

本文来自作者:鸣宇淳 在 GitChat 上的精彩分享,由于篇幅长,故分为上下两篇
前言
Hadoop 在大数据技术体系中的地位至关重要,Hadoop 是大数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在大数据技术道路上走多远。
这是一篇入门文章,Hadoop 的学习方法很多,网上也有很多学习路线图。本文的思路是:以安装部署 Apache Hadoop2.x 版本为主线,来介绍 Hadoop2.x 的架构组成、各模块协同工作原理、技术细节。安装不是目的,通过安装认识Hadoop才是目的。
本文分为五个部分、十三节、四十九步。
第一部分:Linux环境安装
Hadoop是运行在Linux,虽然借助工具也可以运行在Windows上,但是建议还是运行在Linux系统上,第一部分介绍Linux环境的安装、配置、Java JDK安装等。
第二部分:Hadoop本地模式安装
Hadoop 本地模式只是用于本地开发调试,或者快速安装体验 Hadoop,这部分做简单的介绍。
第三部分:Hadoop伪分布式模式安装
学习 Hadoop 一般是在伪分布式模式下进行。这种模式是在一台机器上各个进程上运行 Hadoop 的各个模块,伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是只是运行在一个操作系统上的,并不是真正的分布式。
第四部分:完全分布式安装
