

这篇文章是David Mark Clements和Matteo Collina一起写的,并且由来自 V8 团队的Franziska Hinkelmann和Benedikt Meurer审查的。文章最先在 nearForm’s blog网站上发布。
V8 turbofan 的性能特征是如何影响我们的优化方式
自从 node.js 成立开始,就依赖于 V8 javascript 引擎提供代码的执行环境,我们使用我们所了解并热爱的编程语言。V8 javascript 引擎,是 Google 为 Chrome 浏览器编写的虚拟机。从一开始,V8 的主要目标就是让 javascript 快速的执行,至少比它的竞争者更快。对于高度动态化、弱类型的语言而言,这个目标并不容易实现。这篇文章讲述的是 V8 和 javascript 引擎性能演变之路。
V8 引擎核心部分允许使用 JIT(即时编译)编译器高速执行javascript,这是一个可以在运行时,优化代码的动态编译器。当 V8 第一次构建 JIT 编译器时,被命名为:CrankShaft。
自从上世纪90年代以来,在外界的人和 javascript 使用者眼里,javascript 执行的快或者慢都是不可预测的,很难彻底理解 javascript 执行慢的原因。
在最近几年,Matteo Collina和I聚焦于找到如何编写高性能 node.js 代码的方法,当然,这就意味着他们知道如何让 V8 快速和慢速执行我们的代码。
现在,因为 V8 团队已经写了新的 JIT 编译器:Turbofan.,因此是时候轮到我们去挑战我们对性能的所有假设。
从更常见的 V8 杀手(一段导致优化缓慢的代码,这个术语在 Turbofan 上下文中不再有意义)到不常见的Matteo,围绕着 Crankshaft 性能,我们将通过一系列的微型基准点结果观察 V8 各个版本性能差异。
当然,在优化 V8 逻辑路径之前,我们应该首先关注 API 的设计、算法、日期结构。这些微型基准点是 node 版本变化过程中 javascript 如何执行的指标。我们可以在已经应用常规的优化方式之后,使用这些指标去提高我们的常规的编码风格、改善程序的性能。
我们将使用 V8 5.1、5.8、5.9、6.0、6.1 版本观察这些微型指标的性能。
把这些版本放在如下的环境中: Node 6 使用V8 5.1 和 Crankshaft JIT 编译器,Node 8.0 到 8.2 使用 V8 5.8 、Crankshaft 和 Turbofan 混合的 JIT 编译器。
到目前为止,V8 5.9 还是 6.0 版本将在 Node 8.3 (或者可能是 Node 8.4)版本中,6.1 版本是 V8 的最新版本,集成在实验性的 node-v8 github.com/nodejs/node… 仓库中。换句话说,V8 6.1 版本将集成在未来的 Node 版本中。
让我们一起看一下我们的微型参照点,另一方面,我们将会谈论这些参照点对未来的意义。
try/catch 问题
最着名的去优化模式之一是使用“try/catch”代码块。
在这个参照点中,我们比较四种场景的案例:
- 包含 try/catch 的函数
- 不包含 try/catch 的函数
- 在 try/catch 内部调用函数
