Contents Created by Toggle
flask-start V0.1. Released at 2017/07/03.
本篇文章将会解析从本地开发服务器的启动过程,首先由Flask app启动,然后到app如何接受到WSGI服务器的调用,再到WSGI服务器如何接受一个TCP数据,最后就是套接字编程的网络服务器一系列的过程,争取对框架的底层运行原理做一个深入的理解。
Flask 启动流程
首先Flask应用启动是在Flask类的run方法:
def run(self, host=None, port=None, debug=None, **options):
'''不要在生产环境使用run(),因为这个服务器没有足够的安全和性能。
debug设置之后服务器将会自动重载代码的变动,并且如果有异常发生就会出现一个debugger
如果想在debug模式运行,但是要关闭交互式debugger的代码运行,设置use_evalex=False
警告:Flask会抑制所有的服务器错误页面生成,除非在debug模式,如果只要use_debugger,不要use_reloader的话,可以分别设置其参数
'''
from werkzeug.serving import run_simple
_host = '127.0.0.1'
_port = 5000
server_name = self.config.get("SERVER_NAME")
sn_host, sn_port = None, None
if server_name:
sn_host, _, sn_port = server_name.partition(':')
host = host or sn_host or _host
port = int(port or sn_port or _port)
if debug is not None:
self.debug = bool(debug)
options.setdefault('use_reloader', self.debug)
options.setdefault('use_debugger', self.debug)
try:
run_simple(host, port, self, **options)
finally:
# 如果服务器重置,则重置信息
self._got_first_request = False
可以看到,run方法只是将host,port等参数做了些处理,接下来应用启动是调用了run_simple函数,传入host, port和应用对象,以及相关参数,启动一个WSGI应用
def run_simple(hostname, port, application, use_reloader=False,
use_debugger=False, use_evalex=True,
extra_files=None, reloader_interval=1,
reloader_type='auto', threaded=False,
processes=1, request_handler=None, static_files=None,
passthrough_errors=False, ssl_context=None):
# 这里返回了一个开发服务器的实例
if use_debugger:
from werkzeug.debug import DebuggedApplication
application = DebuggedApplication(application, use_evalex)
# 启动一个中间件
if static_files:
from werkzeug.wsgi import SharedDataMiddleware
application = SharedDataMiddleware(application, static_files)
# 启动信息,传入的是套接字对象
def log_startup(sock):
display_hostname = hostname not in ('', '*') and hostname or 'localhost'
if ':' in display_hostname:
display_hostname = '[%s]' % display_hostname
quit_msg = '(Press CTRL+C to quit)'
# 获取host和port
port = sock.getsockname()[1]
_log('info', ' * Running on %s://%s:%d/ %s',
ssl_context is None and 'http' or 'https',
display_hostname, port, quit_msg)
def inner():
try:
# 获取这个参数,如果这个参数为None,就打印启动信息
fd = int(os.environ['WERKZEUG_SERVER_FD'])
except (LookupError, ValueError):
fd = None
srv = make_server(hostname, port, application, threaded,
processes, request_handler,
passthrough_errors, ssl_context,
fd=fd)
if fd is None:
log_startup(srv.socket)
srv.serve_forever()
inner()
这里省略了源码中的use_reloader部分,因为这个对于我们理解服务器的启动核心过程没有什么价值,所以我们先理清主干后,再去研究这些细节问题。
可以看到,run_simple主要的工作就是首先创建了一个服务器对象,然后启动之。继续到make_server中查看:
def make_server(host=None, port=None, app=None, threaded=False, processes=1,
request_handler=None, passthrough_errors=False,
ssl_context=None, fd=None):
"""Create a new server instance that is either threaded, or forks
or just processes one request after another.
