker 的 web 服务器用缓存的 usersCount 进行响应。如果你现在测试 cluster 的代码,前 10 秒你会从所有的 worker 里得到用户数量为 “25”(同时只创建了一个数据库连接)。然后 10 秒过后,所有的 worker 开始报告当前的用户数量,625(同样只创建了一个数据库连接)。
得力于 master 进程和 worker 之间通信的方法的存在,我们能够做到这一切。
提高服务器的可用性
我们在运行单独一个 Node 应用的实例时有一个问题,就是当这个实例崩溃时,我们必须重启整个应用。这意味着崩溃后的重启之间会存在一个时间差,即使我们让这项操作自动执行也是一样的。
同理当服务器想要部署新代码就必须重启。只有一个实例,为此所造成的时间差会影响系统的可用性。
而如果我们有多个实例的话,只需添加寥寥数行代码就可以提高系统的可用性。
为了在服务器中模拟随机崩溃,我们通过一个 timer 来调用 process.exit,让它随机执行。
// 在 server.js 文件
setTimeout(() => {
process.exit(1) // 随时退出进程
}, Math.random() * 10000);当一个 worker 进程因崩溃而退出,cluster 对象里的 exit 事件会通知 master 进程。我们可以给这个事件注册一个 handler,并且当其他 worker 进程还存在时让它 fork 一个新的 worker 进程。
例如:
// 在 isMaster=true 的状态下进行 fork 循环后
cluster.on('exit', (worker, code, signal) => {
if (code !== 0 && !worker.exitedAfterDisconnect) {