- 简单的直接调用函数
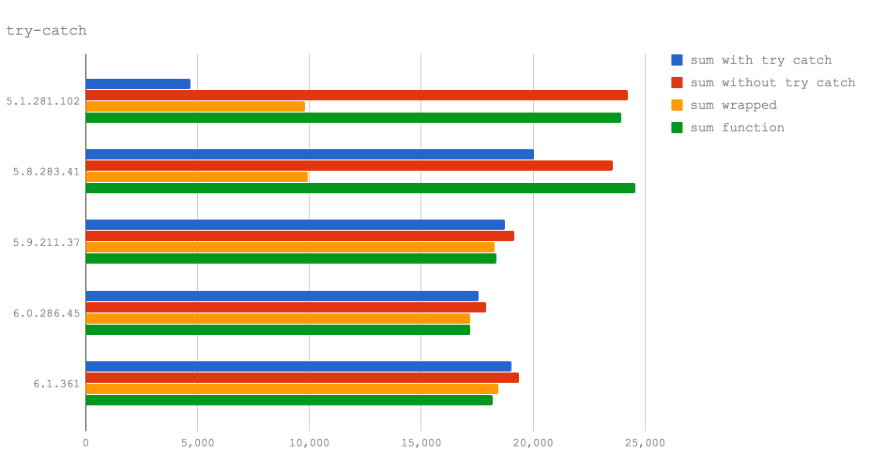
我们可以看到,在 Node 6 (V8 5.1)中,“try/catch”产生的性能问题是真实存在的,但是在 Node 8.0-8.2 (V8 5.8)中,对性能的影响明显降低了很多。
还要注意,在 try 代码块内部调用函数比在 try 代码块外部执行速度慢很多,在 Node 6 (V8 5.1) 和 Node 8.0-8.2 (V8 5.8)中也是如此。
然而对于Node 8.3+,在“try”块内调用函数的性能问题可以忽略不计。
不过,不要太掉以轻心。在研究一些演习研讨会材料时,Matteo和我发现了一个性能错误,其中一个相当具体的情况组合可以导致Turbofan的无限优化/重新优化周期(这将被视为一种“杀手” - 一种破坏性能的模式)。
移除对象上的属性
多年以来,delete对于任何希望编写高性能JavaScript的人来说都是受限制的(至少我们正在尝试为热门程序编写最佳代码)。
“delete”的问题归结为V8处理JavaScript对象的动态特性和(也是潜在的动态)原型链,使得属性在实现级别上查找更加复杂。
V8引擎高性能创建对象属性技术是根据对象的“形状”在C ++层中创建一个类。形状本质上是键值属性(包括原型链键和值)。这些被称为“隐藏类”。然而,这是在运行时发生在对象上的优化,如果对象的形状有不确定性,V8 有用于属性检索的另一种模式:散列表查找。散列表查找明显慢很多。以前,当我们从对象中删除一个键时,后续的属性访问将是一个哈希表查找。这就是为什么我们避免delete,而是将属性设置为undefined,这两种做法到目前为止,值都是相同的,但是在检查属性是否存在时前者可能会有问题;由于JSON.stringify在其输出中不包含“undefined”值(“undefined”在JSON规范中不是有效值),因此预序列化编译通常足够好。
现在,我们来看看新的Turbofan实现是否解决了delete的问题。
在这个微基准测试中,我们比较了两种情况:
- 在对象的属性设置为“undefined”之后对其进行序列化
- 使用
delete移除对象的属性后对其进行序列化
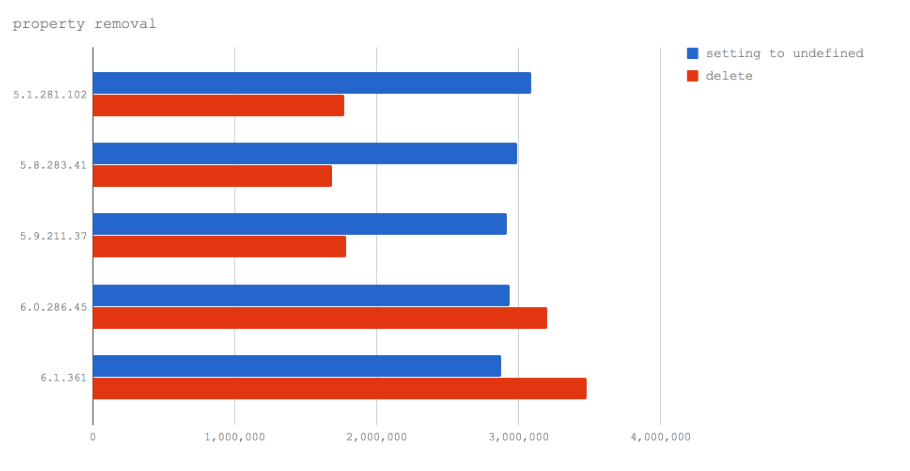
在V8 6.1(尚未在任何 Node 发布版中使用)中,操作对象上已删除属性特别快,甚至比设置为“undefined”还快。这是一个很好的消息,因为现在我们可以使用 delete ,并且用 delete 更快。
泄漏和整理`ARGUMENTS'
常见的JavaScript函数(箭头函数是个例外,箭头函数内部没有 arguments 对象)可以使用类数组的隐式“arguments”对象。
为了使用数组方法或大多数数组行为,“arguments”对象的索引属性已被复制到一个数组中。在过去,javascript 程序员已经倾向于认为更少的代码执行速度更快。虽然这个经验法则为浏览器端代码带来了有效负载大小的好处,但同样的规则可能导致服务器端的代码大小远不如执行速度重要的痛苦。所以将arguments对象转换成数组的方法变得非常受欢迎:Array.prototype.slice.call(arguments),调用数组的slice函数传递arguments对象作为该函数的this上下文,slice函数看到一个像数组一样的对象,并相应地进行操作。也就是说,它将整个类数组的
