

前言
网络编程中我们接触得比较多的是socket api和epoll模型,对于系统内核和网卡驱动接触得比较少,一方面可能我们的系统没有需要深度调优的需求,另一方面网络编程涉及到硬件,驱动,内核,虚拟化等复杂的知识,使人望而却步。网络上网卡收包相关的资料也比较多,但是比较分散,在此梳理了网卡收包的流程,分享给大家,希望对大家有帮助,文中引用了一些同事的图表和摘选了网上资料,在文章最后给出了原始的链接,感谢这些作者的分享。
1.整体流程
网卡收包从整体上是网线中的高低电平转换到网卡FIFO存储再拷贝到系统主内存(DDR3)的过程,其中涉及到网卡控制器,CPU,DMA,驱动程序,在OSI模型中属于物理层和链路层,如下图所示。
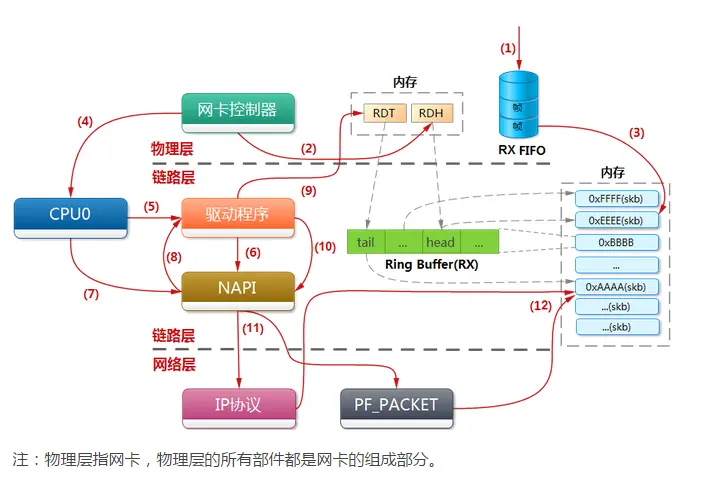
2.关键数据结构
在内核中网络数据流涉及到的代码比较复杂,见图1(原图在附件中),其中有3个数据结构在网卡收包的流程中是最主要的角色,它们是:sk_buff,softnet_data,net_device。
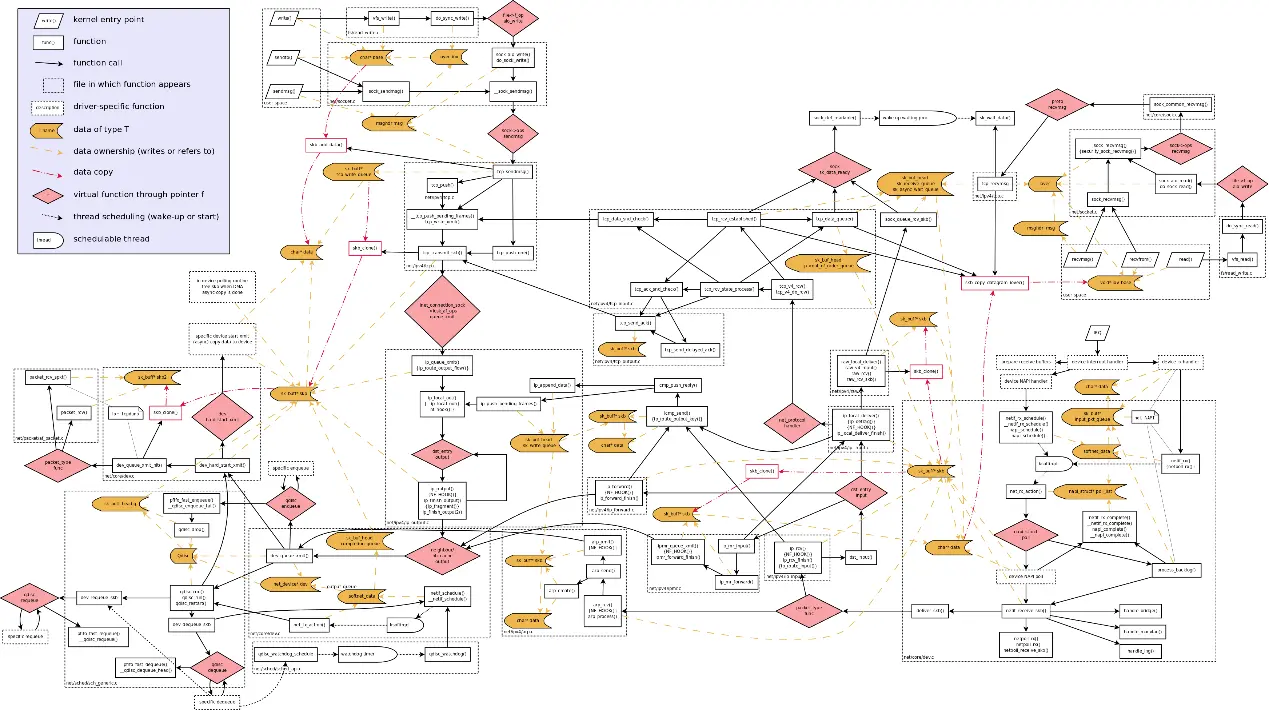
图1内核网络数据流
sk_buff
sk_buff结构是Linux网络模块中最重要的数据结构之一。sk_buff可以在不同的网络协议层之间传递,为了适配不同的协议,里面的大多数成员都是指针,还有一些union,其中data指针和len会在不同的协议层中发生改变,在收包流程中,即数据向上层传递时,下层的首部就不再需要了。图2即演示了数据包发送时指针和len的变化情况。(linux源码不同的版本有些差别,下面的截图来自linux 2.6.20)。

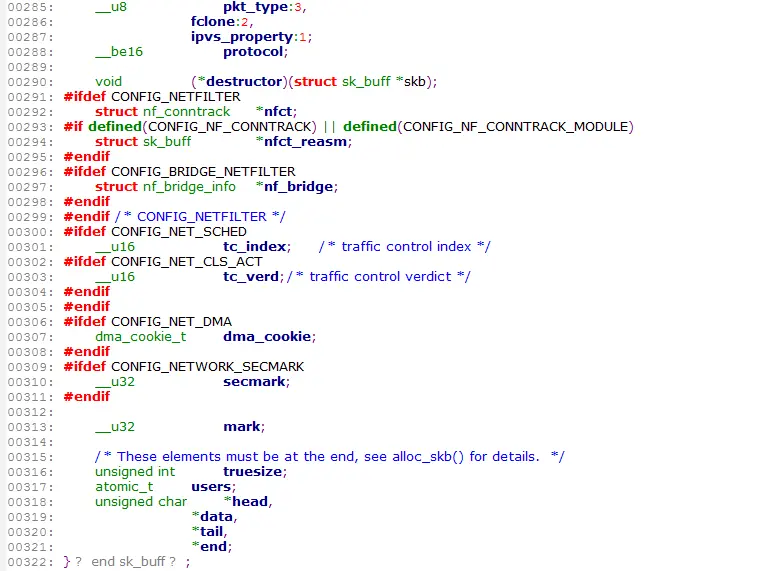
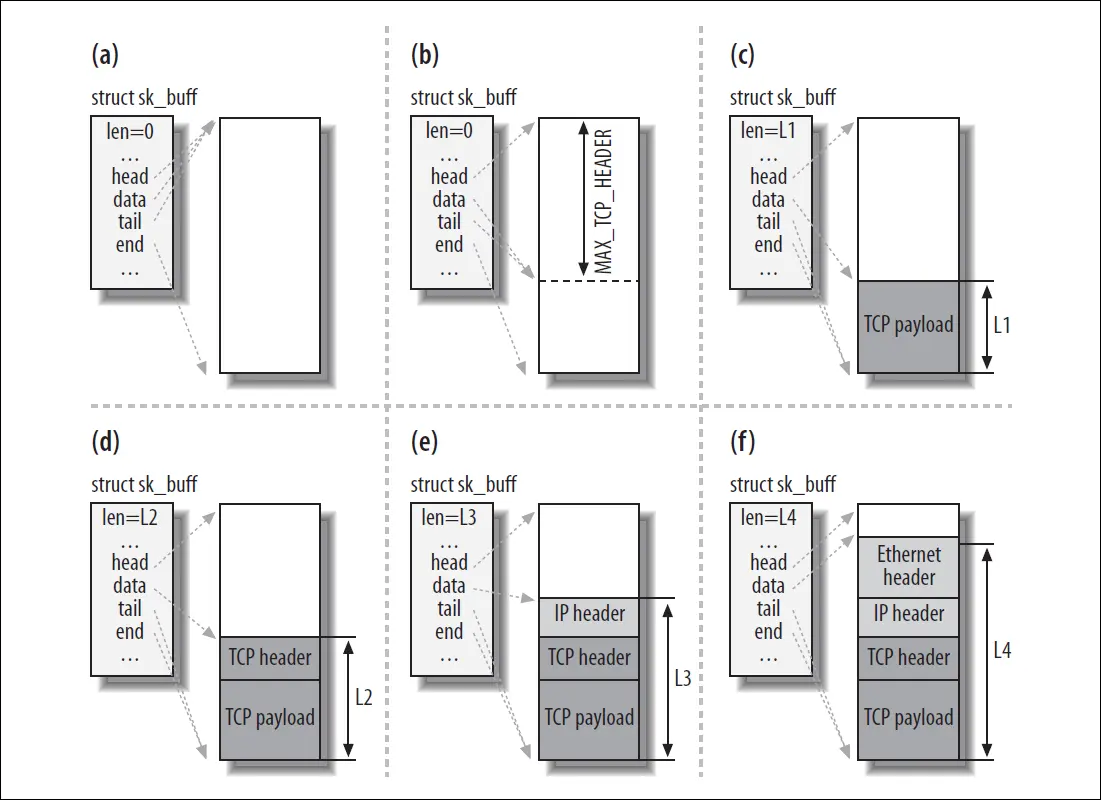
图2 sk_buff在不同协议层传递时,data指针的变化示例
softnet_data
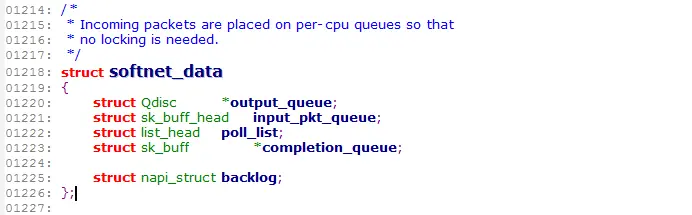
softnet_data 结构内的字段就是 NIC 和网络层之间处理队列,这个结构是全局的,每个cpu一个,它从 NIC中断和 POLL 方法之间传递数据信息。图3说明了softnet_data中的变量的作用。
net_device


net_device中poll方法即在NAPI回调的收包函数。
net_device代表的是一种网络设备,既可以是物理网卡,也可以是虚拟网卡。在sk_buff中有一个net_device * dev变量,这个变量会随着sk_buff的流向而改变。在网络设备驱动初始化时,会分配接收sk_buff缓存队列,这个dev指针会指向收到数据包的网络设备。当原始网络设备接收到报文后,会根据某种算法选择某个合适的虚拟网络设备,并将dev指针修改为指向这个虚拟设备的net_device结构。
3.网络收包原理
本节主要引用网络上的文章,在关键的地方加了一些备注,腾讯公司内部主要使用Intel 82576网卡和Intel igb驱动,和下面的网卡和驱动不一样,实际上原理是一样的,只是一些函数命名和处理的细节不一样,并不影响理解。
网络驱动收包大致有3种情况:
no NAPI:
mac每收到一个以太网包,都会产生一个接收中断给cpu,即完全靠中断方式来收包
缺点是当网络流量很大时,cpu大部分时间都耗在了处理mac的中断。
netpoll:
在网络和I/O子系统尚不能完整可用时,模拟了来自指定设备的中断,即轮询收包。
缺点是实时性差
NAPI:
采用中断 + 轮询的方式:mac收到一个包来后会产生接收中断,但是马上关闭。