console.log(`Worker ${worker.id} crashed. ` +
'Starting a new worker...');
cluster.fork();
}
});这里我们添加一个 if 条件来保证 worker 进程真的崩溃了而不是手动断开连接或者被 master 进程杀死了。例如,我们使用了太多的资源超出了负载的上限,因此 master 进程决定杀死一部分 worker。因此我们调用 disconnect 方法给任意 worker,这样 exitedAfterDisconnect flag 就会设为 true。if 语句会保证不会因此而 fork 新的 worker。
如果我们带着上面的 handler 运行 cluster(同时 server.js 里有随机的崩溃的代码),在随机数秒过后,worker 会开始崩溃,master 进程会立刻 fork 新的 worker 来提高系统的可用性。你同样可以用 ab 命令来衡量可用性,看看服务器有多少的请求没有处理(因为有一些请求会不走运地遇到无法避免的崩溃)。
当我测试这段代码,10 秒内请求 1800 次,其中有 200 次并发请求,最后只有 17 次请求失败。
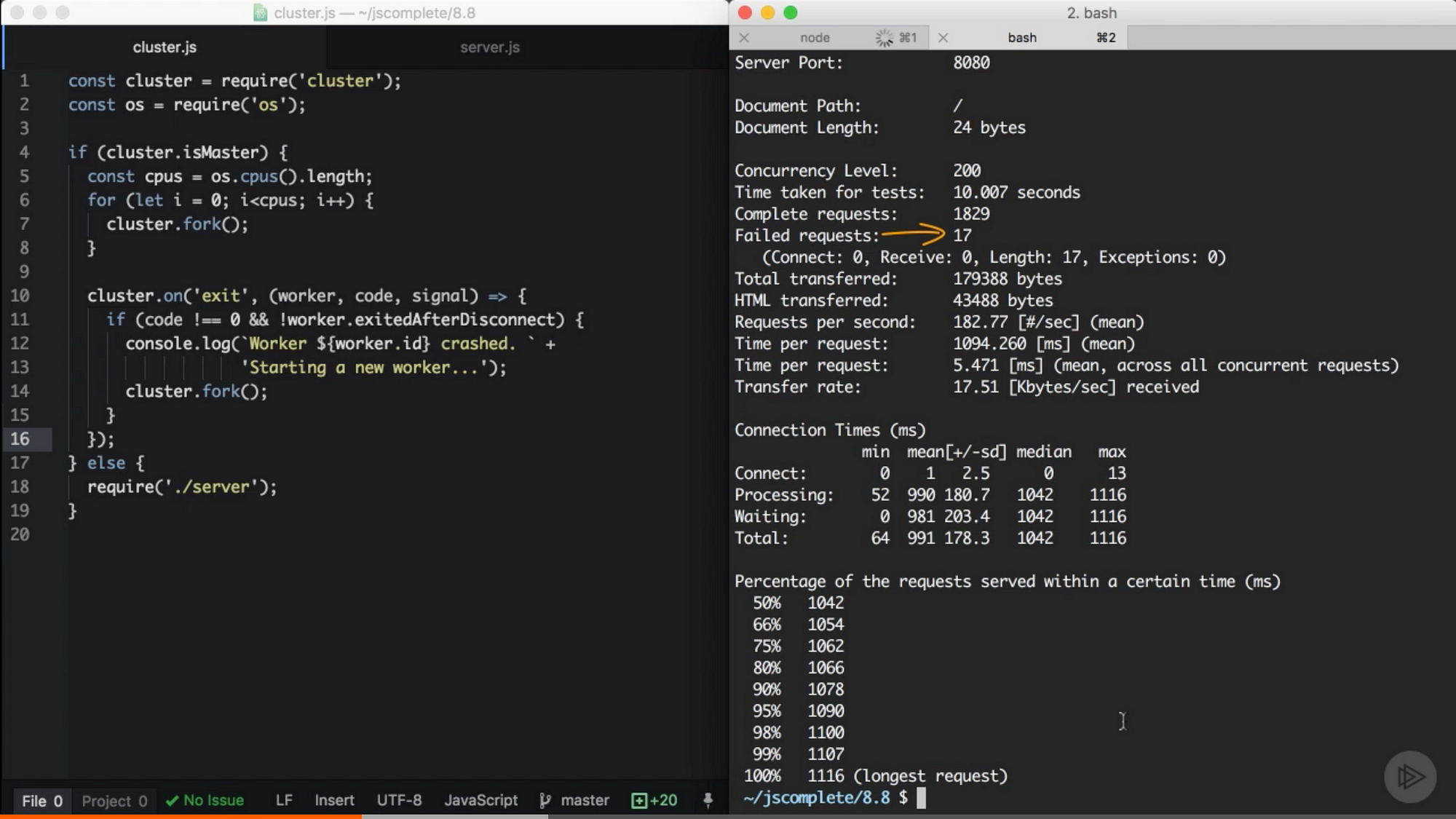
来自 Pluralsight 课程中的截图 — Node.js 进阶
这有 99% 以上的可用性。只是添加数行代码,现在我们不再担心进程崩溃了。master 守护将会替我们关注这些进程的情况。
瞬时重启
那当我们想要部署新代码,而不得不重启所有的 worker 进程时该怎么办呢?