arguments 对象作为一个数组。
但是,当一个函数隐式的arguments对象从函数上下文中暴露出来(例如,当它从函数返回值取回或者传递给另一个函数,就像在Array.prototype.slice.call(arguments)的情况下一样)导致性能下降。现在是挑战这个假设的时候了。
下一个微基准测量了我们四个V8版本中两个相互关联的主题:泄漏“参数”的成本以及将参数复制到数组中的成本(随后从函数范围中暴露来代替“arguments”对象)。
详情如下所述:
- 将
arguments对象暴露给另一个函数, 没有数组转换 - 使用
Array.prototype.slice技巧创建arguments对象的副本 - 使用for循环并复制每个属性
- 使用 ECMAScript 2015 扩展运算符将一个输入数组分配给引用
代码访问地址: github.com/davidmarkcl…
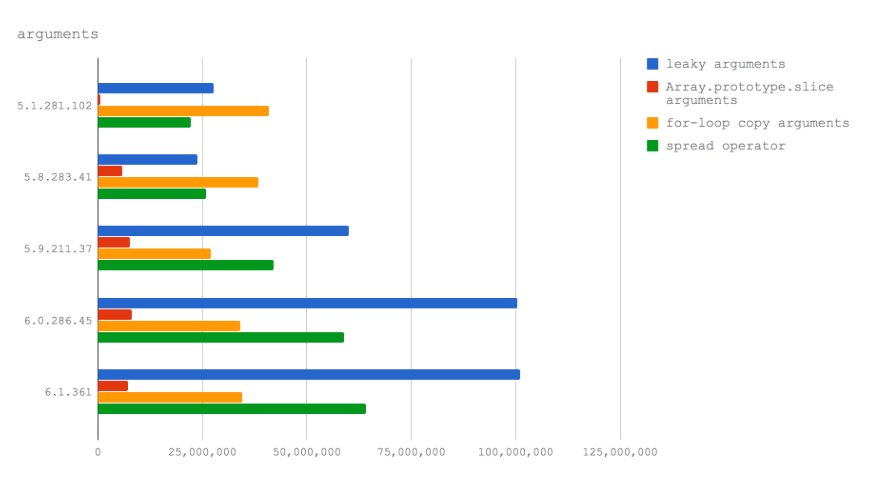
我们来看看相同的数据,以线图形式强调性能特征的变化:
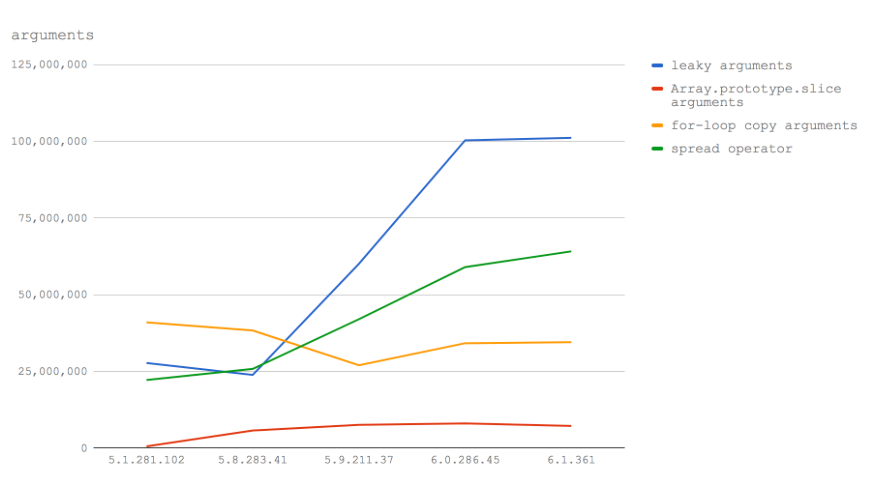
综上所述:如果我们想用数组作为处理函数的入参(在我的经验中看起来相当普遍),那么在Node 8.3或者更高的版本中我们应该使用扩展运算符。在Node 8.2或者更低的版本中,我们应该使用一个for循环将key从arguments复制到一个新的(预先分配的)数组中(详见基准代码)。
此外,在Node 8.3+中,我们不会因为将arguments参数暴露给其他函数而遇到性能问题,因此在不需要完整数组的情况下可能会有进一步的性能优势,并且可以使用类似数组的结构。
部分应用(CURRYING)和BINDING
部分应用(或currying)是指我们可以捕获嵌套闭包内的状态的方式。
例如:
function add (a, b) {
return a + b
}
const add10 = function (n) {
return add(10, n)
}
console.log(add10(20))
这里 add 函数的参数 a 在 add10 函数中,被赋值为 10.
自EcmaScript 5以来,使用“bind”方法提供了一种更简单的部分应用的书写方式:
function add (a, b) {
return a + b
}
const add10 = add.bind(null, 10)
console.log(add10(20))
但是,我们通常不会使用bind,因为它明显比使用闭包更慢。
这个基准测量了我们的目标V8版本的bind和闭包之间的区别,直接调用函数。
下面是我们的四个案例:
- 一个函数用部分应用的方式调用另一个函数
- 一个箭头函数用部分应用的方式调用另一个函数
- 用bind创建一个函数用部分应用的方式调用另一个函数
- 直接调用函数
代码访问地址: github.com/davidmarkcl…
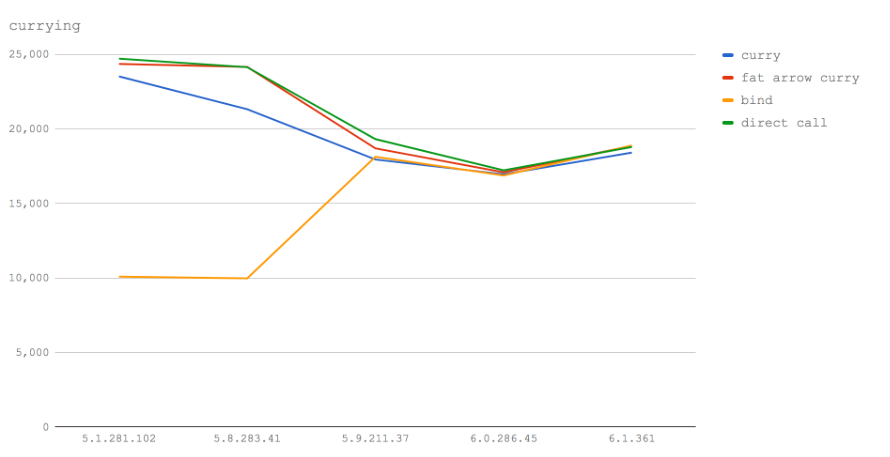
