

前端有了模块体系之后,使得前端的项目便于组织管理。js 从以前的 CommonJS 和 AMD 规范到现在的 es6 在语言标准上实现了模块功能, css 也有 @import 语法。
相比于acorn,babylon提供更好的es6的解析支持,以及插件。
在解析过程中,我用固定的数据结构去描述一个依赖,像这样:
然后我能得到一颗依赖树,像这样的 fe-scalpel/x-scalpel
<img src="https://pic3.zhimg.com/v2-b306837ff0f63bc330eca74c29f913a2_b.png" data-rawwidth="1393" data-rawheight="599" class="origin_image zh-lightbox-thumb" width="1393" data-original="https://pic3.zhimg.com/v2-b306837ff0f63bc330eca74c29f913a2_r.png">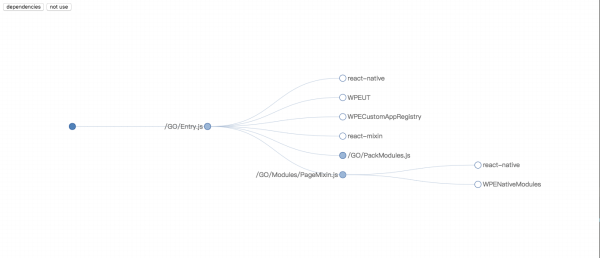
接着,我拿到项目的文件结构以及package.json里面的依赖,拿他和依赖树进行对比,找出了其中以及废弃的文件和模块。
但是这样还是太理想了
1.我只解析了js文件,这个我可以通过增加解析器来解决
2.依赖的申明可能会变化,比如一个项目用了 node-haste ,一个依赖映射工具,我只能在内部写个插件去解析支持。
到此为止,我的实现在 这里 。可以分析一些简单的 js 项目。
但是,如果我们的项目里用了类似webpack的工具,事情就变的没这么简单了。(关于 webpack 可以看下 我关于写的关于它的文章 webpack历险记 - 知乎专栏)
webpack 有自己的一套运行机制,有 loader 和 plugins ,那么类似这样的情况就变的很复杂,更好的方法似乎是,在webpack的基础上做分析,我们可以去统计在一次构建过程中的所有文件依赖。
我实现了一个 webpack 插件,在构建过程中,收集依赖,甚至我可以拿到对应的loader,这样能最大程度的统计,找出废弃的文件。
仓库在这 fe-scalpel/webpack-scalpel
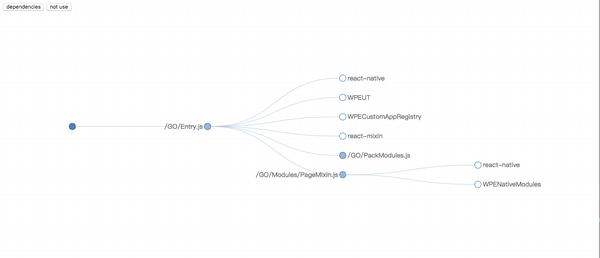
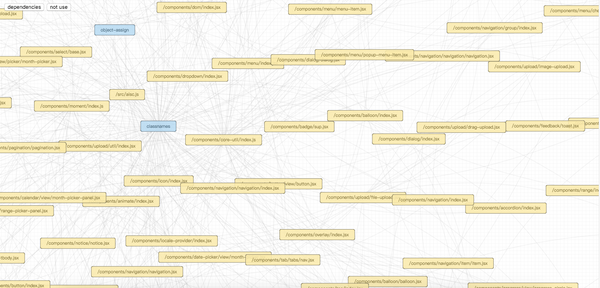
这一次,我们采用树的形式展现,而选择了图。因为我关心的只是依赖关系而已。
<img src="https://pic1.zhimg.com/v2-1deb0957e6ec734c701dfaf619a08f74_b.png" data-rawwidth="1428" data-rawheight="685" class="origin_image zh-lightbox-thumb" width="1428" data-original="https://pic1.zhimg.com/v2-1deb0957e6ec734c701dfaf619a08f74_r.png">最后,如果在这方面有好的方法或者建议欢迎在评论里留言! 最后,如果在这方面有好的方法或者建议欢迎在评论里留言!
最后,如果在这方面有好的方法或者建议欢迎在评论里留言!
我们把一个或者多个文件,实现一定功能的,封装成一个模块,让其他程序调用。
一个前端项目有了模块以及构建工具还有其他检测工具,能很大程度提高项目的健康度以及可维护性。但是项目是一直在不断更迭,新旧技术更迭,业务代码升级等,怎么样能保证我们的项目足够纯粹。
最近在思考,如何理清我们整个项目的依赖关系,找到废弃的文件或者模块依赖,帮助优化我们的项目。
我这样思考,一个程序启动都有一个或者几个入口文件,我可以从入口文件出发,解析依赖,然后生成一颗依赖树。
我需要解析js文件,找到里面的依赖,我使用了一个js解析器 babylon ,可以帮助我解析code,生成 ast 语法树, 然后使用 babylon-walk 来找到被 require 的文件和模块。
相比于acorn,babylon提供更好的es6的解析支持,以及插件。
在解析过程中,我用固定的数据结构去描述一个依赖,像这样:
{
source: '',//文件路径
type: 'file',//类型,可以是一个js文件,一个模块或者图片,css文件等
name: name,// 依赖名
children:[]//子依赖
...
}
然后我能得到一颗依赖树,像这样的 fe-scalpel/x-scalpel
<img src="https://pic3.zhimg.com/v2-b306837ff0f63bc330eca74c29f913a2_b.png" data-rawwidth="1393" data-rawheight="599" class="origin_image zh-lightbox-thumb" width="1393" data-original="https://pic3.zhimg.com/v2-b306837ff0f63bc330eca74c29f913a2_r.png">
接着,我拿到项目的文件结构以及package.json里面的依赖,拿他和依赖树进行对比,找出了其中以及废弃的文件和模块。
但是这样还是太理想了
1.我只解析了js文件,这个我可以通过增加解析器来解决
2.依赖的申明可能会变化,比如一个项目用了 node-haste ,一个依赖映射工具,我只能在内部写个插件去解析支持。
到此为止,我的实现在 这里 。可以分析一些简单的 js 项目。
但是,如果我们的项目里用了类似webpack的工具,事情就变的没这么简单了。(关于 webpack 可以看下 我关于写的关于它的文章 webpack历险记 - 知乎专栏)
webpack 有自己的一套运行机制,有 loader 和 plugins ,那么类似这样的情况就变的很复杂,更好的方法似乎是,在webpack的基础上做分析,我们可以去统计在一次构建过程中的所有文件依赖。
我实现了一个 webpack 插件,在构建过程中,收集依赖,甚至我可以拿到对应的loader,这样能最大程度的统计,找出废弃的文件。
仓库在这 fe-scalpel/webpack-scalpel
这一次,我们采用树的形式展现,而选择了图。因为我关心的只是依赖关系而已。
<img src="https://pic1.zhimg.com/v2-1deb0957e6ec734c701dfaf619a08f74_b.png" data-rawwidth="1428" data-rawheight="685" class="origin_image zh-lightbox-thumb" width="1428" data-original="https://pic1.zhimg.com/v2-1deb0957e6ec734c701dfaf619a08f74_r.png">最后,如果在这方面有好的方法或者建议欢迎在评论里留言!
 最后,如果在这方面有好的方法或者建议欢迎在评论里留言!
最后,如果在这方面有好的方法或者建议欢迎在评论里留言!