我们有多个实例在运行,所以与其让它们一起重启,不如每次只重启一个,这样的话即使重启也能保证其他的 worker 进程能够继续处理请求。
用 cluster 模块能简单地实现这一想法。当 master 进程开始运行之后我们就不想重启它,我们需要想办法传递重启 worker 的指令给 master 进程。在 Linux 系统上这样做很容易因为我们能监听一个进程的信号像 SIGUSR2,当 kill 命令里面带有进程 id 和信号时这个监听事件将会触发:
// 在 Node 里面
process.on('SIGUSR2', () => { ... });
// 触发信号
$ kill -SIGUSR2 PID这样,master 进程不会被杀死,我们就能够在里面进行一系列操作了。SIGUSR2 信号适合这种情况,因为我们要执行用户指令。如果你想知道为什么不用 SIGUSR1,那是因为这个信号用在 Node 的调试器上,我们为了避免冲突所以不用它。
不幸的是,在 Windows 里面的进程不支持这个信号,我们要找其他方法让 master 进程做这件事。有几种代替方案。例如,我们可以用标准输入或者 socket 输入。或者我们可以监控 process.id 文件的删除事件。但是为了让这个教程更容易,我们还是假定服务器运行在 Linux 平台上。
在 Windows 上 Node 运行良好,但是我认为让作为产品的 Node 应用在 Linux 平台上运行会更安全。这和 Node 本身无关,只是因为在 Linux 上有更多稳定的生产工具。这只是我的个人见解,最好还是根据自己的情况选择平台。
顺带一提,在最近的 Windows 版本里,实际上你可以在里面使用 Linux 子系统。我自己测试过了,没有什么特别明显的缺点。如果你在 Windows 上开发 Node 应用,可以看看 [Bash on Windows](msdn.microsoft.com/en-us/comma…) 并尝试一下。
