

现在有很多爬虫框架,比如scrapy、webmagic、pyspider,也可以直接通过requests+ beautifulsoup来写一些个性化的小型爬虫脚本。但是在实际爬取过程当中,爬虫框架各自有各自的优势和缺陷。所以我模仿这些爬虫框架的优势,搭配gevent(实际上是grequests)开发了这套轻量级爬虫框架。
主要特点
- 框架代码结构简单易用,易于修改。例如针对出现验证码的处理方法。
- 采用gevent实现并发操作,与scrapy的twisted相比,代码更容易理解。
- 完全模块化的设计,强大的可扩展性。
- 使用方式和结构参考了scrapy和webmagic。对有接触过这两个框架的朋友非常友好。
- 对数据的解析模块并没有集成,可以自由使用beautifulsoup、lxml、pyquery、 html5lib等等各种解析器进行数据抽取。
- 集成代理换IP功能。
- 支持多线程。
- 支持分布式。
- 支持增量爬取。
- 支持爬取js动态渲染的页面。
- 提供webapi对爬虫进行管理、监控。
- 提供即时爬虫的集成思路和结构。
安装
pip install sasila准备
- 请准备好您的redis服务器进行调度。
-
并在settings.py文件中 写入您的redis服务器地址
REDIS_HOST = 'localhost' REDIS_PORT = 6379构建processor(解析器)
from bs4 import BeautifulSoup as bs from sasila.slow_system.base_processor import BaseProcessor from sasila.slow_system.downloader.http.spider_request import Request from sasila.slow_system.core.request_spider import RequestSpider class Mzi_Processor(BaseProcessor): spider_id = 'mzi_spider' spider_name = 'mzi_spider' allowed_domains = ['mzitu.com'] start_requests = [Request(url='http://www.mzitu.com/', priority=0)] @checkResponse def process(self, response): soup = bs(response.m_response.content, 'lxml') print soup.title.string href_list = soup.select('a') for href in href_list: yield Request(url=response.nice_join(href['href']))写法与scrapy几乎一样
-