直到收够了netdev_max_backlog个包(默认300),或者收完mac上所有包后,才再打开接收中断
通过sysctl来修改 net.core.netdev_max_backlog
或者通过proc修改 /proc/sys/net/core/netdev_max_backlog
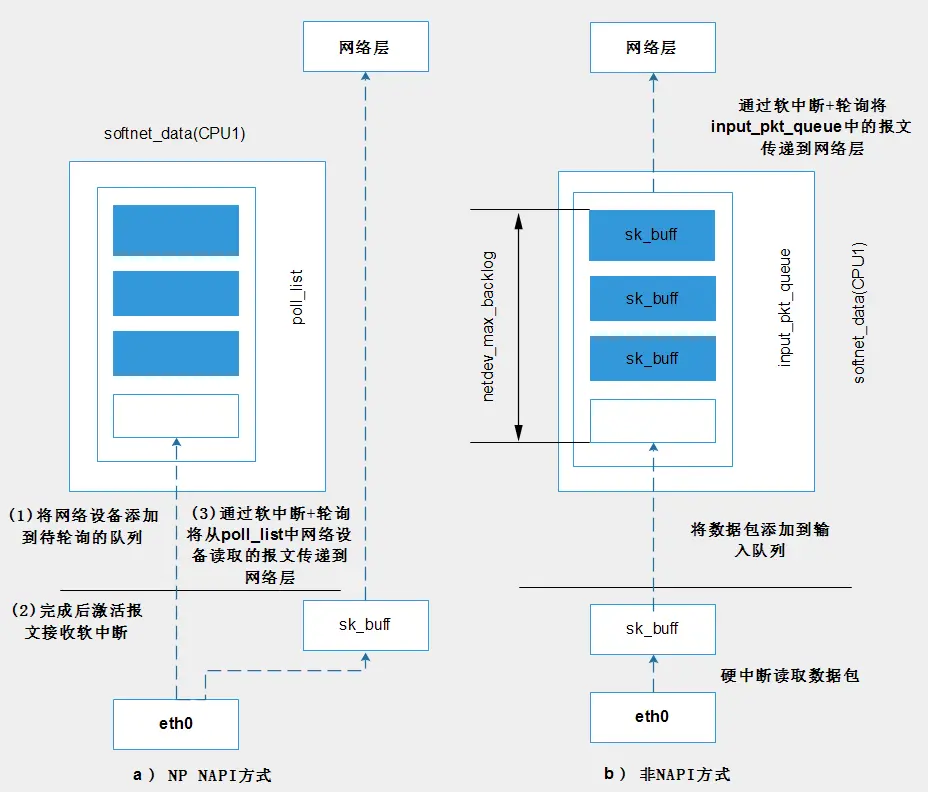
图3 softnet_data与接口层和网络层之间的关系
下面只写内核配置成使用NAPI的情况,只写TSEC驱动。内核版本 linux 2.6.24。
NAPI相关数据结构
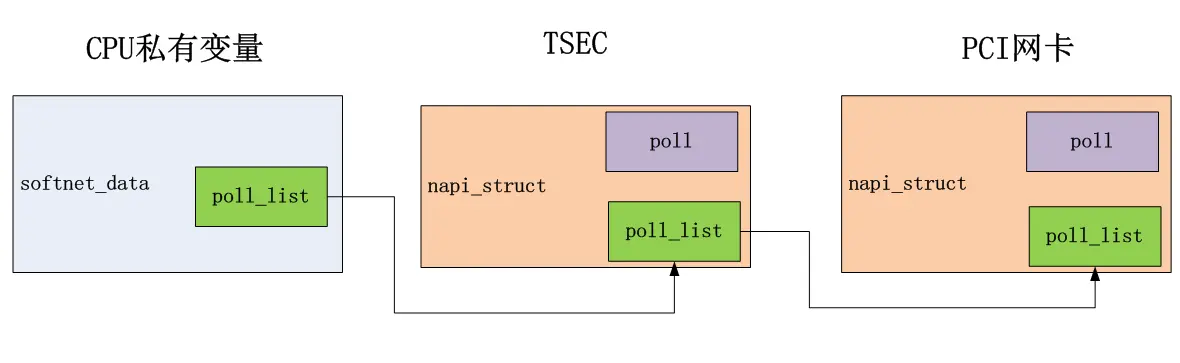
每个网络设备(MAC层)都有自己的net_device数据结构,这个结构上有napi_struct。每当收到数据包时,网络设备驱动会把自己的napi_struct挂到CPU私有变量上。这样在软中断时,net_rx_action会遍历cpu私有变量的poll_list,执行上面所挂的napi_struct结构的poll钩子函数,将数据包从驱动传到网络协议栈。
内核启动时的准备工作
3.1 初始化网络相关的全局数据结构,并挂载处理网络相关软中断的钩子函数
start_kernel()
--> rest_init()
--> do_basic_setup()
--> do_initcall
-->net_dev_init
__init net_dev_init(){
//每个CPU都有一个CPU私有变量 _get_cpu_var(softnet_data)
//_get_cpu_var(softnet_data).poll_list很重要,软中断中需要遍历它的
for_each_possible_cpu(i) {
struct softnet_data *queue;
queue = &per_cpu(softnet_data, i);
skb_queue_head_init(&queue->input_pkt_queue);
queue->completion_queue = NULL;
INIT_LIST_HEAD(&queue->poll_list);
queue->backlog.poll = process_backlog;
queue->backlog.weight = weight_p;
}
//在软中断上挂网络发送handler
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
//在软中断上挂网络接收handler
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
}softirq
中断处理“下半部”机制
中断服务程序一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU就不能及时响应其他的中断请求,从而造成中断的丢失。
因此,Linux内核的目标就是尽可能快的处理完中断请求,尽其所能把更多的处理向后推迟。例如,假设一个数据块已经达到了网线,当中断控制器接受到这个中断请求信号时,Linux内核只是简单地标志数据到来了,然后让处理器恢复到它以前运行的状态,其余的处理稍后再进行(如把数据移入一个缓冲区,接受数据的进程就可以在缓冲区找到数据)。
因此,内核把中断处理分为两部分:上半部(top-half)和下半部(bottom-half),上半部(就是中断服务程序)内核立即执行,而下半部(就是一些内核函数)留着稍后处理。
2.6内核中的“下半部”处理机制:
1) 软中断请求(softirq)机制(注意不要和进程间通信的signal混淆)
2) 小任务(tasklet)机制