该基准测试结果的折线图清楚地说明了在新的V8版本中出现聚合。 有趣的是,使用箭头函数的部分应用比使用正常功能(至少在我们的微基准情况下)要快得多。 事实上,它几乎和直接调用的性能差不多。 在V8 5.1(Node 6)和5.8(Node 8.0-8.2)中,bind比较非常慢,而且看起来很明显,使用箭头部分应用是最快的选择。 然而,“bind”速度从V8版本5.9(Node 8.3+)开始提升,在V8 6.1版本(未来的 Node)中速度最快。
在所有版本中,使用箭头函数是最接近直接调用的。 在后面的新版本中使用箭头函数的代码将和使用“bind”一样接近,而且目前比使用正常的函数更快。 然而,作为一个警告,我们可能需要使用不同大小的数据结构来测试更多类型的部分应用,以获得更全面的图表。
函数字符数
一个函数的大小,与它的函数名,空格,甚至是注释有关,无论 V8 是否可以函数把函数处理为一行。 是的:向您的函数添加注释可能会导致性能下降到10%的速度范围内。 这中现象在Turbofan中会有改变吗? 我们来看看吧。
在这个基准点中我们考虑三个场景。
- 调用一个小函数
- 内联执行一个小函数,用注释填充
- 执行一个用注释填充的大函数
代码访问地址: github.com/davidmarkcl…
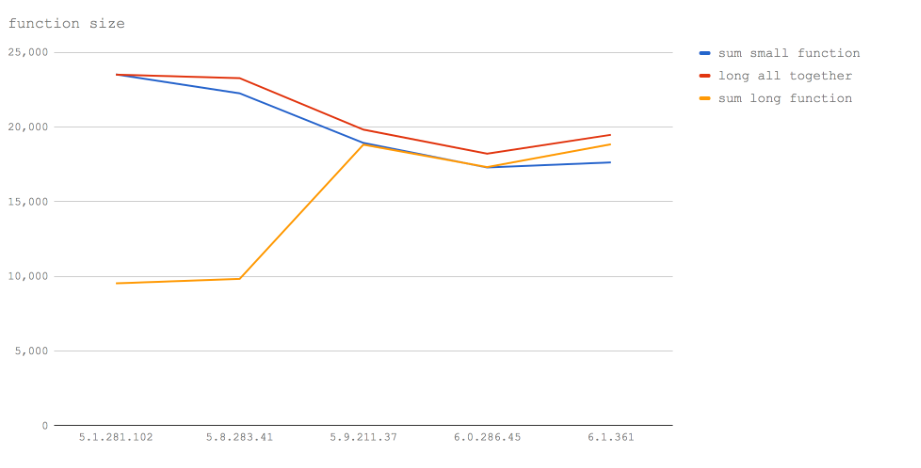
在V8 5.1(Node6)中,小函数和内联函数的执行速度相同的。这完全说明了内联的函数是如何工作的。当我们调用这个小函数时,就像V8把小函数的内容写入到它所调用的地方。所以当我们实际写一个函数的内容(即使使用额外的注释填充)时,我们手动把函数变成内联函数,性能是相同的。再次,我们可以在V8 5.1(Node6)中看到,调用一个填充有超过一定大小的注释的函数,导致执行速度慢。
在Node 8.0-8.2(V8 5.8)中,情况几乎相同,除了调用小功能的成本明显增加;这可能是由于Crankshaft和Turbofa同时作用的缘故,而一个功能可能在Crankshaft中,另一个功能可能在Turbofan中导致内联能力的分离(即一系列的行内函数的集群之间必须有跳跃)。
在5.9及更高版本(Node 8.3+)中,任何通过不相关字符(如空白或注释)添加的大小与功能性能无关。这是因为Turbofan使用函数AST抽象语法树来确定函数大小,而不是使用Crankshaft中的字符计数。不是检查字节数的功能,它考虑了函数的实际指令,使得从V8 5.9(Node 8.3+)**空格,变量名字符计数,函数签名和注释不再是一个函数是否内联的因素。
值得注意的是,我们再次看到功能的整体性能下降。
这里的总结还应该是编写小函数。目前我们还是要避免函数内部的过多注释(甚至空白)。另外如果你想要绝对最快的速度,手动内联(删除调用)一直是最快的方法。当然,这必须与在一定大小(实际可执行代码)一个函数不会被内联之后的事实相平衡,所以将其他函数的代码复制到函数中可能会导致性能问题。换句话说,手动内联是可选的优化方案;在大多数情况下最好是让编译器处理内联代码。
32位与64位整数
我们都知道,JavaScript只有一个数字类型:Number。 (也许关于BigInt提案的一句话应该包括在这里?)