"""
if threaded and processes > 1:
raise ValueError("cannot have a multithreaded and "
"multi process server.")
elif threaded:
return ThreadedWSGIServer(host, port, app, request_handler,
passthrough_errors, ssl_context, fd=fd)
elif processes > 1:
return ForkingWSGIServer(host, port, app, processes, request_handler,
passthrough_errors, ssl_context, fd=fd)
else:
return BaseWSGIServer(host, port, app, request_handler,
passthrough_errors, ssl_context, fd=fd)
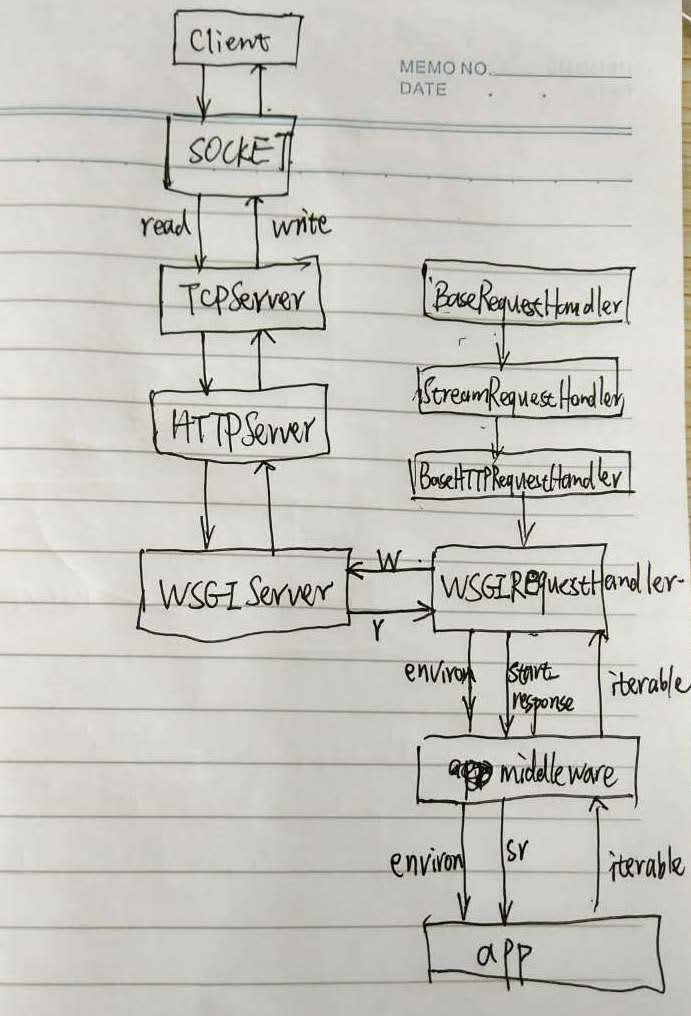
这里面就是根据参数不同创建一些不同类型的服务器,ForkingWSGIServer和ThreadedWSGIServer都是继承于BaseWSGIServer,然后扩展了些Mixin。继续向上研究,可以发现,主要有两个部分,一个是Server部分,是运行服务器服务的,一个是RequestHandler部分,用来处理请求的。里面的继承略有复杂,这里就将其梳理一遍,从最开始的类到最后面的应用。
Server
继承关系是BaseWSGIServer->HTTPServer->socketserver.TCPServer->socketserver.BaseServer
socketserver.BaseServer
class BaseServer:
timeout = None
def __init__(self, server_address, RequestHandlerClass):
"""Constructor. May be extended, do not override."""