在我们的例子中,当 master 进程收到 SIGUSR2 信号,就意味着是时候重启 worker 了,但是我们想要每次只重启一个 worker。因此 master 进程应该等到当前的 worker 已经重启完后再重启下一个 worker。
我们需要用 cluster.workers 对象来得到当前所有 worker 的引用,然后我们简单地把它存进一个数组中:
const workers = Object.values(cluster.workers);然后,我们创建 restartWorker 函数来接受要重启的 worker 的 index。这样当下一个 worker 可以重启时,我们让函数调用当前 worker,直到最后重启整个序列里的 worker。这是需要调用的 restartWorker 函数(解释在后面):
const restartWorker = (workerIndex) => {
const worker = workers[workerIndex];
if (!worker) return;
worker.on('exit', () => {
if (!worker.exitedAfterDisconnect) return;
console.log(`Exited process ${worker.process.pid}`);
cluster.fork().on('listening', () => {
restartWorker(workerIndex + 1);
});
});
worker.disconnect();
};
restartWorker(0);在 restartWorker 函数里面,我们得到了要重启的 worker 的引用,然后我们会根据序列递归调用这个函数,我们需要一个结束递归的条件。当没有 worker 需要重启,我们就直接 return。基本上我们想让这个 worker 断开连接(使用 worker.disconnect),但是在重启下一个 worker 之前,我们需要 fork 一个新的 worker 来代替当前断开连接的 worker。
当目前要断开连接的 worker 还存在时,我们可以用 worker 本身的 exit 事件来 fork 一个新的 worker,但是我们要确保在平常的断开连接调用后 exit 动作就会被触发。我们可以用 exitedAfetrDisconnect flag,如果 flag 不为 true,那么是因为其他原因而导致的 exit,这种情况下我们什么都不做就直接 return。但是如果 flag 为 true,我们就继续执行下去,fork 一个新的 worker 来代替当前要断开连接的那个。
当新的 fork worker 进程准备好了,我们就要重启下一个。然而,记住 fork 的过程不是同步的,所以我们不能在调用完 fork 后就直接重启下个 worker。我们要在新的 fork worker 上监听 listening 事件,这个事件告诉我们这个 worker 已经连接并准备好了。当我们触发这个事件,我们就可以安全地重启下个在序列里 worker 了。
这就是我们为了实现瞬时重启要做的东西。要测试它,你要知道需要发送 SIGUSR2 信号的 master 进程的 id:
console.log(`Master PID: ${process.pid}`);开启 cluster,复制 master 进程的 id,然后用 kill -SIGUSR2 PID 命令重启 cluster。同样你可以在重启 cluster 时用 ab 命令来看看重启时的可用性。剧透一下,没有请求失败:
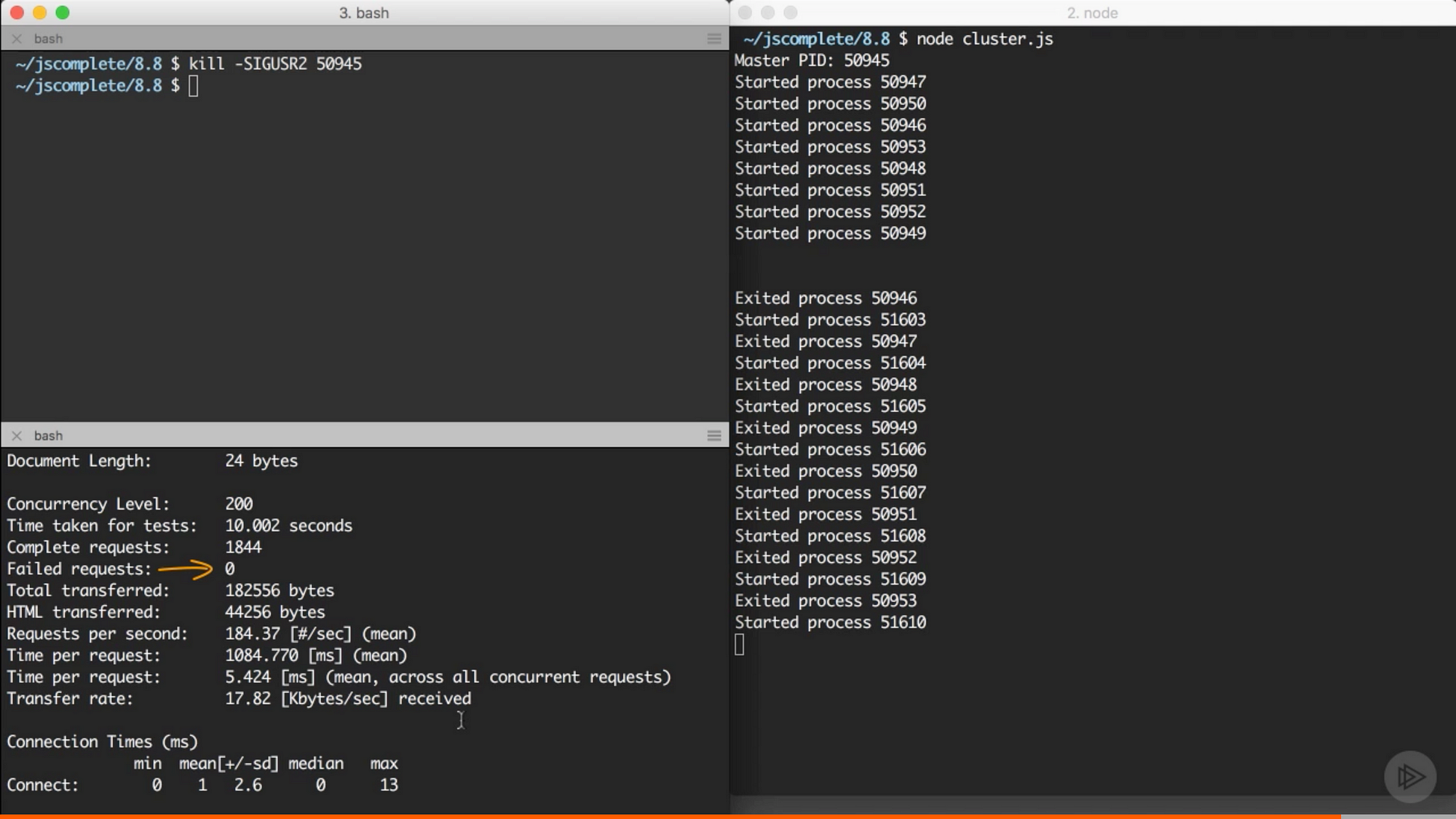
来自 Pluralsight 课程中的截图 — Node.js 进阶
像 PM2 这样的进程监控器,我个人把它用在生产环境上,它让我们实现上述工作变得异常简单,同时它还有许多功能来监控 Node.js 应用的健壮度。例如,用 PM2,想要在任意应用上启动 cluster,你只需要用 -i 参数:
pm2 start server.js -i max想要瞬时重启你只需要使用这个神奇的命令:
pm2 reload all然而,我觉得在使用这些命令之前先理解其背后的实现是有帮助的。
共享状态和粘性负载均衡
好东西总是需要付出代价。当我们对一个 Node 应用进行负载均衡,我们也失去了一些只能在单进程适用的功能。这个问题在其他语言上被称为线程安全,它和在线程之间共享数据有关。在我们的案例中,问题则在于如何在 worker 进程之间共享数据。
例如,设立了 cluster 后,我们就不能在内存上缓存东西了,因为每个 worker 有其独立的内存空间,如果我们在其中一个 worker 的内存里缓存东西,其他的 worker 就没办法拿到它。
如果我们需要在 cluster 里缓存东西,我们要从所有 worker 那里分离实体和读取/写入实体的 API。实体要存放在数据库服务器,或者如果你想用内存来缓存,你可以使用像 Redis 这样的服务器,或者创建一个专注于读取/写入 API 的 Node 进程供所有 worker 使用。