然而,V8是用 C++ 实现的,所以必须在底层对数字类型的JavaScript值进行选择。
在整数的情况下(也就是当我们在JS中指定一个没有小数时),V8假设所有数字都是32位 - 直到它们不是。这似乎是一个公平的选择,因为在许多情况下,一个数字在0-65535范围内。如果JavaScript(全)数字超过65535,则JIT编译器必须将数字的底层类型动态地更改为64位 - 这可能也会对其他优化产生潜在的影响。
这个基准看下面三种情况:
- 一个函数仅处理32位范围内的数字
- 一个函数处理32位和64位之间的数字
- 一个函数只处理超过32位容量的数字
代码访问地址: github.com/davidmarkcl…
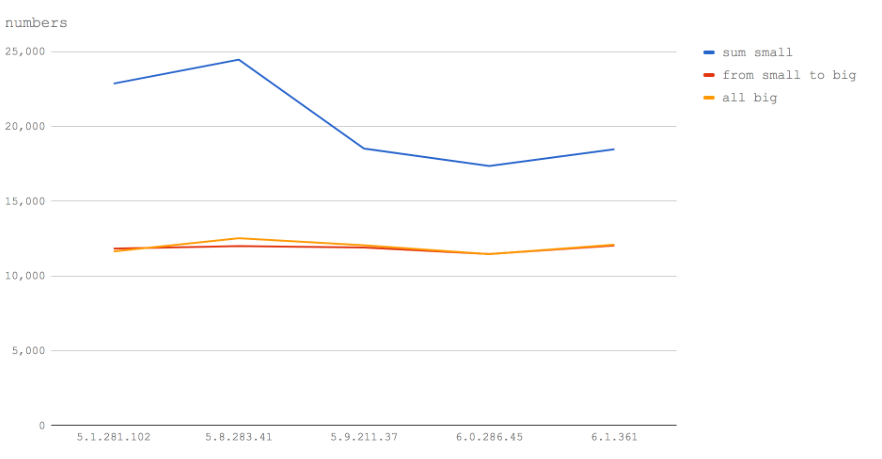
从图中可以看出,无论是Node 6(V8 5.1)还是Node 8(V8 5.8),甚至节点的某个未来版本,这一观察是否成立。大于65535的数字(整数)将使函数在速度的一半到三分之二之间运行。所以,如果你有长的数字ID - 将它们放在字符串中。
值得注意的是,32位范围内的数字在Node 6(V8 5.1)和Node 8.1和8.2(V8 5.8)之间的速度增加也非常明显,但在Node 8.3+(V8 5.9+)中明显变慢。由于大数字根本没有影响速度,所以很有可能这是真正的(32位)数字处理速度减慢的原因,而不是与函数调用或循环速度有关(在基准代码中使用的) 。
遍历Object
取对象所有的value(或者property),用这些数据执行一些操作是一个常见的任务,有很多方法可以解决这个问题。我们来看看哪个版本的V8(和Node)是最快的。
该基准测量了所有V8版本的四种情况:
- 使用
for-in循环和hasOwnProperty检查来获取一个对象所有值 - 使用
Object.keys并使用Arrayreduce方法迭代key,在提供给reduce的iterator函数内访问对象的属性值 - 使用
Object.keys并使用Arrayreduce方法迭代key,在提供给reduce的iterator箭头函数内访问对象的属性值 - 用
for循环Object.keys返回的数组,在循环内部访问对象的属性值
我们还对V8 5.8,5.9,6.0和6.1额外增加了三个案例
- 使用
Object.values并使用数组的reduce方法迭代值 - 使用
Object.values并使用数组的reduce方法迭代值,传递给 reduce 的函数是箭头函数 - 用