self.server_address = server_address
self.RequestHandlerClass = RequestHandlerClass
self.__is_shut_down = threading.Event()
self.__shutdown_request = False
def server_activate(self):
# 激活服务器,重写
pass
def serve_forever(self, poll_interval=0.5):
'''关闭之前一次处理一个请求,每0.5秒轮询事件发生'''
self.__is_shut_down.clear()
try:
with _ServerSelector() as selector:
# selector对象,self是文件句柄或者文件描述符,操作的事件
# 注册轮询事件
selector.register(self, selectors.EVENT_READ)
while not self.__shutdown_request:
# 轮询等待事件的发生
ready = selector.select(poll_interval)
if ready:
self._handle_request_noblock()
self.service_actions()
finally:
self.__shutdown_request = False
self.__is_shut_down.set()
def shutdown(self):
'''告诉server_forever循环停止,并且等待其停止'''
self.__shutdown_request = True
self.__is_shut_down.wait()
def _handle_request_noblock(self):
'''非阻塞处理一个请求,在这个方法调用之前,假定select已经返回一个可以读的套接字,所以get_request就不会阻塞了,get_request函数将由子类实现'''
try:
request, client_address = self.get_request()
except OSError:
return
if self.verify_request(request, client_address):
try:
self.process_request(request, client_address)
except:
self.handle_error(request, client_address)
self.shutdown_request(request)
else:
self.shutdown_request(request)
def verify_request(self, request, client_address):
'''子类实现'''
return True
def process_request(self, request, client_address):
'''ForkingMixIn和ThreadingMixIn实现'''
self.finish_request(request, client_address)
self.shutdown_request(request)
def finish_request(self, request, client_address):
'''通过实例化一个RequestHandlerClass来结束一个请求'''
self.RequestHandlerClass(request, client_address, self)
def shutdown_request(self, request):
'''关闭一个单独的请求'''
self.close_request(request)
def close_request(self, request):
'''关闭并且清理一个请求'''
pass
def handle_error(self, request, client_address):
'''优雅的处理错误,默认是打印错误,并且继续'''
print('-'*40)
print('Exception happened during processing of request from', end=' ')
print(client_address)
import traceback
traceback.print_exc() # XXX But this goes to stderr!
print('-'*40)
def service_actions(self):
'''server_forever循环来调用之,需要在循环执行的代码'''
pass
def handle_request(self):
'''可能是阻塞处理一个请求'''
timeout = self.socket.gettimeout()
if timeout is None:
timeout = self.timeout
elif self.timeout is not None:
timeout = min(timeout, self.timeout)
if timeout is not None:
deadline = time() + timeout
# 等待一个请求到来或者直到超时
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ)
while True:
ready = selector.select(timeout)
if ready:
return self._handle_request_noblock()
else:
if timeout is not None:
timeout = deadline - time()
if timeout < 0:
return self.handle_timeout()
BaseServer是所有服务器对象的超类,定义了接口,但是大多数方法不实现,在子类中细化。其中有几个比较主要的处理请求的方法:
handle_request是最顶层的调用,它调用了selector.select(),get_request, verify_request, process_requestget_request方法对于流套接字和数据报套接字是不同的verify_request方法来实现服务器对访问的控制,比如只处理指定IP区间的请求process_request可能会创建一个新进程或者线程去完成请求finish_request实例化一个请求处理器类,它会自己处理请求
下来就是TCP Server了
socketserver.TCPServer
class TCPServer(BaseServer):
# ip v4, AF_INET6
address_family = socket.AF_INET
# tcp, socket.SOCK_DGRAM udp
socket_type = socket.SOCK_STREAM
request_queue_size = 5
allow_reuse_address = False
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
try:
# 绑定,listen
self.server_bind()
self.server_activate()
except:
self.server_close()
raise
def server_bind(self):
if self.allow_reuse_address:
# 设置socket的选项
# 第一个参数是level, SOL_SOCKET的含义是正在使用的socket选项
# 操作系统会在服务器socket被关闭或服务器进程终止后马上释放该服务器的端口,否则操作系统会保留几分钟该端口。
# 1是value
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname()
def server_activate(self):
'''监听端口'''
# 指定最多允许多少个客户连接到服务器
self.socket.listen(self.request_queue_size)
def server_close(self):
self.socket.close()
def fileno(self):
'''返回socket的文件句柄'''
return self.socket.fileno()
def get_request(self):
'''返回值是连接,新的socket对象和客户的地址'''
return self.socket.accept()
def shutdown_request(self, request):
try:
# 关闭读写功能
request.shutdown(socket.SHUT_WR)
except OSError:
pass #some platforms may raise ENOTCONN here
self.close_request(request)
def close_request(self, request):
'''关闭一个TCP连接'''
request.close()
可以看到TCPServer在BaseServer基础上实现了具体的连接,使用的就是套接字编程,其中get_request即返回一个TCP连接,后续的数据读取等就是通过该TCP连接进行的,主要的请求处理逻辑还在_handle_request_noblock上,具体如何将本次TCP连接获取的数据(请求)进行处理是在RequestHandler进行的。
http.server.HTTPServer
class HTTPServer(socketserver.TCPServer):
allow_reuse_address = 1
def server_bind(self):
"""Override server_bind to store the server name."""