3) 工作队列机制
我们可以通过top命令查看softirq占用cpu的情况:
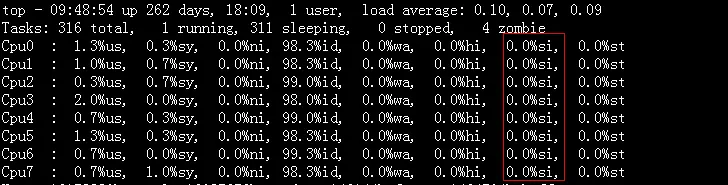
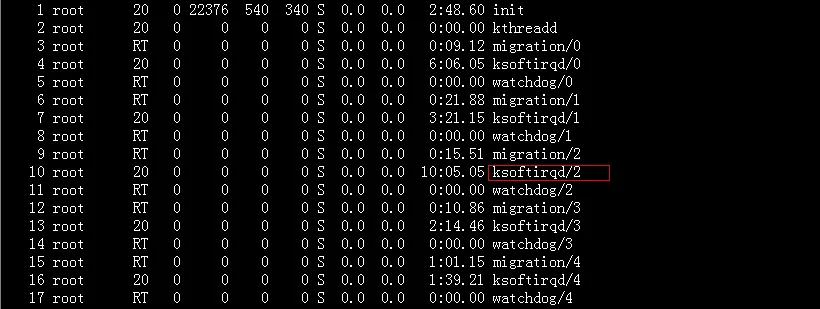
softirq实际上也是一种注册回调的机制,ps –elf 可以看到注册的函数由一个守护进程(ksoftirgd)专门来处理,而且是每个cpu一个守护进程。
3.2 加载网络设备的驱动
NOTE:这里的网络设备是指MAC层的网络设备,即TSEC和PCI网卡(bcm5461是phy)在网络设备驱动中创建net_device数据结构,并初始化其钩子函数 open(),close() 等挂载TSEC的驱动的入口函数是 gfar_probe
// 平台设备 TSEC 的数据结构
static struct platform_driver gfar_driver = {
.probe = gfar_probe,
.remove = gfar_remove,
.driver = {
.name = "fsl-gianfar",
},
};
int gfar_probe(struct platform_device *pdev)
{
dev = alloc_etherdev(sizeof (*priv)); // 创建net_device数据结构
dev->open = gfar_enet_open;
dev->hard_start_xmit = gfar_start_xmit;
dev->tx_timeout = gfar_timeout;
dev->watchdog_timeo = TX_TIMEOUT;
#ifdef CONFIG_GFAR_NAPI
netif_napi_add(dev, &priv->napi,gfar_poll,GFAR_DEV_WEIGHT); //软中断里会调用poll钩子函数
#endif
#ifdef CONFIG_NET_POLL_CONTROLLER
dev->poll_controller = gfar_netpoll;
#endif
dev->stop = gfar_close;
dev->change_mtu = gfar_change_mtu;
dev->mtu = 1500;
dev->set_multicast_list = gfar_set_multi;
dev->set_mac_address = gfar_set_mac_address;
dev->ethtool_ops = &gfar_ethtool_ops;
}3.3启用网络设备
3.3.1 用户调用ifconfig等程序,然后通过ioctl系统调用进入内核
socket的ioctl()系统调用
--> sock_ioctl()
--> dev_ioctl() //判断SIOCSIFFLAGS
--> __dev_get_by_name(net, ifr->ifr_name) //根据名字选net_device
--> dev_change_flags() //判断IFF_UP
--> dev_open(net_device) //调用open钩子函数对于TSEC来说,挂的钩子函数是 gfar_enet_open(net_device)
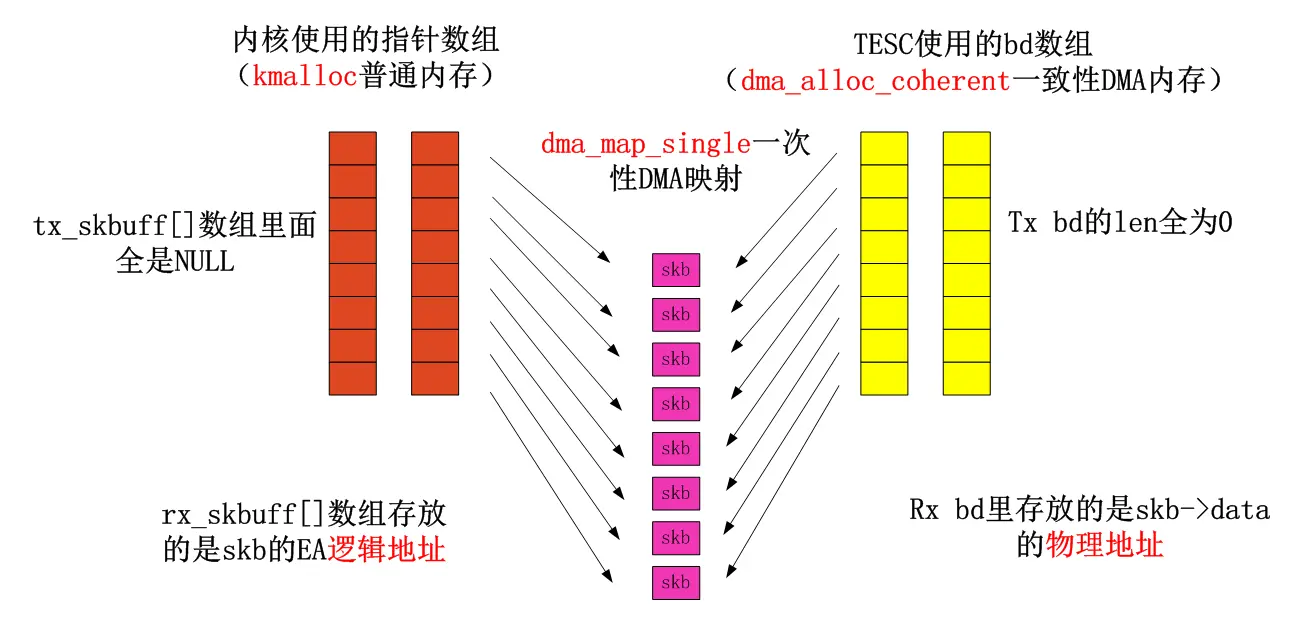
3.3.2 在网络设备的open钩子函数里,分配接收bd,挂中断ISR(包括rx、tx、err),对于TSEC来说
gfar_enet_open
-->给Rx Tx Bd 分配一致性DMA内存
-->把Rx Bd的“EA地址”赋给数据结构,物理地址赋给TSEC寄存器