for循环Object.values返回的数组
We don’t bench these cases in V8 5.1 (Node 6) because it doesn’t support the native EcmaScript 2015 Object.values method.
我们不会在V8 5.1(node 6)中对这些情况进行测试,因为它不支持原生的 EcmaScript 2015 Object.values方法。
代码访问地址: github.com/davidmarkcl…
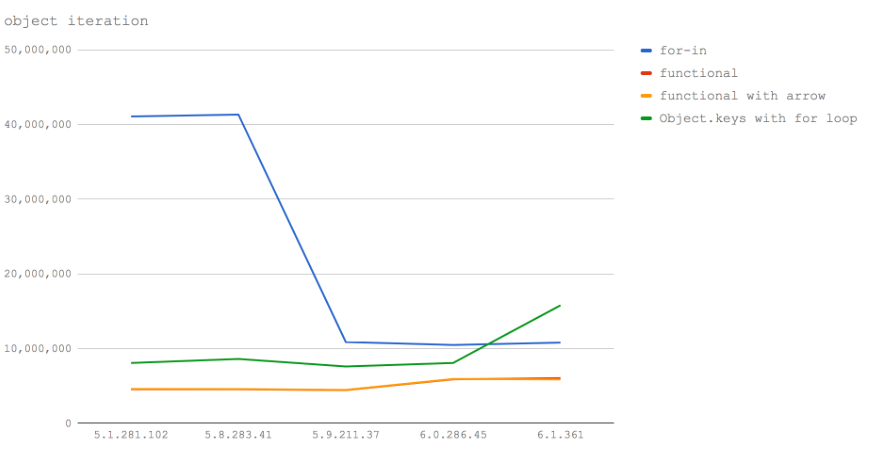
在Node 6(V8 5.1)和Node 8.0-8.2(V8 5.8)中使用for-in是到目前为止循环一个对象的所有key最快的方法,然后在循环内访问对象的值。每秒大约有4000万次操作,比最接近的方法要快5倍,Object.keys在800万次左右。
在V8 6.0(Node 8.3)中,for-in以前的版本减少了四分之一的速度,但仍比其他任何方法都快。
在V8 6.1(Node 未来的发布版)中,Object.keys的速度会飞进,会变得比使用for-in更快,但是在V8 5.1中没有还比不上V8 5.1和5.8(Node 6,Node 8.0-8.2)中 for-in的速度。
Turbofan背后的驱动原则似乎是针对直观的编码行为进行优化。也就是说,针对开发人员最符合人体工程学的情况进行优化。
使用Object.values直接获取值比使用Object.keys并访问对象中的值更慢。除此之外,处理循环比函数式编程还要快。因此,在迭代对象时可能还需要做更多的工作。
另外,对于那些为了性能而使用for-in的人,当我们速度急剧下降,却没有替代的方法时,这将是一个痛苦的时刻。
创建对象
我们总是在不停的创建对象,因此这是很适合测量的一个点。
我们将看下面三个案例:
- 使用对象字面量创建对象
- 使用 ES2015 class 创建对象
- 使用构造器函数创建对象
代码仓库地址: github.com/davidmarkcl…
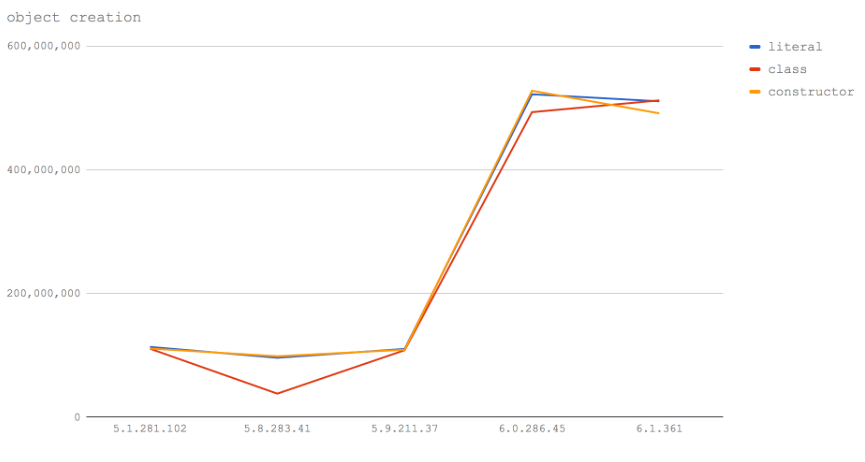
在Node 6(V8 5.1)中,所有方法速度都差不多。
在Node 8.0-8.2(V8 5.8)中,用EcmaScript 2015 class 创建实例的速度不到使用构造函数的对象字面值的一半。这里应当特别注意。
在 V8 5.9 中依旧如此。