socketserver.TCPServer.server_bind(self)
host, port = self.socket.getsockname()[:2]
# 将使用点号分隔的 IP 地址字符串转换成一个完整的域名
self.server_name = socket.getfqdn(host)
self.server_port = port
这里的HTTPServer很简单,就只是存储了服务器的名字和端口。
BaseWSGIServer
下来就是werkzeug实现的一个简单的WSGI服务器了,单线程,单进程WSGI服务器,具体代码如下:
class BaseWSGIServer(HTTPServer, object):
multithread = False
multiprocess = False
request_queue_size = LISTEN_QUEUE # 128
def __init__(self, host, port, app, handler=None,
passthrough_errors=False, ssl_context=None, fd=None):
if handler is None:
# 载入默认的请求处理器,这个是处理请求的关键
handler = WSGIRequestHandler
self.address_family = select_ip_version(host, port)
if fd is not None:
# 从现有的文件描述符创建一个 socket 对象
real_sock = socket.fromfd(fd, self.address_family,
socket.SOCK_STREAM)
port = 0
HTTPServer.__init__(self, (host, int(port)), handler)
self.app = app
self.passthrough_errors = passthrough_errors
self.shutdown_signal = False
self.host = host
self.port = port
# HTTPServer只能接受addr和handler,所以得创建后再关闭,使用fd创建的socket
if fd is not None:
self.socket.close()
self.socket = real_sock
self.server_address = self.socket.getsockname()
if ssl_context is not None:
if isinstance(ssl_context, tuple):
ssl_context = load_ssl_context(*ssl_context)
if ssl_context == 'adhoc':
ssl_context = generate_adhoc_ssl_context()
# If we are on Python 2 the return value from socket.fromfd
# is an internal socket object but what we need for ssl wrap
# is the wrapper around it :(
sock = self.socket
if PY2 and not isinstance(sock, socket.socket):
sock = socket.socket(sock.family, sock.type, sock.proto, sock)
self.socket = ssl_context.wrap_socket(sock, server_side=True)
self.ssl_context = ssl_context
else:
self.ssl_context = None
def log(self, type, message, *args):
_log(type, message, *args
def serve_forever(self):
self.shutdown_signal = False
try:
HTTPServer.serve_forever(self)
except KeyboardInterrupt:
pass
finally:
self.server_close()
def handle_error(self, request, client_address):
if self.passthrough_errors:
raise
return HTTPServer.handle_error(self, request, client_address)
def get_request(self):
con, info = self.socket.accept()
return con, info
WSGI服务器,最重要的一点是加入了app参数,这样以后才可以调用app的wsgi_app,然后将请求处理器得到的environ信息传入,然后app处理请求,基本的流程到这里已经很清晰了。
RequestHandler
请求处理器的继承关系为BaseRequestHandler->socketserver.StreamRequestHandler->BaseHTTPRequestHandler->WSGIRequestHandler
BaseRequestHandler
class BaseRequestHandler:
'''请求处理器类的基类,对于每一个请求实例化并且处理,首先创建了request,client_address和server实例变量,然后调用handler方法,为了应用在指定的服务上,必须派生这个类然后定义handle方法。由于为每一个请求独立的创建了实例,因此handle方法可以定义其他任意的实例变量.'''