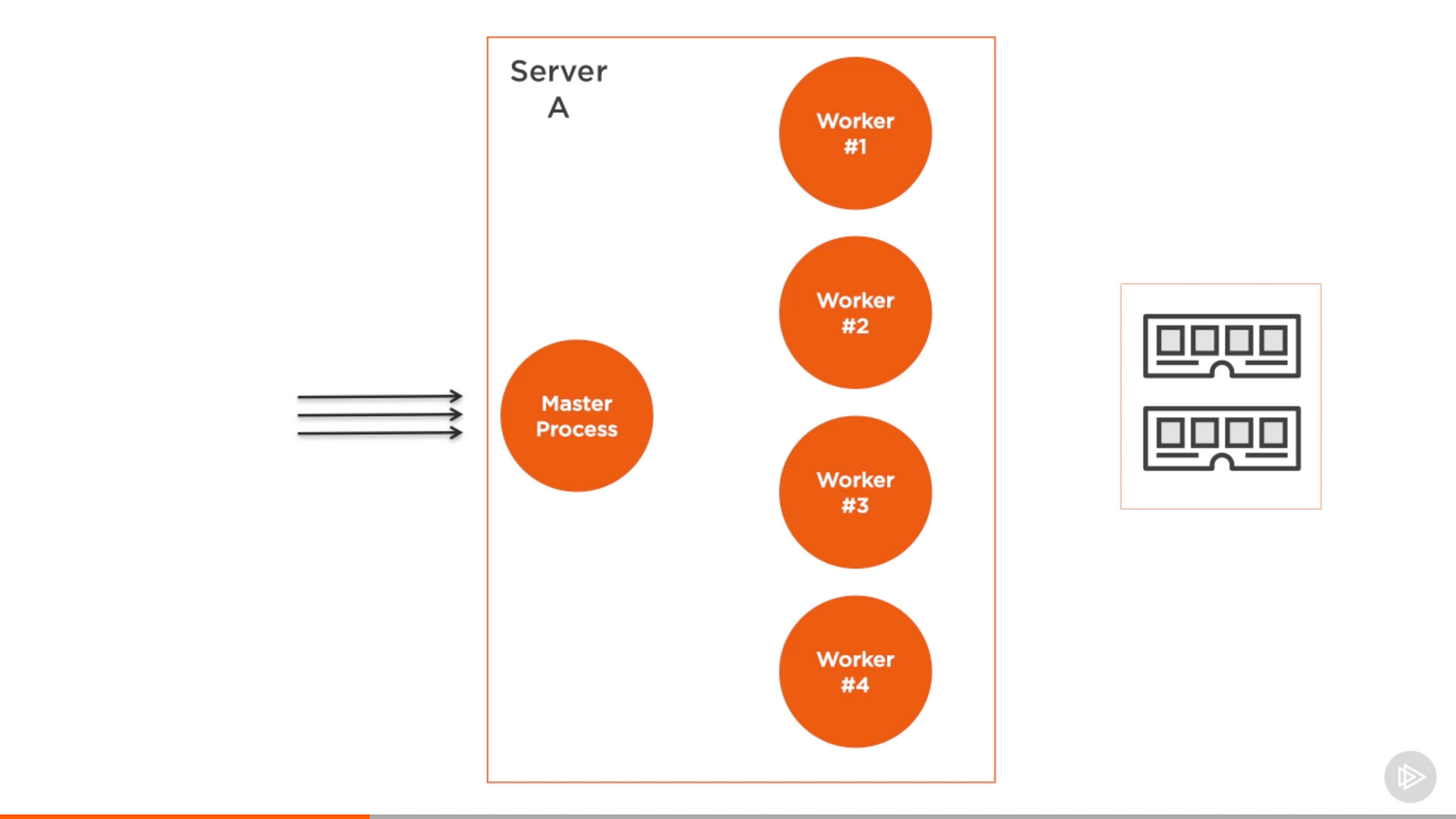
来自 Pluralsight 课程中的截图 — Node.js 进阶
这个做法有个好处,当你的应用为了缓存而分离了实体,实际上这是分解的一部分,能让你的应用更具可拓展性。即使你运行在一个单核服务器,你也应该这样做。
除了缓存外,当我们运行 cluster,总体来说状态之间的交流成为了一个问题。我们不能确保交流发生在同一个 worker 上,因此不能在任何一个 worker 上创建一个状态相关的交流通道。
一个最常见的例子是用户认证。
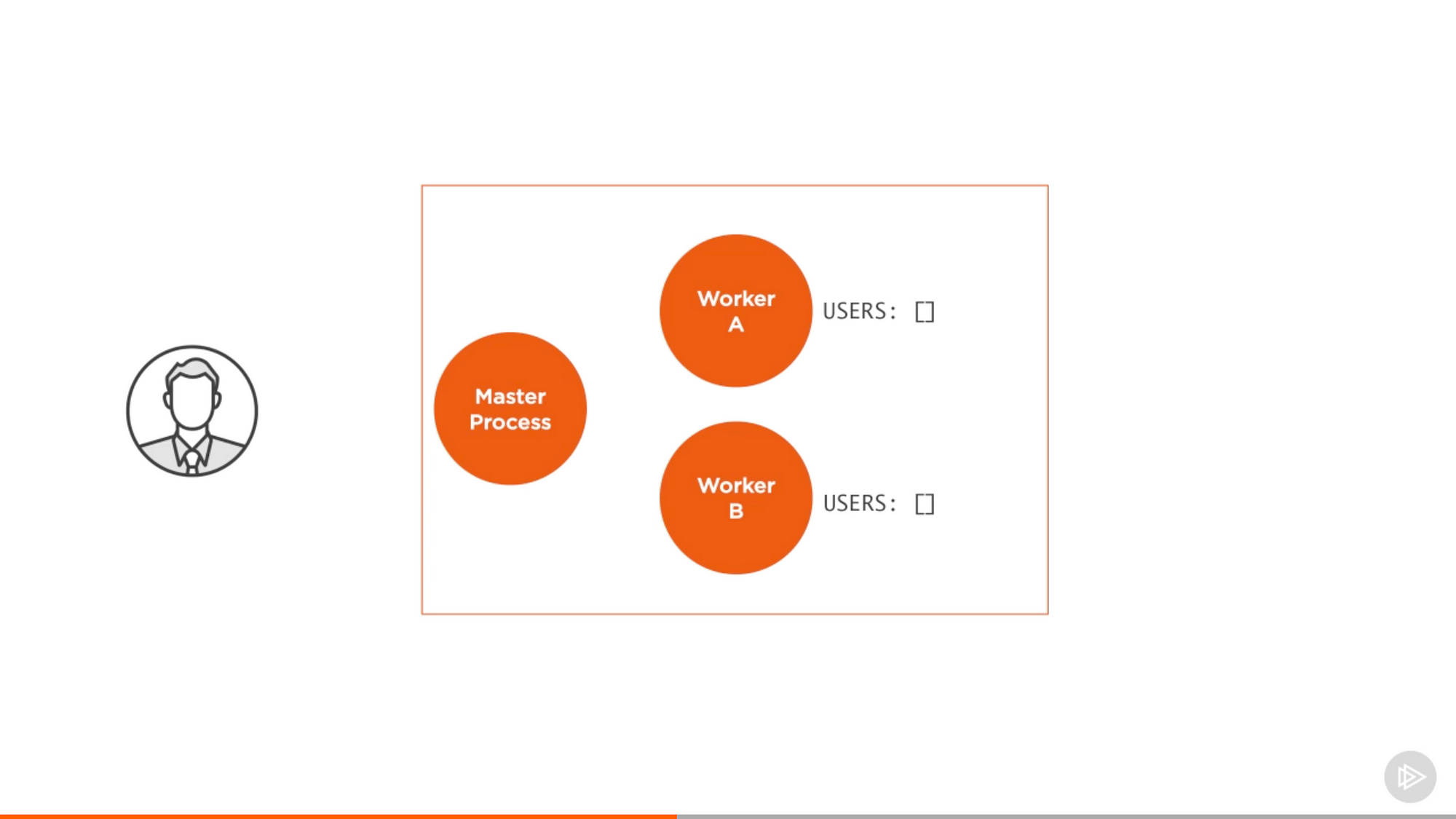
来自 Pluralsight 课程中的截图 — Node.js 进阶
用 cluster,验证的请求分配到 master 进程,而这个进程把请求分配给一个 worker,假定分配给 A。
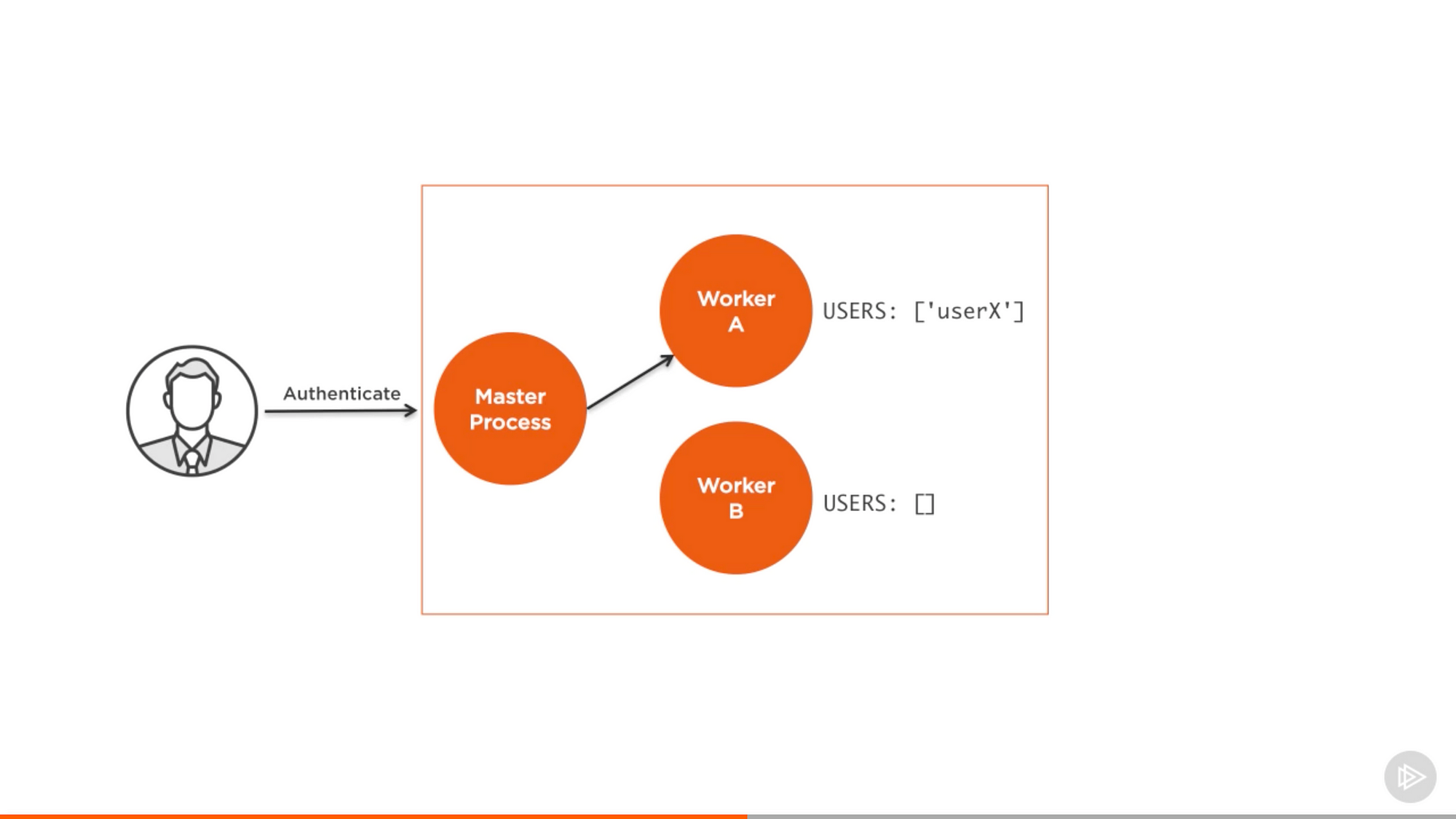
来自 Pluralsight 课程中的截图 — Node.js 进阶
现在 Worker A 认出了用户的状态。但是,当同样的用户进行另外一个请求,最终负载均衡器会把它分配给其他 worker,而这些 worker 还没有验证这个用户。在单独一个实例的内存上持有验证用户的引用并不管用。
有很多方法处理这个问题。通过在共享数据库或者 Redis node 上对会话信息进行排序,我们可以在 worker 之间共享状态。然而,实现这个策略需要改变一些代码,这不是最好的方法。
如果你不想修改代码就实现一个会话的共享存储仓库,有个入侵性低但效率不高的策略。你可以用粘性负载均衡。和让普通的负载均衡器实现上述策略相比,它更为简单。想法很简单,当 worker 的实例要验证用户,我们在负载均衡器上记录相关的关系。