然后在V8 6.0(可能在 Node 8.3 版本,或者在 Node 8.4 版本)和6.1(目前不在任何Node发布版)对象创建速度不可思议地超过5亿 op/s!这是令人难以置信的。

我们可以看到由构造函数创建的对象稍慢一些。所以我们对未来友好的执行代码的最好的打算总是喜欢对象字面量。这适合我们,因为我们建议从函数返回对象文字(而不是使用类或构造函数)作为一般的最佳编码实践。
POLYMORPHIC与MONOMORPHIC函数
当我们总是将相同类型的参数输入到一个函数中(比如我们总是传递一个字符串)时,我们以单态方式使用该函数。一些函数被写为多种类型的参数 - 这意味着相同的参数可以被处理为不同的隐藏类 - 所以也许它可以处理一个字符串,一个数组或一个具有特定隐藏类的对象,并相应地处理它。这在某些情况下可以使接口良好,但对性能有负面影响。
让我们来看看多类型和单类型的案例在我们的基准中是什么样的。
我们来看五种情况:
- 参数是对象字面量和字符串的函数
- 参数是构造器实例和字符串的函数
- 参数只是字符串的函数
- 参数只是对象字面量的函数
- 参数只是构造器实例的函数
代码仓库地址: github.com/davidmarkcl…
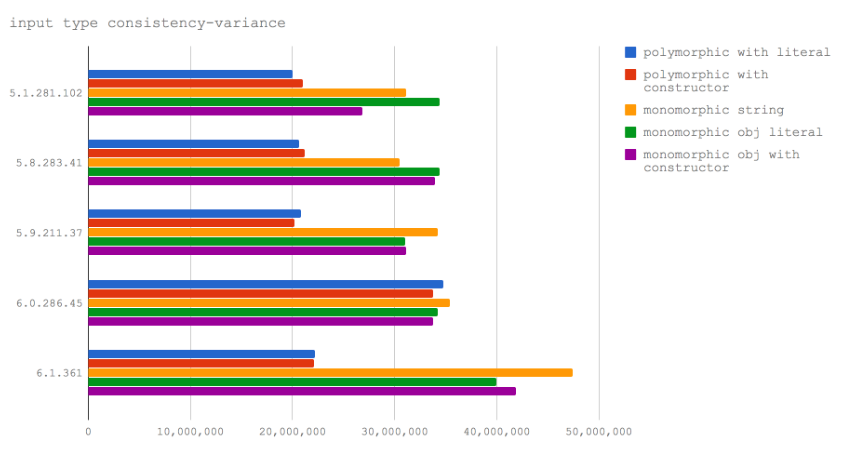
在我们的图中显示的数据最终证明,所有V8版本的单态函数都超过了多态函数。
V8 6.1(未来的 node 版本)中单态和多态函数之间存在更大的性能差距,这进一步证明这个观点。然而,值得注意的是,这基于使用 nightly-build V8版本的node-v8分支 - 它可能不会在V 8 6.1中的具体实现。
如果我们正在编写需要优化的代码,一个函数将被多次调用,那么我们应该避免使用多态。另一方面,如果只调用一次或两次,则用实例化/设置的函数,那么多态API的性能是可以接受的。
debugger 关键字
最后,让我们来谈谈 debugger 关键字
确保从代码中删除debugger语句。代码中的 debugger 语句会降低性能。
我们来看两个案例:
- 函数内部有
debugger的函数 - 函数内部没有
debugger的函数
代码仓库地址: github.com/davidmarkcl…
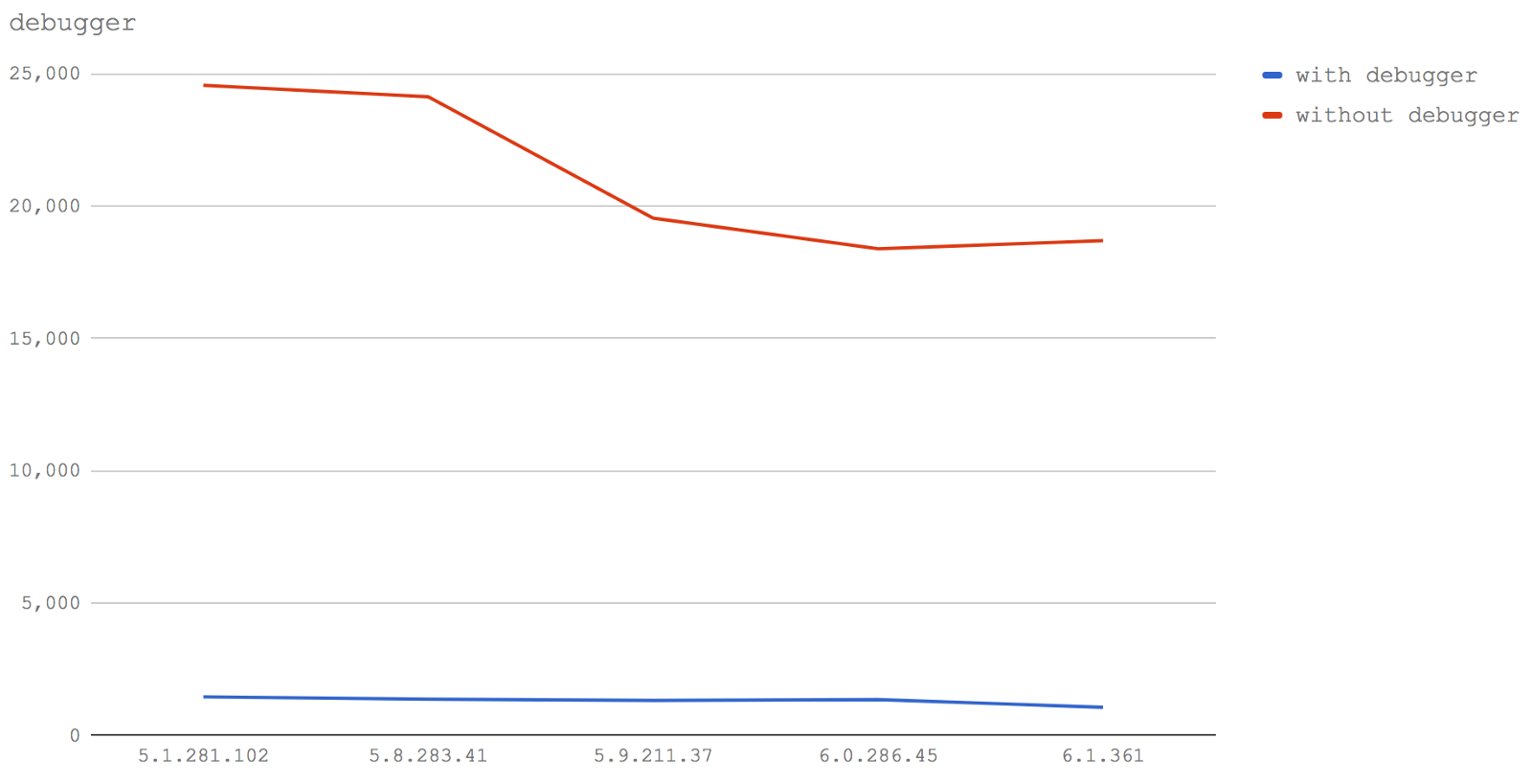
在所有测试的 V8 版本中,debugger关键字的存在,对性能的影响是非常可怕的。
没有 debugger 的行明显地下降了连续的V8版本,我们将在摘要.