完全分布式模式才是生产环境采用的模式,Hadoop 运行在服务器集群上,生产环境一般都会做HA,以实现高可用。
第五部分:Hadoop HA安装
HA是指高可用,为了解决Hadoop单点故障问题,生产环境一般都做HA部署。这部分介绍了如何配置Hadoop2.x的高可用,并简单介绍了HA的工作原理。
安装过程中,会穿插简单介绍涉及到的知识。希望能对大家有所帮助。
第一部分:Linux环境安装
第一步、配置 Vmware NAT 网络
一、Vmware 网络模式介绍
参考:http://blog.csdn.net/collection4u/article/details/14127671
二、NAT模式配置
NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。
我们部署Hadoop集群,这里选择NAT模式,各个虚拟机通过NAT使用宿主机的IP来访问外网。
我们的要求是集群中的各个虚拟机有固定的IP、可以访问外网,所以进行如下设置:
1. Vmware 安装后,默认的 NAT 设置如下:
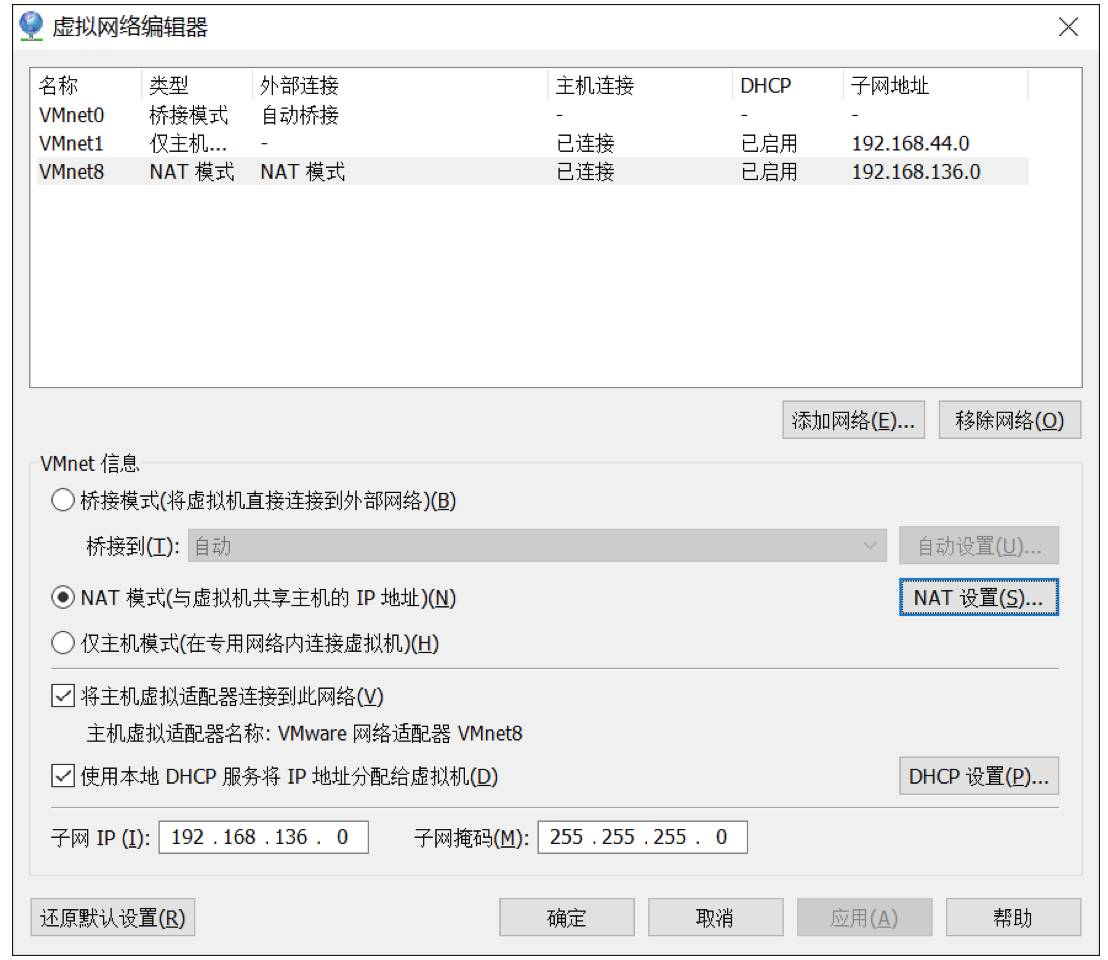
2. 默认的设置是启动DHCP服务的,NAT会自动给虚拟机分配IP,但是我们需要将各个机器的IP固定下来,所以要取消这个默认设置。
3. 为机器设置一个子网网段,默认是192.168.136网段,我们这里设置为100网段,将来各个虚拟机Ip就为 192.168.100.*。