-->把Tx Bd的“EA地址”赋给数据结构,物理地址赋给TSEC寄存器
-->给 tx_skbuff 指针数组分配内存,并初始化为NULL
-->给 rx_skbuff 指针数组分配内存,并初始化为NULL
-->初始化Tx Bd
-->初始化Rx Bd,提前分配存储以太网包的skb,这里使用的是一次性dma映射
(注意:`#define DEFAULT_RX_BUFFER_SIZE 1536`保证了skb能存一个以太网包) rxbdp = priv->rx_bd_base;
for (i = 0; i < priv->rx_ring_size; i++) {
struct sk_buff *skb = NULL;
rxbdp->status = 0;
//这里真正分配skb,并且初始化rxbpd->bufPtr, rxbdpd->length
skb = gfar_new_skb(dev, rxbdp);
priv->rx_skbuff[i] = skb;
rxbdp++;
}
rxbdp--;
rxbdp->status |= RXBD_WRAP; // 给最后一个bd设置标记WRAP标记-->注册TSEC相关的中断handler:错误,接收,发送 request_irq(priv->interruptError, gfar_error, 0, "enet_error", dev)
request_irq(priv->interruptTransmit, gfar_transmit, 0, "enet_tx", dev)//包发送完
request_irq(priv->interruptReceive, gfar_receive, 0, "enet_rx", dev) //包接收完
-->gfar_start(net_device)
// 使能Rx、Tx
// 开启TSEC的 DMA 寄存器
// Mask 掉我们不关心的中断event最终,TSEC相关的Bd等数据结构应该是下面这个样子的
3.4中断里接收以太网包
TSEC的RX已经使能了,网络数据包进入内存的流程为:
网线 --> Rj45网口 --> MDI 差分线
--> bcm5461(PHY芯片进行数模转换) --> MII总线
--> TSEC的DMA Engine 会自动检查下一个可用的Rx bd
-->把网络数据包 DMA 到 Rx bd 所指向的内存,即skb->data
接收到一个完整的以太网数据包后,TSEC会根据event mask触发一个 Rx 外部中断。
cpu保存现场,根据中断向量,开始执行外部中断处理函数do_IRQ()
do_IRQ 伪代码
上半部处理硬中断
查看中断源寄存器,得知是网络外设产生了外部中断
执行网络设备的rx中断handler(设备不同,函数不同,但流程类似,TSEC是gfar_receive)
- mask 掉 rx event,再来数据包就不会产生rx中断
- 给napi_struct.state加上 NAPI_STATE_SCHED 状态
- 挂网络设备自己的napi_struct结构到cpu私有变量_get_cpu_var(softnet_data).poll_list
- 触发网络接收软中断( __raise_softirq_irqoff(NET_RX_SOFTIRQ); ——> wakeup_softirqd() )
下半部处理软中断
依次执行所有软中断handler,包括timer,tasklet等等
执行网络接收的软中断handler net_rx_action - 遍历cpu私有变量_get_cpu_var(softnet_data).poll_list