一个真实的世界基准:LOGGER比较
除了我们的微基准,我们还可以使用 Node.js 最流行的日志记录器 Matteo 来观察我们 V8 版本的整体效果。
代码地址:Pino。
以下条形图表示在Node.js 5.9(Crankshaft)中最流行的日志记录器的性能:
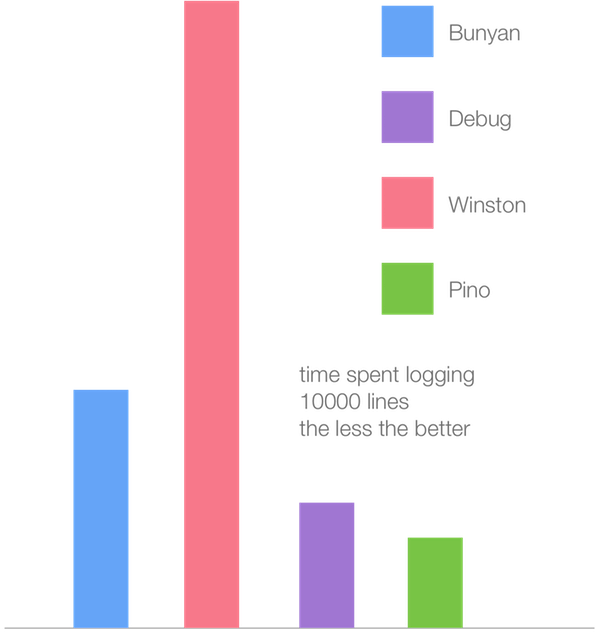
以下是使用V8 6.1(Turbofan)的相同基准:
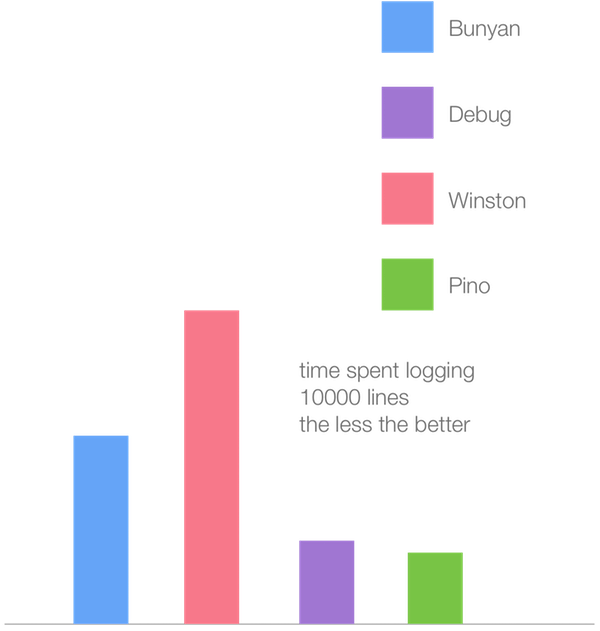
虽然所有的记录仪基准测试速度提高了大约2倍,但Winston logger从新的Turbofan JIT编译器中获得了最大的收益。这似乎表明了我们在微型基准测试中的各种方法中看到的速度趋同:Crankshaft中较慢的方法在Turbofan中显着更快,而Crankshaft中的快速方法在Turbofan中显着更慢。速度最慢的Winston,可能使用Crankshaft速度较慢的方法,但在Turbofan中的速度更快,而Pino则被优化为使用最快的Crankshaft方式。虽然在Pino中观察到速度增加,但程度要小得多。
总结
一些基准测试显示,在V8 5.1和V8 5.8和5.9中缓慢的案例,在V8 6.0和V8 6.1 完全启用 Turbofan时,变得更快,更快的案例,会变得更慢,经常出现慢案例变快的情况。
其中大部分是由于在Turbofan(V8 6.0及更高版本)中进行函数调用的成本。 Turbofan背后的想法是优化常见案例并消除常用的“V8杀手”。这让(Chrome)浏览器和服务器(Node)应用程序的性能更好。这个权衡似乎是(至少是最初的)最有效的案例的速度下降。我们的记录仪基准比较表明,Turbofan特性的全面提高了性能,甚至是跨平台的代码对比(例如Winston vs Pino)。
If you’ve had an eye on JavaScript performance for a while, and adapted coding behaviors to the quirks of the underlying engine it’s nearly time to unlearn some techniques. If you’ve focused on best practices, writing generally good JavaScript then well done, thanks to the V8 team’s tireless efforts, a performance reward is coming.
如果您有一段时间一直关注JavaScript性能,并将编码行为适应于底层引擎的怪癖,那么是时候忘记一些技巧。如果你专注于最佳实践,通常写好的代码是很好的,感谢V8团队的不懈努力,性能的提升即将到来。
所有的源代码和本文的另一个副本请访问github.com/davidmarkcl…。 本文的原始数据请访问: docs.google.com/spreadsheet…