4. 点击NAT设置按钮,打开对话框,可以修改网关地址和DNS地址。这里我们为NAT指定DNS地址。
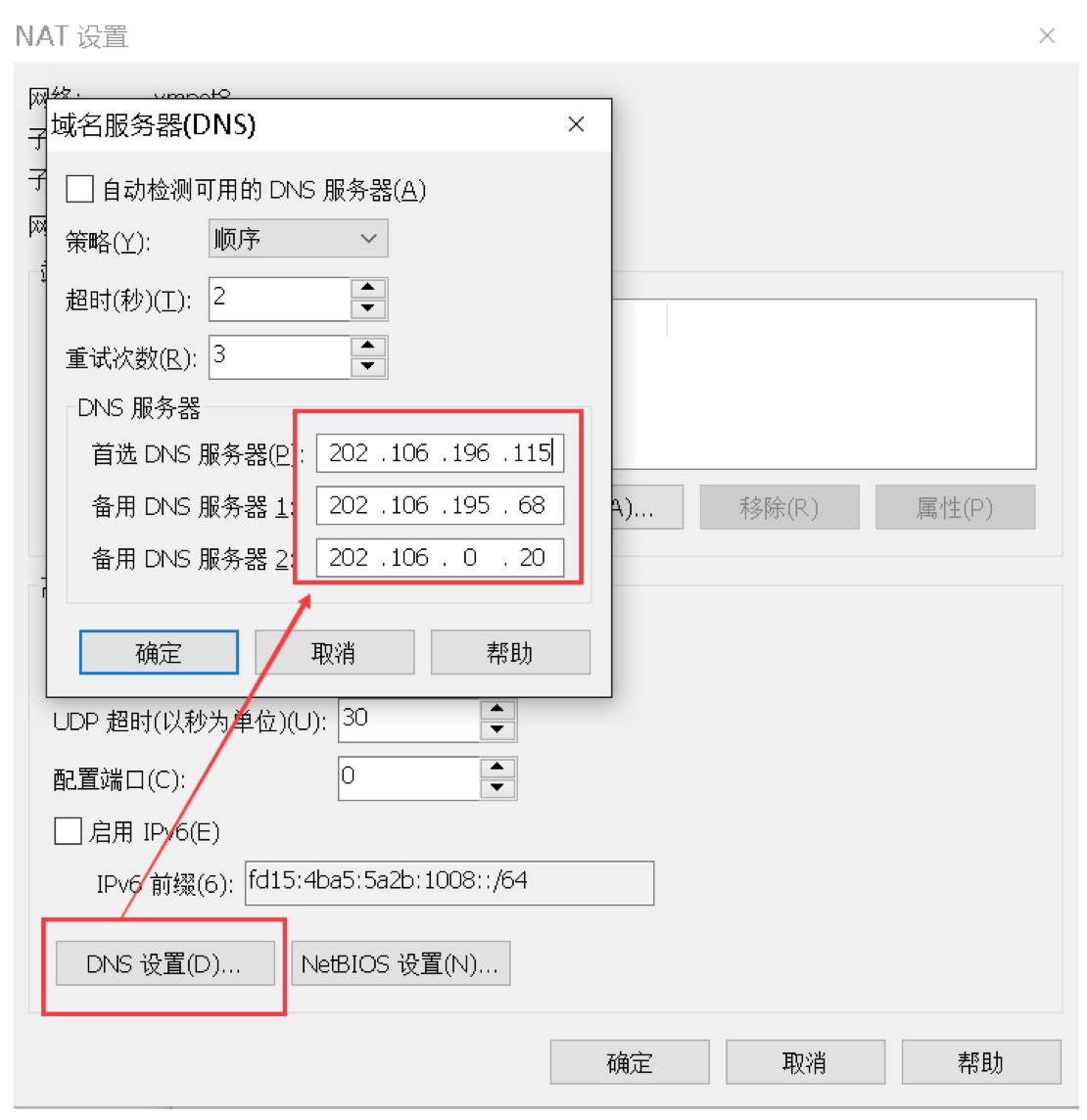
5. 网关地址为当前网段里的.2地址,好像是固定的,我们不做修改,先记住网关地址就好了,后面会用到。
第二步、安装Linux操作系统
三、Vmware 上安装 Linux系统
1. 文件菜单选择新建虚拟机
2. 选择经典类型安装,下一步。
3. 选择稍后安装操作系统,下一步。
4. 选择 Linux 系统,版本选择 CentOS 64 位。
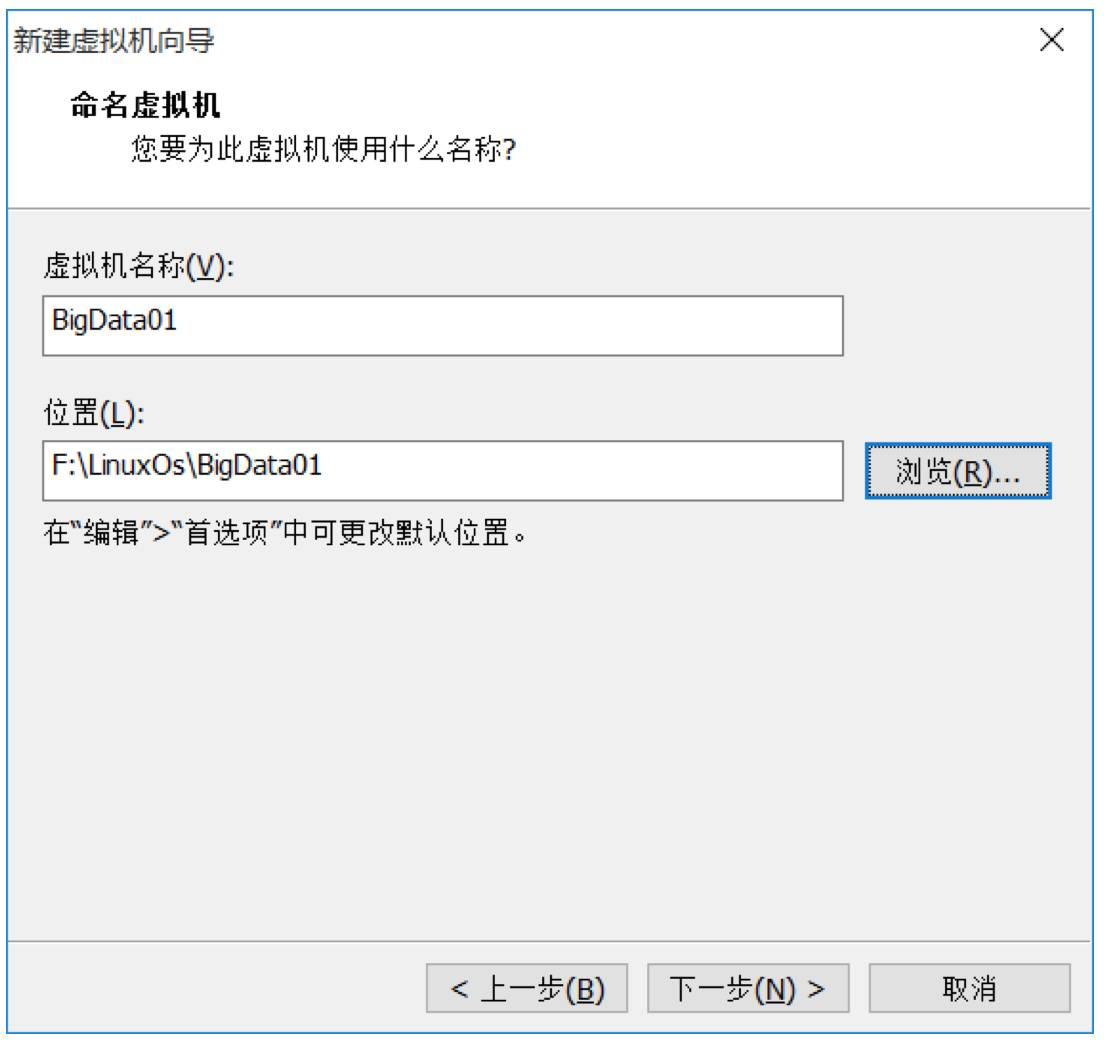
5. 命名虚拟机,给虚拟机起个名字,将来显示在Vmware左侧。并选择Linux系统保存在宿主机的哪个目录下,应该一个虚拟机保存在一个目录下,不能多个虚拟机使用一个目录。
6. 指定磁盘容量,是指定分给Linux虚拟机多大的硬盘,默认20G就可以,下一步。
7. 点击自定义硬件,可以查看、修改虚拟机的硬件配置,这里我们不做修改。
8. 点击完成后,就创建了一个虚拟机,但是此时的虚拟机还是一个空壳,没有操作系统,接下来安装操作系统。
9. 点击编辑虚拟机设置,找到DVD,指定操作系统ISO文件所在位置。
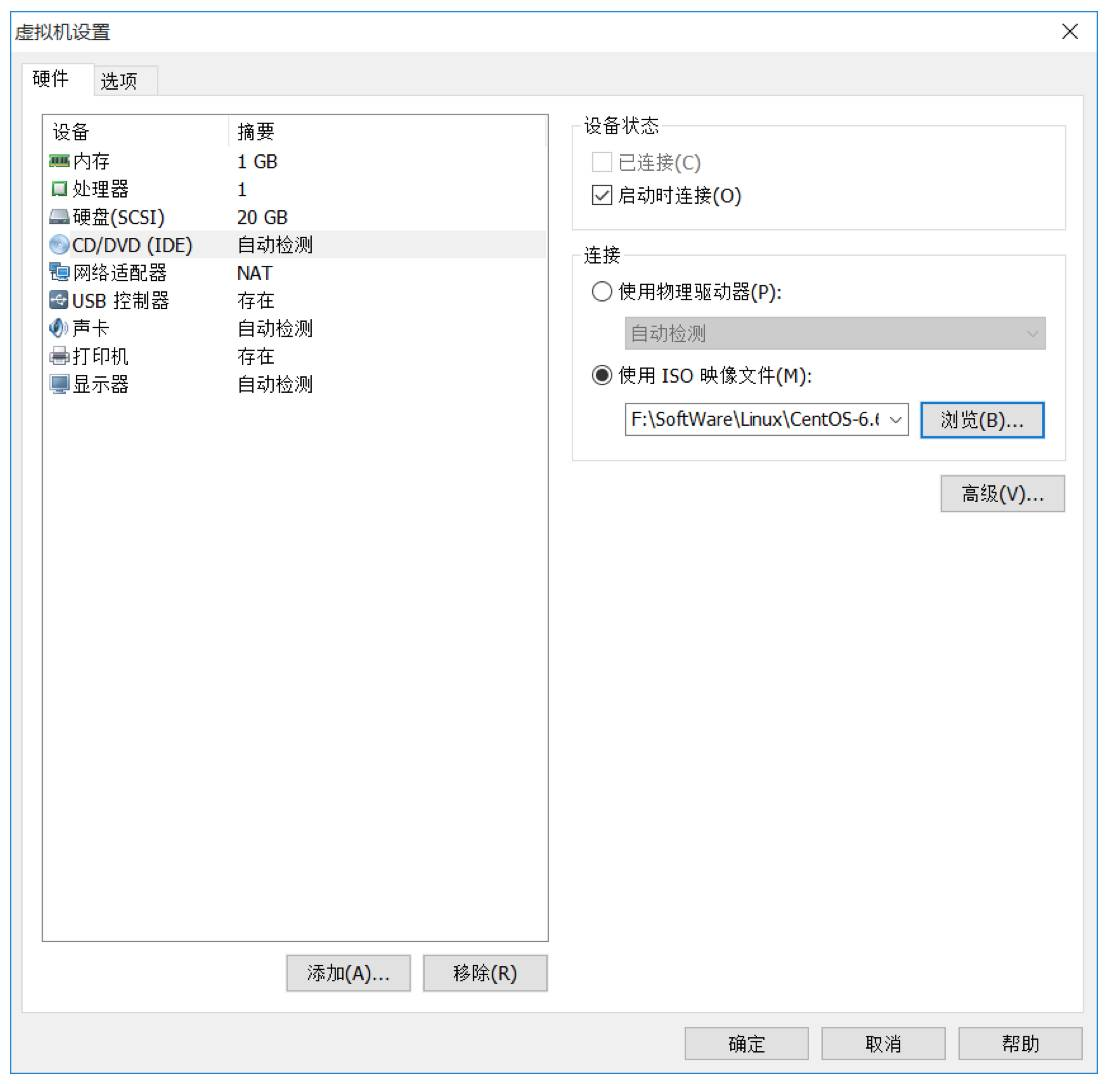