所有的解析器都继承自 BaseProcessor ,默认入口解析函数为def process(self, response)。
- 为该解析器设置spider_id和spider_name,以及限定域名。
- 初始爬取请求为 start_requests,构建Request对象,该对象支持GET、POST方法,支持优先级,设置回调函数等等所有构建request对象的一切属性。默认回调函数为 process。
- 可以使用@checkResponse装饰器对返回的 response 进行校验并记录异常日志。你也可以定义自己的装饰器。
- 解析函数因为使用 yield 关键字,所以是一个生成器。当 yield 返回 Request 对象,则会将 Request 对象推入调度器等待调度继续进行爬取。若 yield 不是返回 Request 对象则会进入 pipeline , pipeline 将对数据进行清洗入库等操作。
构建pipeline
from sasila.slow_system.pipeline.base_pipeline import ItemPipeline
class ConsolePipeline(ItemPipeline):
def process_item(self, item):
print json.dumps(item).decode("unicode-escape")构建spider(爬虫对象)
- 通过注入 processor 生成spider对象
from sasila.slow_system.core.request_spider import RequestSpider spider = RequestSpider(Mzi_Processor()) - RequestSpider对象包含批下载数量 batch_size,下载间隔 time_sleep,使用代理 use_proxy 等一切必要的属性
RequestSpider(processor=None, downloader=None, use_proxy=False,scheduler=None,batch_size=None,time_sleep=None) - 本项目集成使用代理IP的功能,只要在构建RequestSpider时将 use_proxy 设置为 True,并在脚本同级目录下放置proxy.txt文件即可。你也可以在settings.py文件中写入代理IP文件路径。
PROXY_PATH_REQUEST = 'proxy/path' - RequestSpider已经默认设置好了 downloader 和 scheduler,如果不满意,可以自己进行定制。
- 可以为spider设置 downloader 和 pipeline 甚至 scheduler
spider = spider.set_pipeline(ConsolePipeline()) - 可以通过该方式启动爬虫
spider.start() - 也可以将spider注入manager进行管理