def __init__(self, request, client_address, server):
# request即是一个TCP连接对象
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish()
def setup(self):
pass
def handle(self):
pass
def finish(self):
pass
可以看到传入一个建立的TCP连接,以及连接信息,服务器信息,来此进行请求的处理,首先调用了setup方法进行初始化工作,然后是调用handle方法实际处理请求,最后调用finish来清理结束工作。
socketserver.StreamRequestHandler
class StreamRequestHandler(BaseRequestHandler):
'''self.rfile和self.wfile用于流套接字的处理'''
# 读有缓存是因为如果没有缓存读取大数据可能非常慢
# 写没有缓存是因为在写完之后需要读取,因此需要flush
# 大量数据写入没有缓存可以有最大的利用率
rbufsize = -1
wbufsize = 0
timeout = None
# nagle算法,减少包的数量,即减少长度比较小的包的发送
disable_nagle_algorithm = False
def setup(self):
self.connection = self.request
if self.timeout is not None:
self.connection.settimeout(self.timeout)
if self.disable_nagle_algorithm:
self.connection.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, True)
# 创建读写套接字
self.rfile = self.connection.makefile('rb', self.rbufsize)
self.wfile = self.connection.makefile('wb', self.wbufsize)
def finish(self):
if not self.wfile.closed:
try:
self.wfile.flush()
except socket.error:
# A final socket error may have occurred here, such as
# the local error ECONNABORTED.
pass
self.wfile.close()
self.rfile.close()
流请求处理器做了这么几件事情,重写了setup方法,如果需要,设置超时时间,设置nagle算法。并且创建了读写套接字,设置其缓存。重写结束方法,对读写套接字进行清理。
BaseHTTPRequestHandler
class BaseHTTPRequestHandler(socketserver.StreamRequestHandler):
'''这里就到了HTTP的请求处理器了。
一个请求有三部分:
1. 指示请求类型和路径以及HTTP协议的请求行
2. 消息报头,包含各种参数
3. 请求体,即正文数据
消息报头和数据是通过一个空行分离的
返回第一行必须是响应行,然后是响应头,然后一个空行,接下来是真实数据。如果有数据,那么至少应该有这么一个头Content-type: <type>/<subtype>
'''
sys_version = "Python/" + sys.version.split()[0]
protocol_version = "HTTP/1.0"
server_version = "BaseHTTP/" + __version__
error_message_format = DEFAULT_ERROR_MESSAGE
error_content_type = DEFAULT_ERROR_CONTENT_TYPE
default_request_version = "HTTP/0.9"
def handle(self):
'''处理多个请求'''
self.close_connection = True
self.handle_one_request()
while not self.close_connection:
self.handle_one_request()
def handle_one_request(self):
'''处理单个的HTTP请求'''
try:
# 获取请求行
self.raw_requestline = self.rfile.readline(65537)
# 请求行太长,一般都是URI太长
if len(self.raw_requestline) > 65536:
self.requestline = ''
self.request_version = ''
self.command = ''
self.send_error(HTTPStatus.REQUEST_URI_TOO_LONG)
return
if not self.raw_requestline:
self.close_connection = True
return
if not self.parse_request():
return
# 解析好请求后,根据请求的方法来调用相关的处理方法
mname = 'do_' + self.command
if not hasattr(self, mname):
self.send_error(
HTTPStatus.NOT_IMPLEMENTED,
"Unsupported method (%r)" % self.command)
return
method = getattr(self, mname)
method()
self.wfile.flush() #actually send the response if not already done.
except socket.timeout as e:
#a read or a write timed out. Discard this connection
self.log_error("Request timed out: %r", e)
self.close_connection = True
return
def parse_request(self):
'''解析一个请求,请求应该被存储在self.raw_requestline, 结果在self.command, self.path, self.request_version和self.request_version
返回True为成功,False是失败,并且错误会被发送回去'''
self.command = None
self.request_version = version = self.default_request_version
self.close_connection = True
# 直接用编码来decode数据,返回str
requestline = str(self.raw_requestline, 'iso-8859-1')
requestline = requestline.rstrip('\r\n')
words = requestline.split()
if len(words) == 3:
command, path, version = words
if version[:5] != 'HTTP/':
self.send_error(
HTTPStatus.BAD_REQUEST,
"Bad request version (%r)" % version)
return False
try:
base_version_number = version.split('/', 1)[1]
version_number = base_version_number.split(".")