- 取出poll_list上面挂的napi_struct 结构,执行钩子函数napi_struct.poll()
(设备不同,钩子函数不同,流程类似,TSEC是gfar_poll - 若poll钩子函数处理完所有包,则打开rx event mask,再来数据包的话会产生rx中断
- 调用napi_complete(napi_struct *n)
- 把napi_struct 结构从_get_cpu_var(softnet_data).poll_list 上移走,同时去掉 napi_struct.state 的 NAPI_STATE_SCHED 状态
3.4.1 TSEC的接收中断处理函数
3.4.2 网络接收软中断net_rx_actiongfar_receive{ #ifdef CONFIG_GFAR_NAPI // test_and_set当前net_device的napi_struct.state 为 NAPI_STATE_SCHED // 在软中断里调用 net_rx_action 会检查状态 napi_struct.state if (netif_rx_schedule_prep(dev, &priv->napi)) { tempval = gfar_read(&priv->regs->imask); tempval &= IMASK_RX_DISABLED; //mask掉rx,不再产生rx中断 gfar_write(&priv->regs->imask, tempval); // 将当前net_device的 napi_struct.poll_list 挂到 // CPU私有变量__get_cpu_var(softnet_data).poll_list 上,并触发软中断 // 所以,在软中断中调用 net_rx_action 的时候,就会执行当前net_device的 // napi_struct.poll()钩子函数,即 gfar_poll() __netif_rx_schedule(dev, &priv->napi); } #else gfar_clean_rx_ring(dev, priv->rx_ring_size); #endif }
net_rx_action(){
struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
//通过 napi_struct.poll_list,将N多个 napi_struct 链接到一条链上
//通过 CPU私有变量,我们找到了链头,然后开始遍历这个链
int budget = netdev_budget; //这个值就是 net.core.netdev_max_backlog,通过sysctl来修改
while (!list_empty(list)) {
struct napi_struct *n;
int work, weight;
local_irq_enable();
//从链上取一个 napi_struct 结构(接收中断处理函数里加到链表上的,如gfar_receive)
n = list_entry(list->next, struct napi_struct, poll_list);
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) //检查状态标记,此标记在接收中断里加上的
//使用NAPI的话,使用的是网络设备自己的napi_struct.poll
//对于TSEC是,是gfar_poll
work = n->poll(n, weight);
WARN_ON_ONCE(work > weight);
budget -= work;