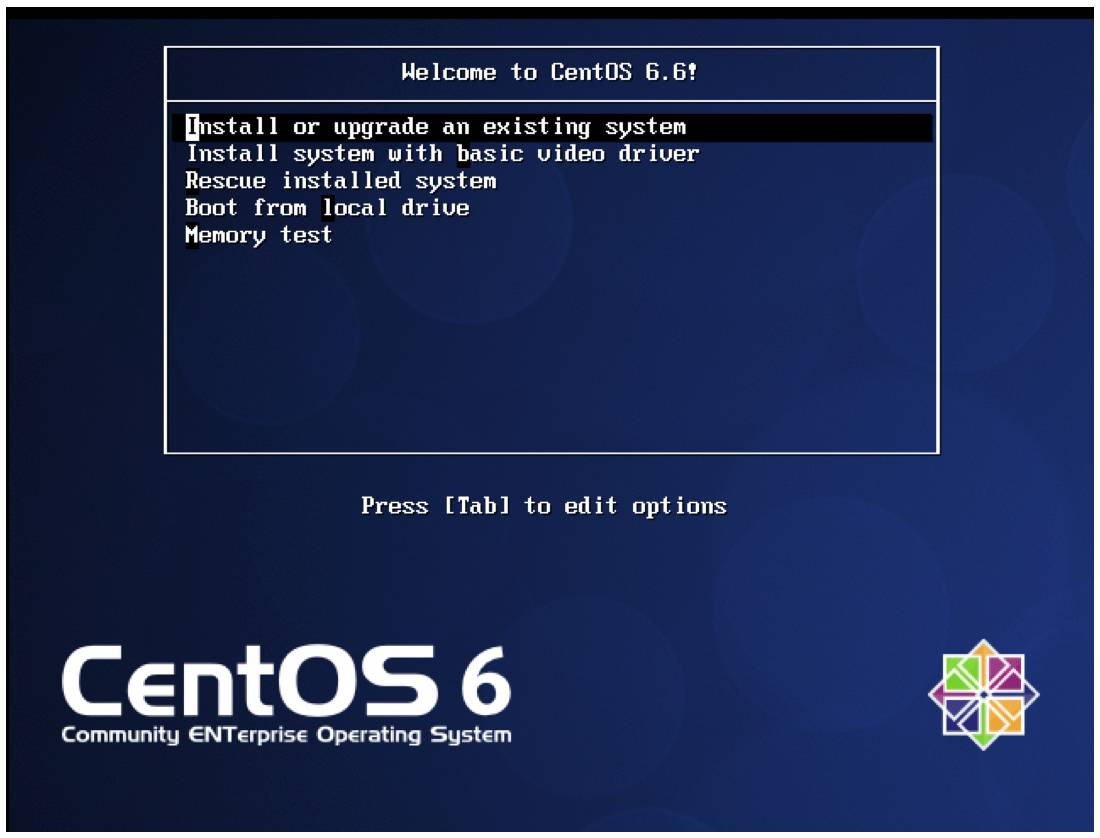
10. 点击开启此虚拟机,选择第一个回车开始安装操作系统。
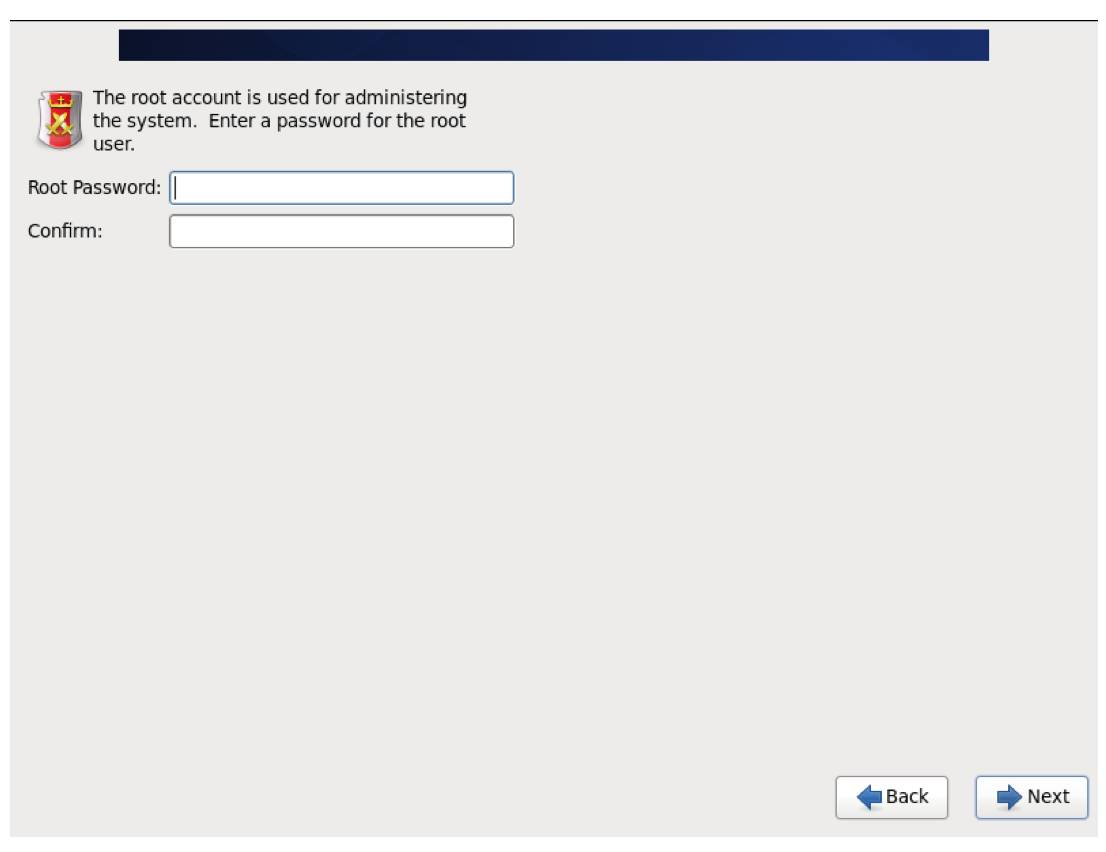
11. 设置 root 密码。
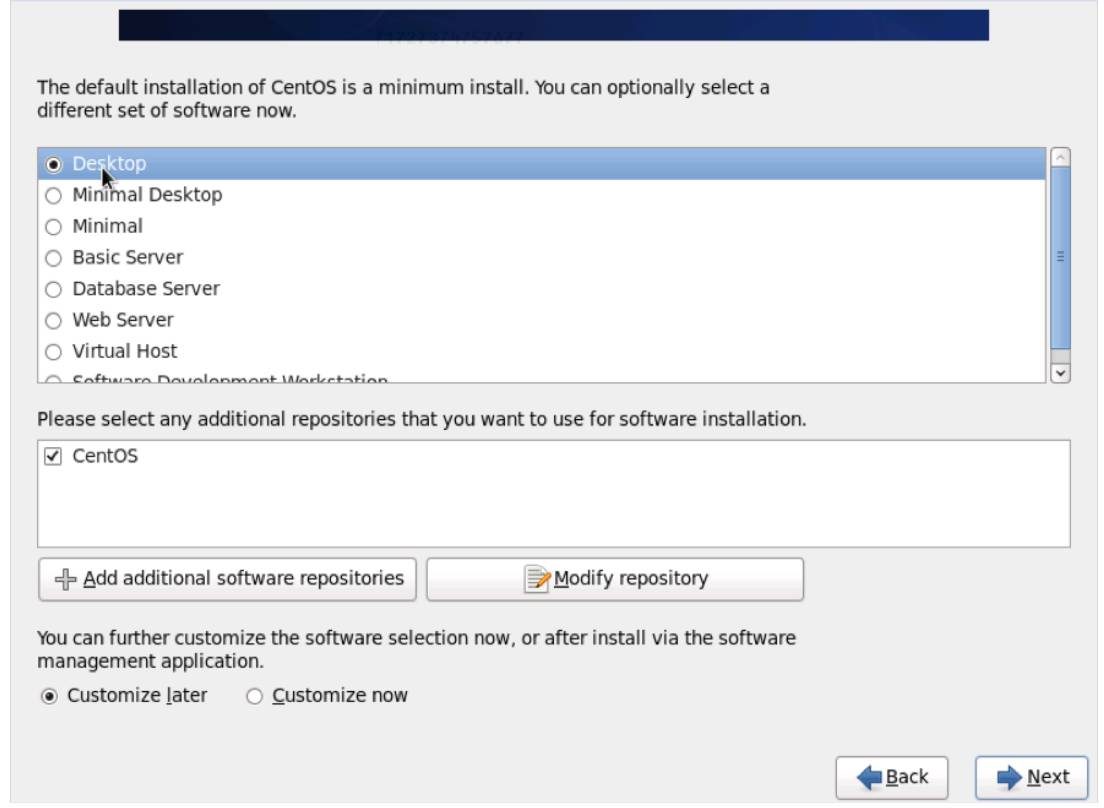
12. 选择 Desktop,这样就会装一个 Xwindow。
13. 先不添加普通用户,其他用默认的,就把Linux安装完毕了。
四、设置网络
因为 Vmware 的 NAT 设置中关闭了 DHCP 自动分配 IP 功能,所以 Linux 还没有 IP,需要我们设置网络各个参数。
1. 用 root 进入 Xwindow,右击右上角的网络连接图标,选择修改连接。
2. 网络连接里列出了当前 Linux 里所有的网卡,这里只有一个网卡 System eth0,点击编辑。
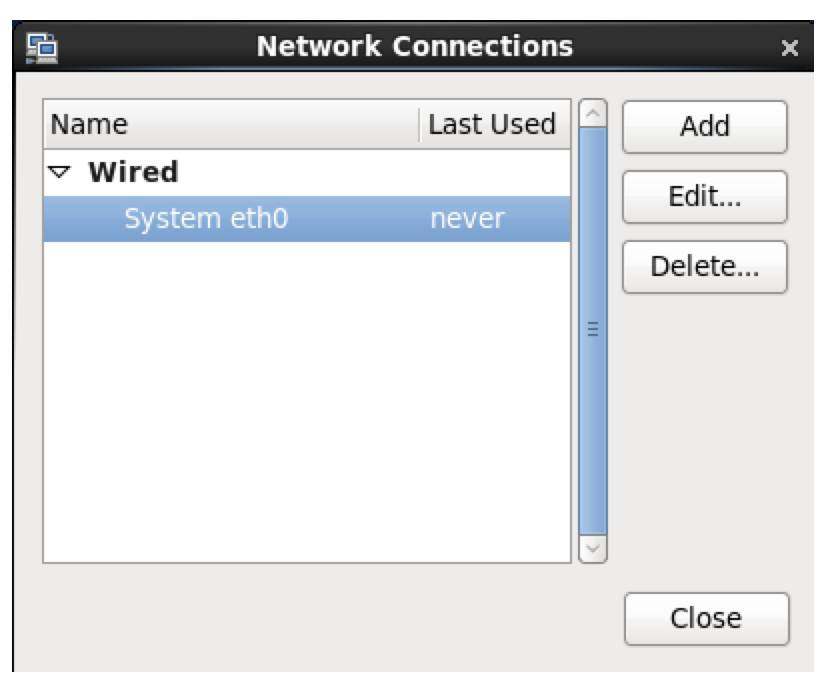
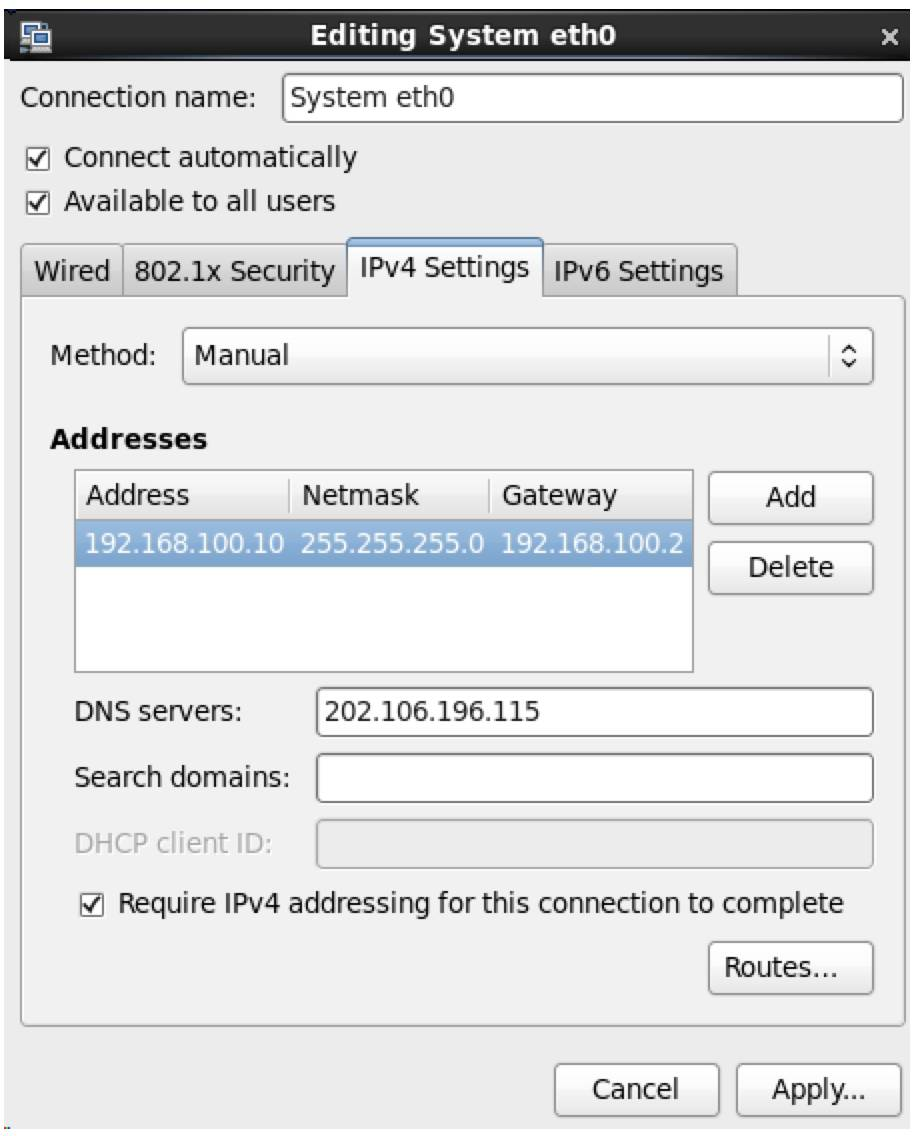
3. 配置IP、子网掩码、网关(和NAT设置的一样)、DNS等参数,因为NAT里设置网段为100.*,所以这台机器可以设置为192.168.100.10网关和NAT一致,为192.168.100.2
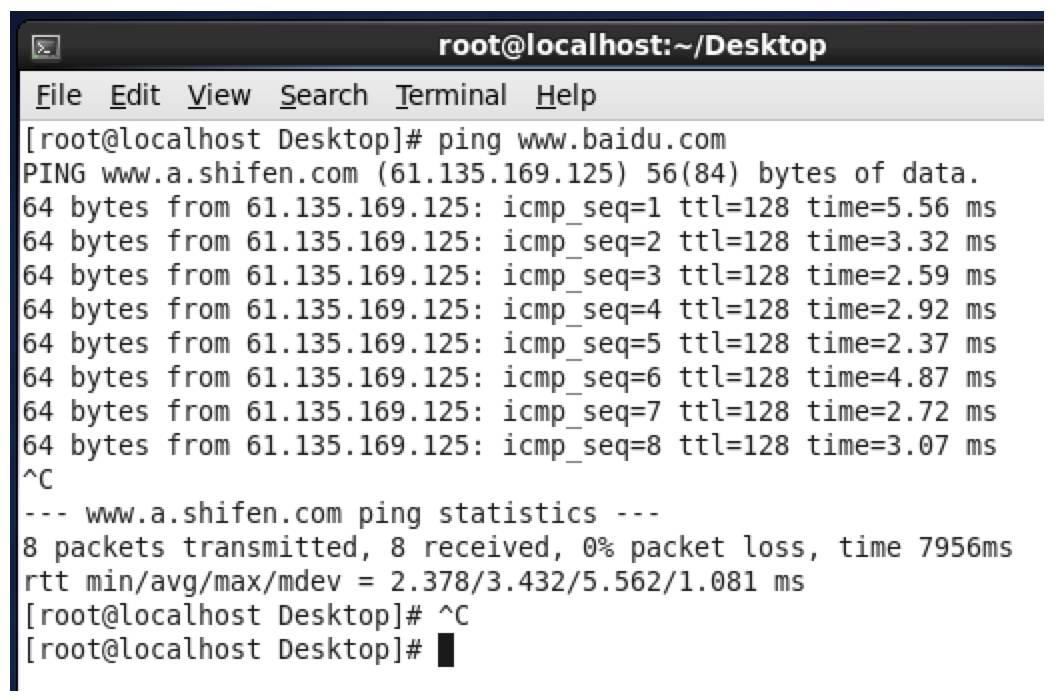