if len(version_number) != 2:
raise ValueError
version_number = int(version_number[0]), int(version_number[1])
except (ValueError, IndexError):
self.send_error(
HTTPStatus.BAD_REQUEST,
"Bad request version (%r)" % version)
return False
if version_number >= (1, 1) and self.protocol_version >= "HTTP/1.1":
self.close_connection = False
if version_number >= (2, 0):
self.send_error(
HTTPStatus.HTTP_VERSION_NOT_SUPPORTED,
"Invalid HTTP Version (%s)" % base_version_number)
return False
elif len(words) == 2:
command, path = words
self.close_connection = True
if command != 'GET':
self.send_error(
HTTPStatus.BAD_REQUEST,
"Bad HTTP/0.9 request type (%r)" % command)
return False
elif not words:
return False
else:
self.send_error(
HTTPStatus.BAD_REQUEST,
"Bad request syntax (%r)" % requestline)
return False
self.command, self.path, self.request_version = command, path, version
try:
self.headers = http.client.parse_headers(self.rfile,
_class=self.MessageClass)
except http.client.LineTooLong:
self.send_error(
HTTPStatus.BAD_REQUEST,
"Line too long")
return False
except http.client.HTTPException as err:
self.send_error(
HTTPStatus.REQUEST_HEADER_FIELDS_TOO_LARGE,
"Too many headers",
str(err)
)
return False
conntype = self.headers.get('Connection', "")
if conntype.lower() == 'close':
self.close_connection = True
elif (conntype.lower() == 'keep-alive' and
self.protocol_version >= "HTTP/1.1"):
self.close_connection = False
# Examine the headers and look for an Expect directive
expect = self.headers.get('Expect', "")
if (expect.lower() == "100-continue" and
self.protocol_version >= "HTTP/1.1" and
self.request_version >= "HTTP/1.1"):
if not self.handle_expect_100():
return False
return True
def handle_expect_100(self):
'''处理请求头出现Expect: 100-continue。如果客户端等待一个100-continue的响应,我们必须给出一个100-continue或者结束响应,在实际接受数据之前。默认是直接发送100-continue响应,但是你也可以直接拒绝没有授权的请求。该方法应该返回True或者返回False并且发送错误响应"
self.send_response_only(HTTPStatus.CONTINUE)
self.end_headers()
return True
# 最后会调用finish()方法
这个处理器实现了handle方法,在处理完成一个请求之后,如果还保持连接,就会继续处理之后的请求。在处理每一个请求的时候,会首先读取请求行,获取请求方法和请求URI,并且会对发送过来的header做一个处理和监测,判断其是否可以继续处理。如果一切OK,就会分发到相应的处理方法上进行处理,比如do_GET等。在后面的SimpleHTTPRequestHandler实现了这些方法。但是基于WSGI的处理器与这种处理方法不同,它走到解析请求头之后,会开始WSGI方式去处理请求(调用app,传入environ和start_resposne,获取可迭代的返回值,然后使用write函数来输出给客户端)
WSGIRequestHandler
class WSGIRequestHandler(BaseHTTPRequestHandler, object):
def handle(self):
"""Handles a request ignoring dropped connections."""
rv = None
try:
# 调用父类的handle方法,将会调用handle_one_request,这个方法子类重写了。
rv = BaseHTTPRequestHandler.handle(self)
except (socket.error, socket.timeout) as e:
self.connection_dropped(e)
except Exception:
if self.server.ssl_context is None or not is_ssl_error():
raise
if self.server.shutdown_signal:
self.initiate_shutdown()
return rv
def handle_one_request(self):
"""Handle a single HTTP request."""