local_irq_disable();
if (unlikely(work == weight)) {
if (unlikely(napi_disable_pending(n)))
//操作napi_struct,把去掉NAPI_STATE_SCHED状态,从链表中删去
__napi_complete(n);
else
list_move_tail(&n->poll_list, list);
}
netpoll_poll_unlock(have);
}
out:
local_irq_enable();
}
static int gfar_poll(struct napi_struct *napi, int budget){
struct gfar_private *priv = container_of(napi, struct gfar_private, napi);
struct net_device *dev = priv->dev; //TSEC对应的网络设备
int howmany;
//根据dev的rx bd,获取skb并送入协议栈,返回处理的skb的个数,即以太网包的个数
howmany = gfar_clean_rx_ring(dev, budget);
// 下面这个判断比较有讲究的
// 收到的包的个数小于budget,代表我们在一个软中断里就全处理完了,所以打开 rx中断
// 要是收到的包的个数大于budget,表示一个软中断里处理不完所有包,那就不打开rx 中断,
// 待到下一个软中断里再接着处理,直到把所有包处理完(即howmany<budget),再打开rx 中断
if (howmany < budget) {
netif_rx_complete(dev, napi);
gfar_write(&priv->regs->rstat, RSTAT_CLEAR_RHALT);
//打开 rx 中断,rx 中断是在gfar_receive()中被关闭的
gfar_write(&priv->regs->imask, IMASK_DEFAULT);
}
return howmany;
}gfar_clean_rx_ring(dev, budget){
bdp = priv->cur_rx;
while (!((bdp->status & RXBD_EMPTY) || (--rx_work_limit < 0))) {
rmb();
skb = priv->rx_skbuff[priv->skb_currx]; //从rx_skbugg[]中获取skb
howmany++;
dev->stats.rx_packets++;
pkt_len = bdp->length - 4; //从length中去掉以太网包的FCS长度
gfar_process_frame(dev, skb, pkt_len);
dev->stats.rx_bytes += pkt_len;
dev->last_rx = jiffies;
bdp->status &= ~RXBD_STATS; //清rx bd的状态
skb = gfar_new_skb(dev, bdp); // Add another skb for the future
priv->rx_skbuff[priv->skb_currx] = skb;
if (bdp->status & RXBD_WRAP) //更新指向bd的指针
bdp = priv->rx_bd_base; //bd有WARP标记,说明是最后一个bd了,需要“绕回来”
else
bdp++;
priv->skb_currx = (priv->skb_currx + 1) & RX_RING_MOD_MASK(priv->rx_ring_size);