4. 用ping来检查是否可以连接外网,如下图,已经连接成功。
五、修改 Hostname
1. 临时修改 hostname
[root@localhost Desktop]# hostname bigdata-senior01.chybinmy.com这种修改方式,系统重启后就会失效。
2. 永久修改 hostname
想永久修改,应该修改配置文件 /etc/sysconfig/network。
命令:[root@bigdata-senior01 ~] vim /etc/sysconfig/network打开文件后,
NETWORKING=yes #使用网络
HOSTNAME=bigdata-senior01.chybinmy.com #设置主机名六、配置Host
命令:[root@bigdata-senior01 ~] vim /etc/hosts
添加hosts: 192.168.100.10 bigdata-senior01.chybinmy.com七、关闭防火墙
学习环境可以直接把防火墙关闭掉。
(1) 用root用户登录后,执行查看防火墙状态。
[root@bigdata-senior01 hadoop]# service iptables status(2) 用 [root@bigdata-senior01 hadoop]# service iptables stop 关闭防火墙,这个是临时关闭防火墙。
[root@bigdata-senior01 hadoop-2.5.0]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ](3) 如果要永久关闭防火墙用。
[root@bigdata-senior01 hadoop]# chkconfig iptables off关闭,这种需要重启才能生效。
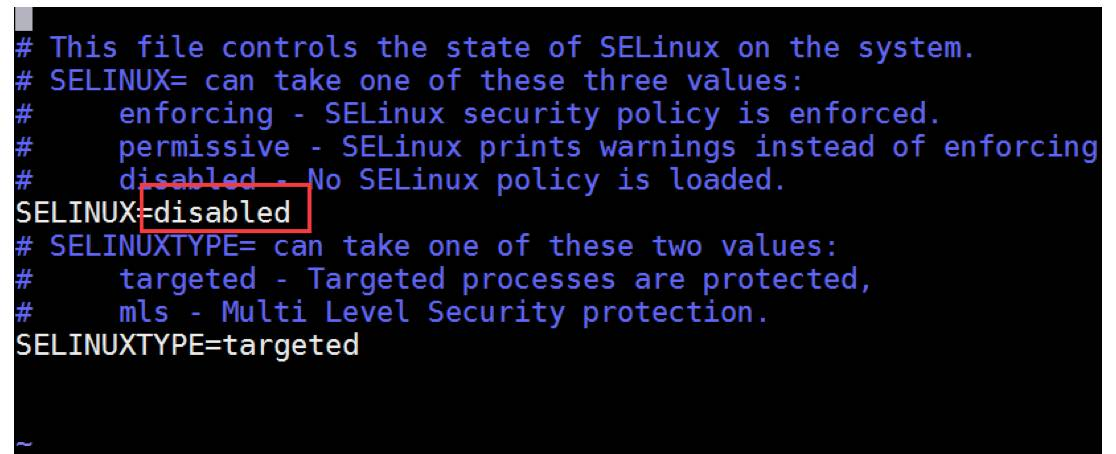
八、关闭selinux
selinux是Linux一个子安全机制,学习环境可以将它禁用。

第三步、安装JDK
九、安装 Java JDK
1. 查看是否已经安装了 java JDK。
[root@bigdata-senior01 Desktop]# java –version注意:Hadoop 机器上的 JDK,最好是 Oracle 的 Java JDK,不然会有一些问题,比如可能没有 JPS 命令。
如果安装了其他版本的 JDK,卸载掉。
2. 安装 java JDK
(1) 去下载 Oracle 版本 Java JDK:jdk-7u67-linux-x64.tar.gz
(2) 将 jdk-7u67-linux-x64.tar.gz 解压到 /opt/modules 目录下
[root@bigdata-senior01 /]# tar -zxvf jdk-7u67-linux-x64.tar.gz -C /opt/modules(3) 添加环境变量
设置 JDK 的环境变量 JAVA_HOME。需要修改配置文件/etc/profile,追加
export JAVA_HOME="/opt/modules/jdk1.7.0_67"export PATH=$JAVA_HOME/bin:$PATH修改完毕后,执行 source /etc/profile
(4)安装后再次执行 java –version,可以看见已经安装完成。

第二部分:Hadoop本地模式安装
第四步、Hadoop部署模式
Hadoop 部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是 NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
| 模式名称 | 各个模块占用的JVM进程数 | 各个模块运行在几个机器数上 |
|---|---|---|
| 本地模式 | 1个 | 1个 |
| 伪分布式模式 | N个 | 1个 |
| 完全分布式模式 | N个 | N个 |
| HA完全分布式 | N个 | N个 |
第五步、本地模式部署
十、本地模式介绍
本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载 hadoop 安装包后不用任何设置,默认的就是本地模式。
十一、解压hadoop后就是直接可以使用
1. 创建一个存放本地模式hadoop的目录
[hadoop@bigdata-senior01 modules]$ mkdir /opt/modules/hadoopstandalone2. 解压 hadoop 文件

3. 确保 JAVA_HOME 环境变量已经配置好
[hadoop@bigdata-senior01 modules]$ echo ${JAVA_HOME}
/opt/modules/jdk1.7.0_67十二、运行MapReduce程序,验证
我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
1. 准备mapreduce输入文件wc.input
[hadoop@bigdata-senior01 modules]$ cat /opt/data/wc.input
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop2. 运行 hadoop 自带的 mapreduce Demo

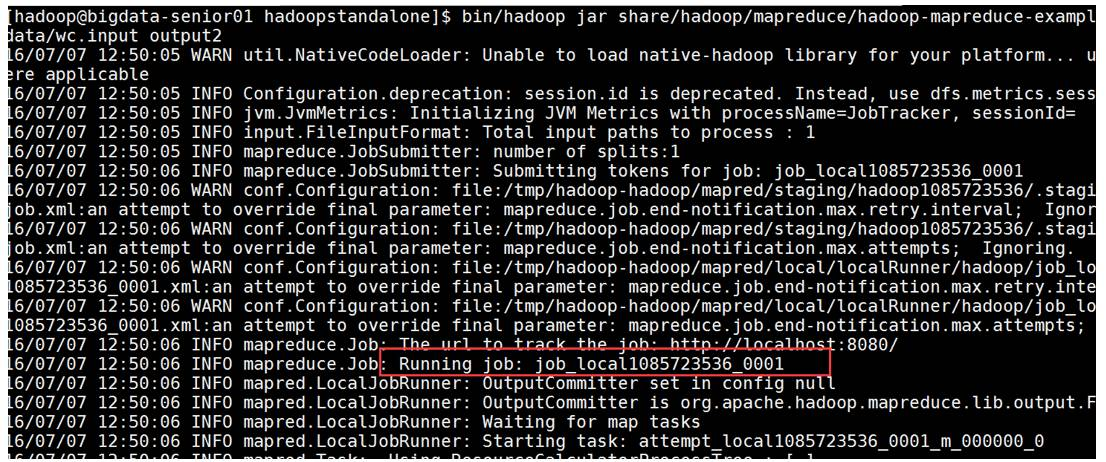
这里可以看到 job ID 中有 local 字样,说明是运行在本地模式下的。
3. 查看输出文件
本地模式下,mapreduce 的输出是输出到本地。

输出目录中有 _SUCCESS 文件说明 JOB 运行成功,part-r-00000 是输出结果文件。
【未完,请待明天文章】
第三部分:Hadoop 伪分布式模式安装