from sasila.slow_system.manager import manager manager.set_spider(spider) sasila.start()
访问 http://127.0.0.1:5000/slow_spider/start?spider_id=mzi_spider 来启动爬虫。
访问 http://127.0.0.1:5000/slow_spider/stop?spider_id=mzi_spider 来停止爬虫。
访问 http://127.0.0.1:5000/slow_spider/detail?spider_id=mzi_spider 来查看爬虫详细信息。
针对需要登录才能爬取的处理办法
- 可以为downloader加载登录器(loginer),在使用downloader的时候使用loginer进行登录获取cookies,再进行爬取
- 也可以自己定义一个cookie池,批量进行登录并将登录成功的cookies放进cookie池中随时进行取用。项目中暂时没有这些功能。欢迎pull request~
架构
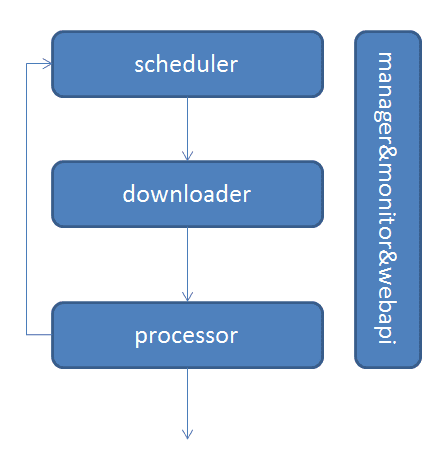
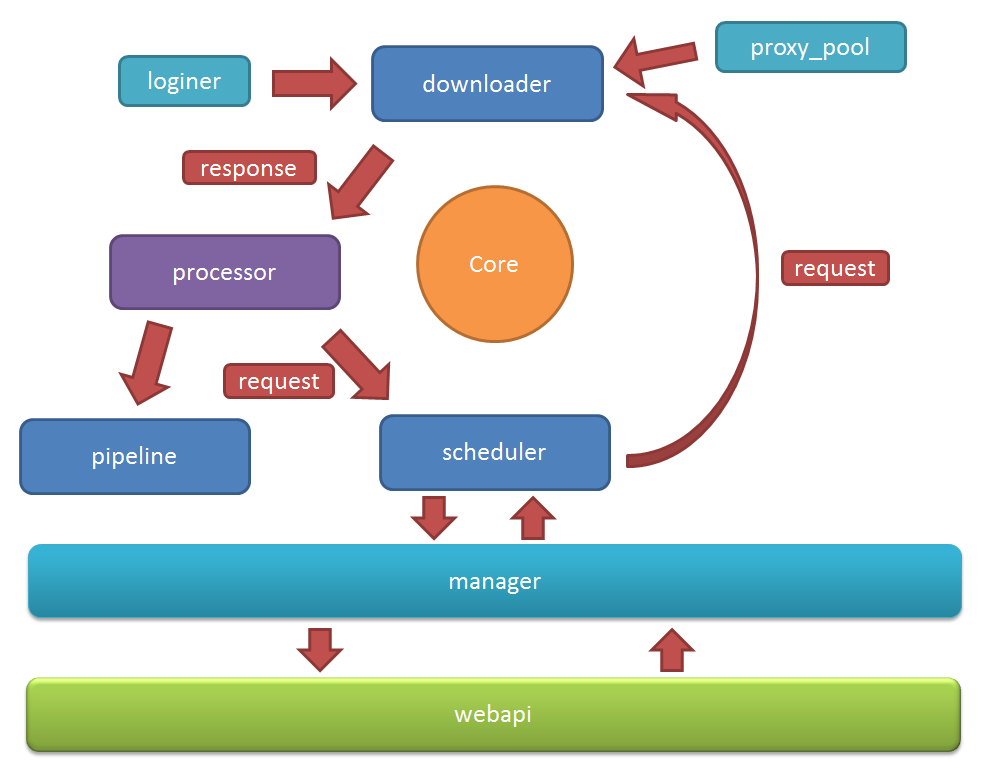
- 任务由 scheduler 发起调度,downloader 抓取网页内容, processor 执行预先编写的py脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
- 每个脚本被认为是一个spider,spiderid确定一个任务。
- downloader
- method, header, cookie, proxy,timeout 等等抓取调度控制。
- 可以通过适配类似 phantomjs 的webkit引擎支持渲染。
- processor
- 灵活运用pyquery,beautifulsoup等解析页面。
- 在脚本中完全控制调度抓取的各项参数。
- 可以向后链传递信息。
- 异常捕获。
- scheduler
- 任务优先级。
- 对任务进行监控。
- 对任务进行去重等操作。
- 支持增量。
- webApi
- 对爬虫进行增删改查等操作。
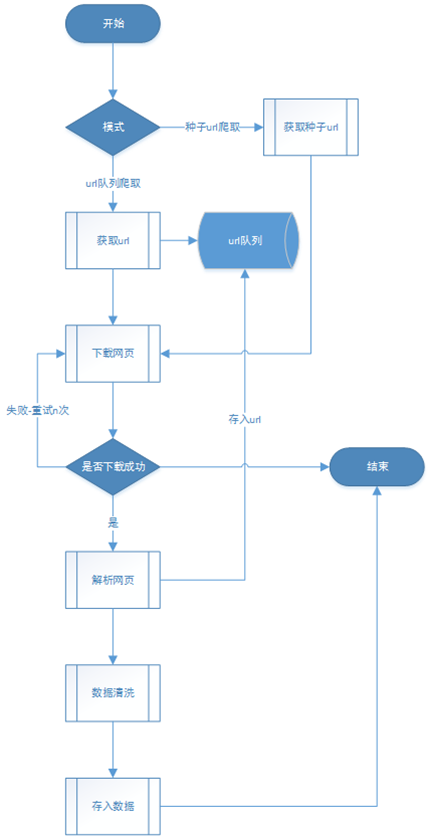
非及时爬虫流程图
即时爬虫
即时爬虫是可以通过api调用,传入需要爬取的页面或者需求,即时爬取数据并返回结果。现阶段开发并不完善。仅提供思路参考。示例核心代码在 sasila.immediately_system 中。
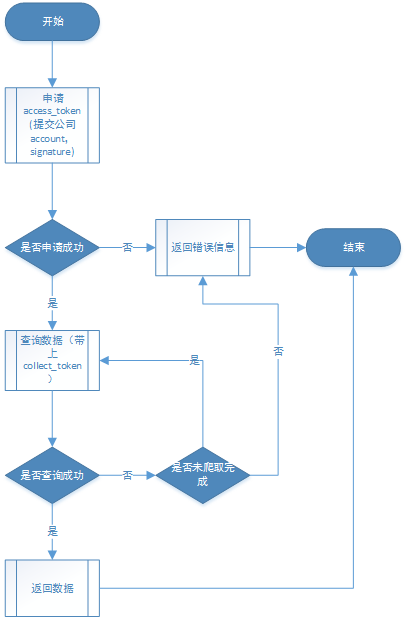
即时爬虫-获取数据流程图
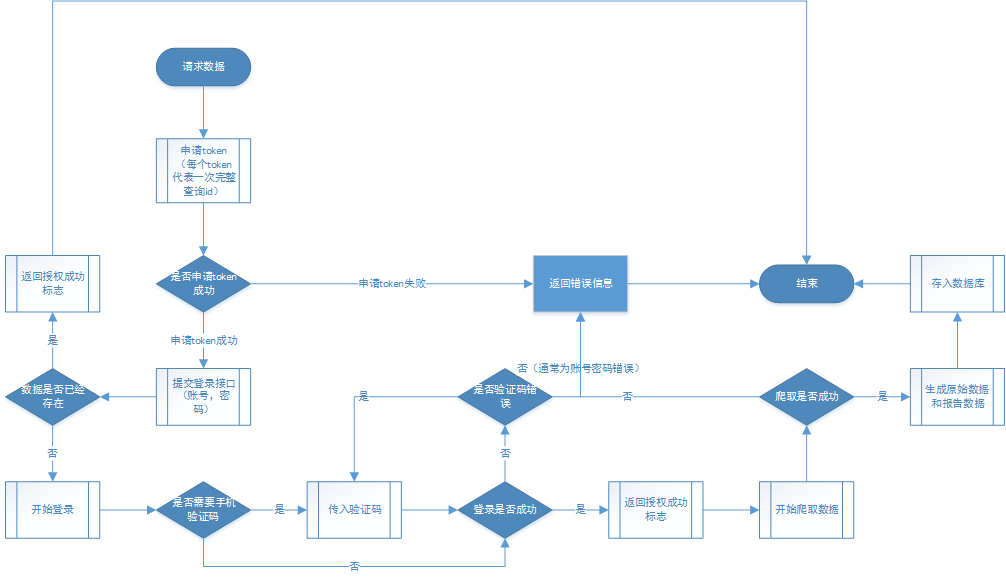
即时爬虫-授权流程图
为啥叫Sasila
作为一个wower,你可以猜到吗ヾ( ̄▽ ̄)