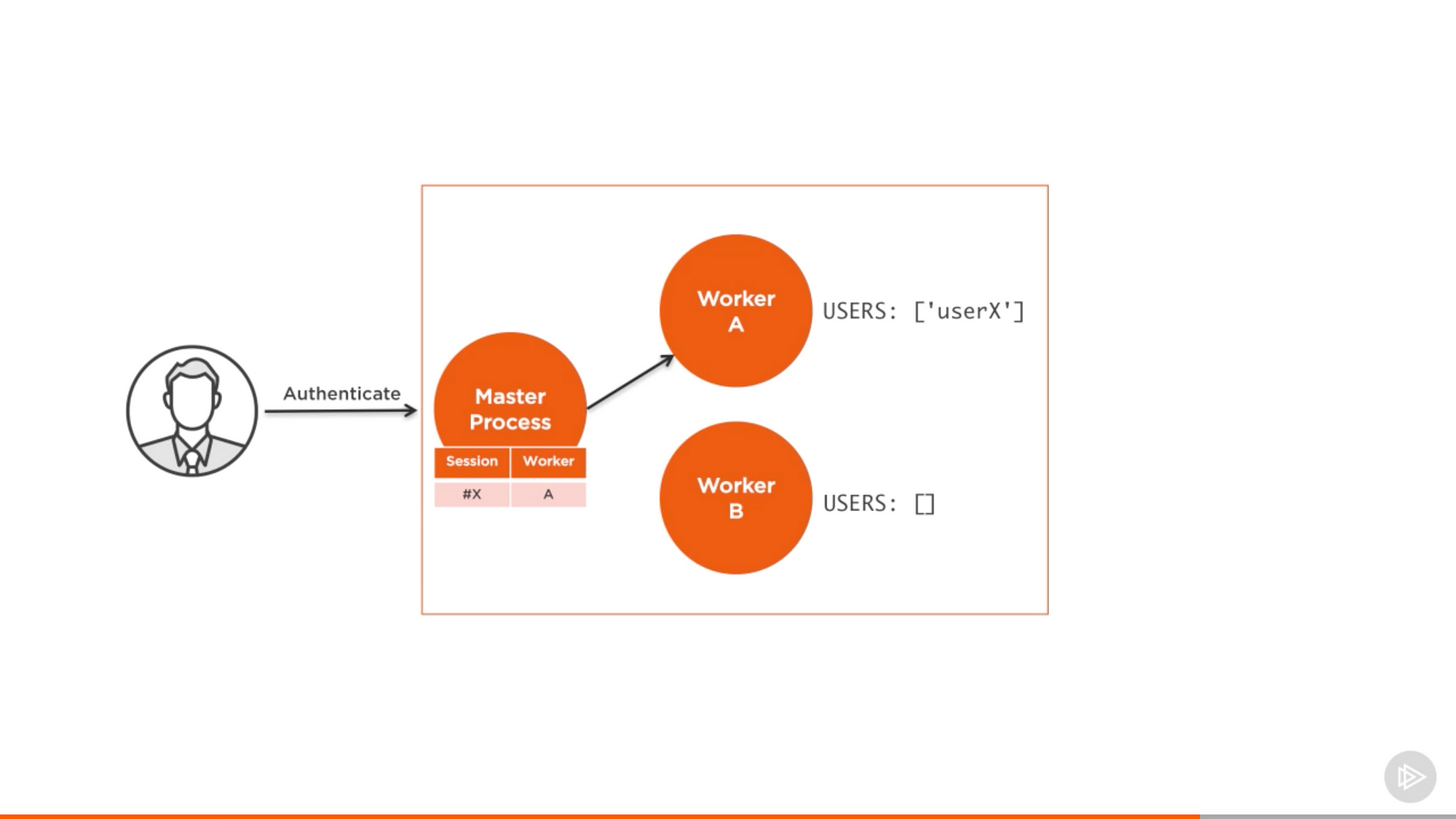
来自 Pluralsight 课程中的截图 — Node.js 进阶
然后,当同样的用户发送新的请求,我们就检查记录,发现服务器里已经有验证的会话,然后把这个会话发送给服务器,而不是执行普通的验证操作。用这个方法不需要改变服务器里的代码,但同时我们不会得到用负载均衡器来验证用户的好处,所以只有别无选择时才用粘性负载均衡。
实际上 cluster 模块并不支持粘性负载均衡,但是大多数负载均衡器可以默认设置为粘性负载均衡。
感谢阅读。如果你觉得这篇文章对你有帮助,请点击下面的 💚。关注我来得到更多有关 Node.js 和 JavaScript 的文章。
我为 Pluralsight 和 Lynda 创建了网络课程。最近我的课程是 Advanced React.js,Advanced Node.js 和 Learning Full-stack JavaScript。
同时我也为 JavaScript,Node.js,React.js,和 GraphQL 的水平在初级与进阶之间的人们创建了在线 training。如果你想要找一位导师,可以 发邮件给我。如对这篇文章或者其他我写的文章有任何疑问,请在 这个 slack 用户 上找到我并且在 #question 空间上提问。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、React、前端、后端、产品、设计 等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