}
priv->cur_rx = bdp; /* Update the current rxbd pointer to be the next one */
return howmany;
}
gfar_process_frame()
-->RECEIVE(skb) //调用netif_receive_skb(skb)进入协议栈
#ifdef CONFIG_GFAR_NAPI
#define RECEIVE(x) netif_receive_skb(x)
#else
#define RECEIVE(x) netif_rx(x)
#endif在软中断中使用NAPI
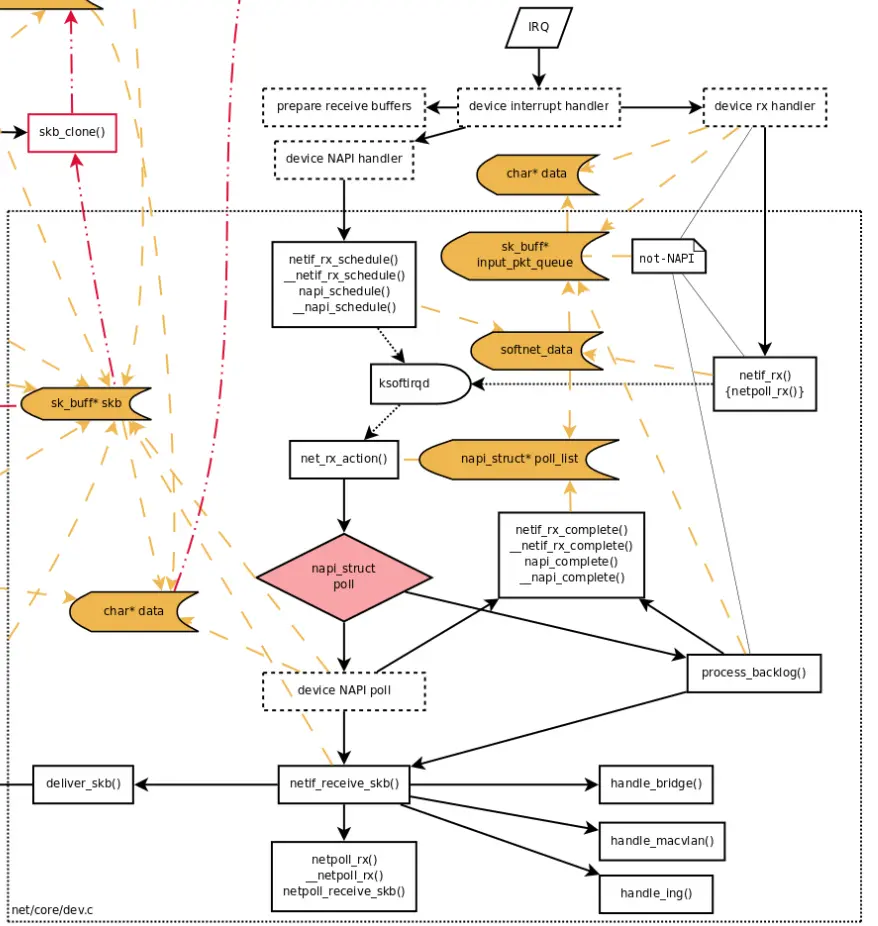
上面net_rx_action的主要流程如图4所示,执行一次网络软中断过程中,网卡本身的Rx中断已经关闭了,即不会产生新的接收中断了。local_irq_enable和local_irq_disable设置的是cpu是否接收中断。进入网络软中断net_rx_action的时候,会初始一个budget(预算),即最多处理的网络包个数,如果有多个网卡(放在poll_list里),是共享该budget,同时每个网卡也一个权重weight或者说是配额quota,一个网卡处理完输入队列里包后有两种情况,一次收到的包很多,quota用完了,则把收包的poll虚函数又挂到poll_list队尾,重新设置一下quota值,等待while轮询;另外一种情况是,收到的包不多,quota没有用完,表示网卡比较空闲,则把自己从poll_list摘除,退出轮询。整个net_rx_action退出的情况有两种:budget全部用完了或者是时间超时了。
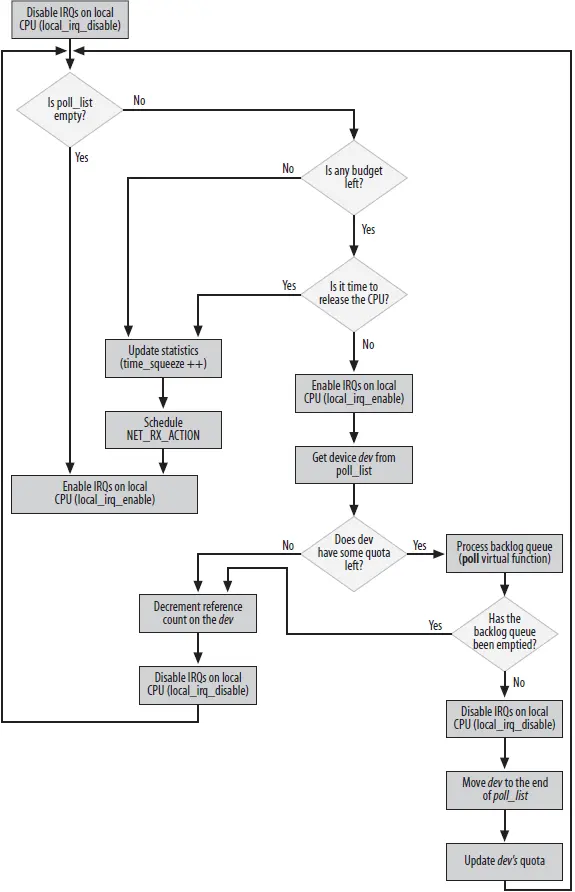
图4net_rx_action主要执行流程
3.5 DMA 8237A
在网卡收包中涉及到DMA的操作,DMA的主要作用是让外设间(如网卡和主内存)传输数据而不需要CPU的参与(即不需要CPU使用专门的IO指令来拷贝数据),下面简单介绍一下DMA的原理,如图5所示。
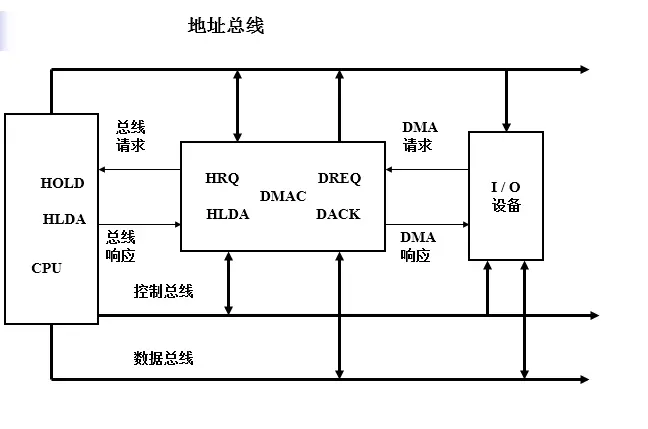
图5 DMA系统组成
网卡采用DMA方式(DMA控制器一般在系统板上,有的网卡也内置DMA控制器),ISR通过CPU对DMA控制器编程(由DMA的驱动完成,此时DMA相当于一个普通的外设,编程主要指设置DMA控制器的寄存器),DMA控制器收到ISR请求后,向主CPU发出总线HOLD请求,获取CPU应答后便向LAN发出DMA应答并接管总线,同时开始网卡缓冲区与内存之间的数据传输,这个时候CPU可以继续执行其他的指令,当DMA操作完成后,DMA则释放对总线的控制权。
4.网卡多队列
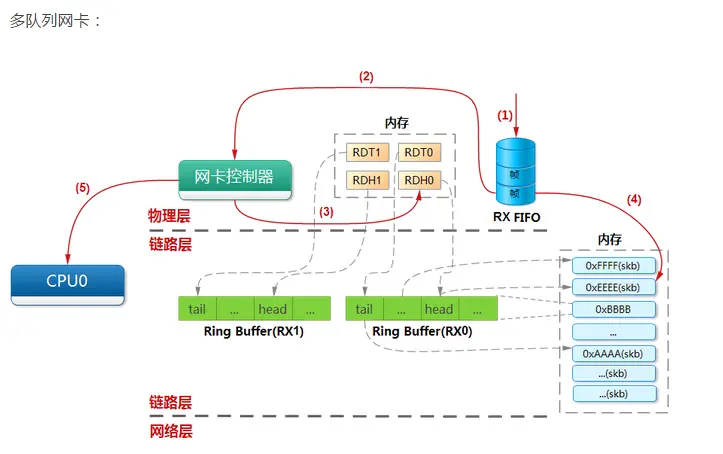
网卡多队列是硬件的一种特性,同时也需要内核支持,腾讯公司使用的Intel 82576是支持网卡多队列的,而且内核版本要大于2.6.20。对于单队列的网卡,只能产生一个中断信号,并且只能由一个cpu来处理,这样会导致多核系统中一个核(默认是cpu0)负载很高。网卡多队列在网卡的内部维持多个收发队列,并产生多个中断信号使不同的cpu都能处理网卡收到的包,从而提升了性能,如图6所示。
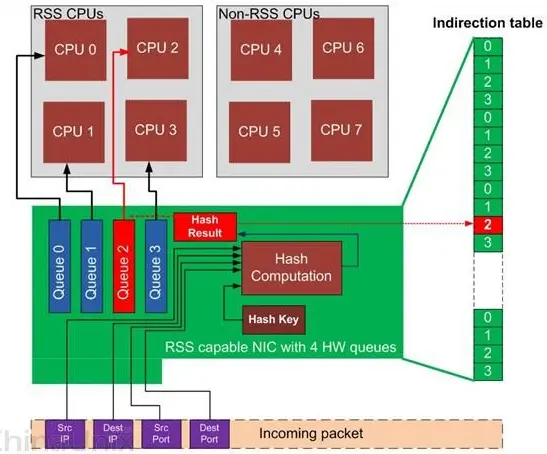
图6多队列网卡工作收包流程示意图
MSI-X :一个设备可以产生多个中断,如下图中的54-61号中断eth1-TxRx-[0-7],实际是eth1网卡占用的中断号。
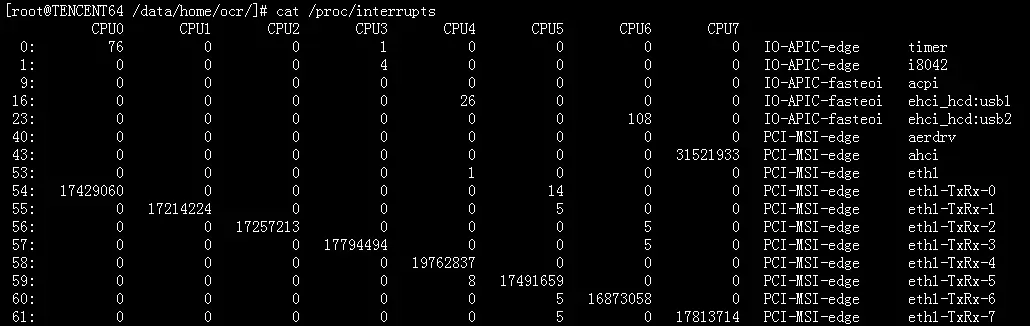
CPU 亲和性:每个中断号配置只有一个cpu进行处理,其中的值:01,02,04等为16进制,相应bit为1的值代码cpu的编号。

5.I/O虚拟化SR-IOV
服务器虚拟化技术在分布式系统中很常见,它能提高设备利用率和运营效率。服务器虚拟化包括处理器虚拟化,内存虚拟化和I/0设备的虚拟化,与网络有关的虚拟化属于I/0虚拟化,I/0设备虚拟化的作用是单个I/O设备可以被多个虚拟机共享使用。对于客户机操作系统中的应用程序来说,它发起 I/O 操作的流程和在真实硬件平台上的操作系统是一样的,整个 I/O 流程有所不同的在于设备驱动访问硬件这个部分。I/0虚拟化经过多年的发展,主要模型如表1所示,早期的设备仿真如图7所示,可以看到网络数据包从物理网卡到虚拟机中的进程需要经过很多额外的处理,效率很低。SR-IOV则直接从硬件上支持虚拟化,如图8所示,设备划分为一个物理功能单元PF(Physical Functions)和多个虚拟功能单元 VF(Virtual Function),每个虚拟功能单元都可以作为一个轻量级的 I/O 设备供虚拟机使用,这样一个设备就可以同时被分配给多个虚拟机,解决了因设备数量限制给虚拟化系统带来的可扩展性差的问题。每个 VF 都有一个唯一的 RID(Requester Identifier,请求标识号)和收发数据包的关键资源,如发送队列、接收队列、DMA 通道等,因此每个 VF 都具有独立收发数据包的功能。所有的 VF 共享主要的设备资源,如数据链路层的处理和报文分类。

表1几种I/0虚拟化计算对比
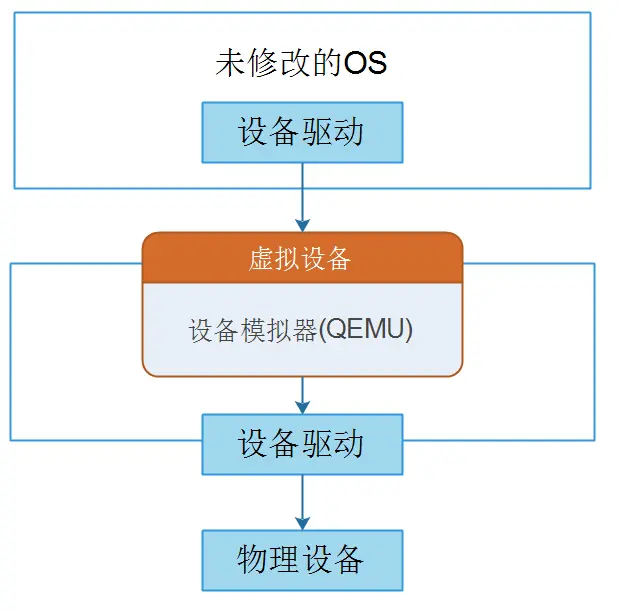
图7设备仿真
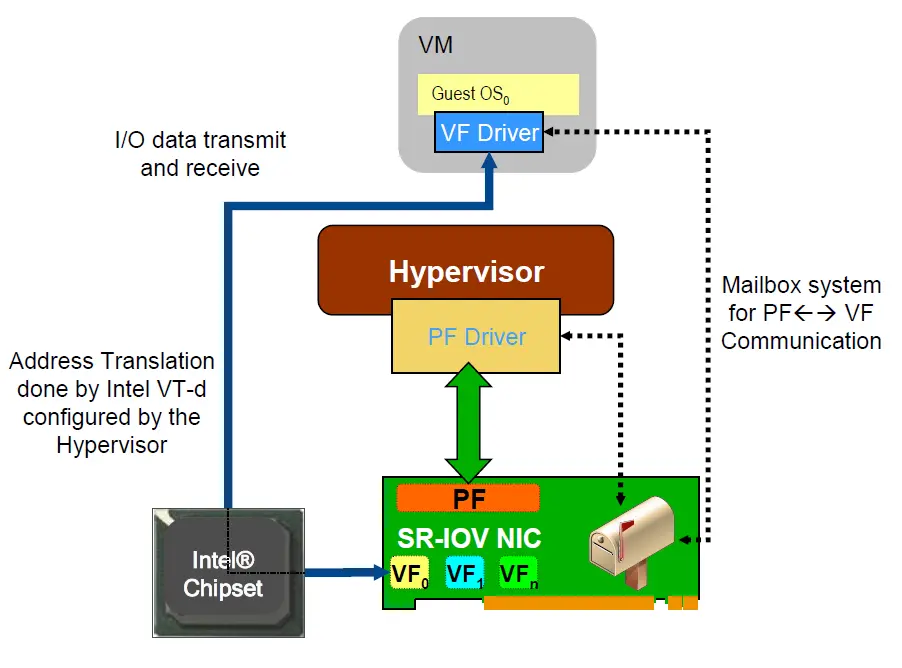
图8支持SR-IOV的设备结构
SR-IOV需要网卡支持:
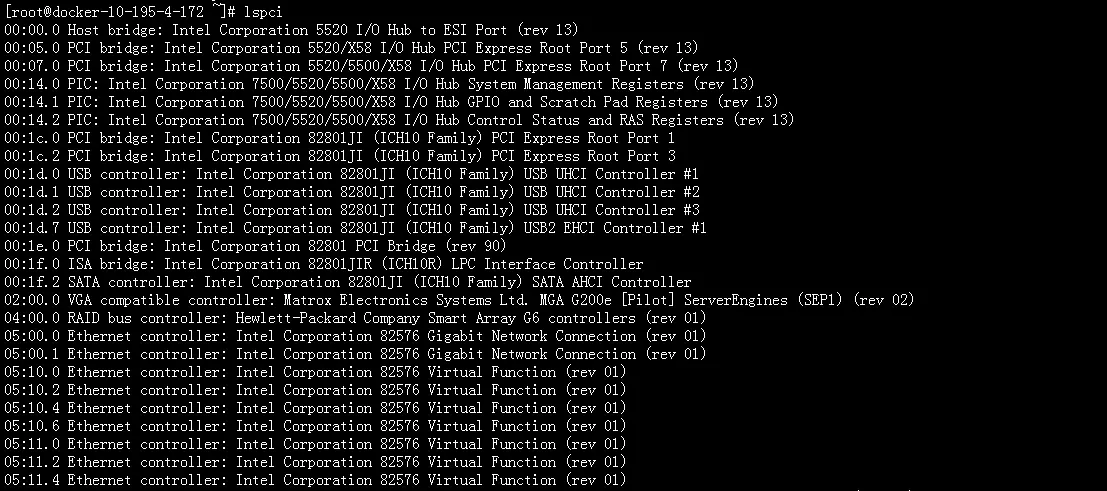
需要有专门的驱动来支持:
VF的驱动实际上和普通的网卡差不多,最后都会执行到netif_receive_skb中,然后将接收到的包发给它的vlan虚拟子设备进行处理。
docker中使用SR-IOV
激活VF
#echo "options igb max_vfs=7" >>/etc/modprobe.d/igb.conf#reboot
设置VF的VLAN#ip link set eth1 vf 0 vlan 12
将VF移到container network namespace#ip link set eth4 netns $pid#ip netns exec $pid ip link set dev eth4 name eth1#ip netns exec $pid ip link set dev eth1 up
In container:
设置IP#ip addr add 10.217.121.107/21 dev eth1
网关#ip route add default via 10.217.120.1
6.参考资料
- Linux内核源码剖析——TCP/IP实现,上册
- Understanding Linux Network Internals
- 基于SR-IOV技术的网卡虚拟化研究和实现
- 82576 sr-iov driver companion guide
- 网卡工作原理及高并发下的调优
- 多队列网卡简介
- Linux内核NAPI机制分析
- 网络数据包收发流程(一):从驱动到协议栈
- 中断处理“下半部”机制
- Linux 上的基础网络设备详解
- DMA operating system