# 并没有对URI长度做限制
self.raw_requestline = self.rfile.readline()
if not self.raw_requestline:
self.close_connection = 1
# 解析请求成功,使用的是父类的方法
elif self.parse_request():
# 使用基于WSGI的方式处理请求
return self.run_wsgi()
def run_wsgi(self):
if self.headers.get('Expect', '').lower().strip() == '100-continue':
self.wfile.write(b'HTTP/1.1 100 Continue\r\n\r\n')
# 这里就是WSGI服务器创建environ的地方
self.environ = environ = self.make_environ()
headers_set = []
headers_sent = []
def write(data):
assert headers_set, 'write() before start_response'
if not headers_sent:
status, response_headers = headers_sent[:] = headers_set
try:
code, msg = status.split(None, 1)
except ValueError:
code, msg = status, ""
self.send_response(int(code), msg)
header_keys = set()
for key, value in response_headers:
self.send_header(key, value)
key = key.lower()
header_keys.add(key)
if 'content-length' not in header_keys:
self.close_connection = True
self.send_header('Connection', 'close')
if 'server' not in header_keys:
self.send_header('Server', self.version_string())
if 'date' not in header_keys:
self.send_header('Date', self.date_time_string())
self.end_headers()
assert isinstance(data, bytes), 'applications must write bytes'
self.wfile.write(data)
self.wfile.flush()
def start_response(status, response_headers, exc_info=None):
if exc_info:
try:
# 符合WSGI定义的,如果已经传递了,那么重新引发错误,使得应用中止
if headers_sent:
reraise(*exc_info)
finally:
exc_info = None
elif headers_set:
raise AssertionError('Headers already set')
headers_set[:] = [status, response_headers]
return write
def execute(app):
application_iter = app(environ, start_response)
try:
for data in application_iter:
write(data)
if not headers_sent:
write(b'')
finally:
if hasattr(application_iter, 'close'):
application_iter.close()
application_iter = None
try:
execute(self.server.app)
except (socket.error, socket.timeout) as e:
self.connection_dropped(e, environ)
except Exception:
if self.server.passthrough_errors:
raise
from werkzeug.debug.tbtools import get_current_traceback
traceback = get_current_traceback(ignore_system_exceptions=True)
try:
# if we haven't yet sent the headers but they are set
# we roll back to be able to set them again.
if not headers_sent:
del headers_set[:]
execute(InternalServerError())
except Exception:
pass
self.server.log('error', 'Error on request:\n%s',
traceback.plaintext)
def make_environ(self):
request_url = url_parse(self.path)
def shutdown_server():
self.server.shutdown_signal = True
url_scheme = self.server.ssl_context is None and 'http' or 'https'
path_info = url_unquote(request_url.path)
environ = {
'wsgi.version': (1, 0),
'wsgi.url_scheme': url_scheme,
'wsgi.input': self.rfile,
'wsgi.errors': sys.stderr,
'wsgi.multithread': self.server.multithread,
'wsgi.multiprocess': self.server.multiprocess,
'wsgi.run_once': False,
'werkzeug.server.shutdown': shutdown_server,
'SERVER_SOFTWARE': self.server_version,
'REQUEST_METHOD': self.command,
'SCRIPT_NAME': '',
'PATH_INFO': wsgi_encoding_dance(path_info),
'QUERY_STRING': wsgi_encoding_dance(request_url.query),
'CONTENT_TYPE': self.headers.get('Content-Type', ''),
'CONTENT_LENGTH': self.headers.get('Content-Length', ''),
'REMOTE_ADDR': self.address_string(),
'REMOTE_PORT': self.port_integer(),
'SERVER_NAME': self.server.server_address[0],
'SERVER_PORT': str(self.server.server_address[1]),
'SERVER_PROTOCOL': self.request_version
}
for key, value in self.headers.items():
key = 'HTTP_' + key.upper().replace('-', '_')
if key not in ('HTTP_CONTENT_TYPE', 'HTTP_CONTENT_LENGTH'):
environ[key] = value
if request_url.scheme and request_url.netloc:
environ['HTTP_HOST'] = request_url.netloc
return environ
到此,整个Flask应用的启动流程就已经梳理完了,当然这只是一个最简单的介绍,一个框架,对于把握全局有非常有用的帮助,所以细节方面都没有仔细去研究。下面是一个大致的流程图: