

一.简单动态字符串(sds)
动态,即灵活性,可变化,主要是针对final String 和char[]而言,我们先看下它的数据结构
struct sdshdr{
char [] buf; //字节数组,用来保存字符串
int len;// buf中已使用的长度,不包括\0,等于sds所保存的字符串长度
int free;// 记录buf数组剩余空间的长度
}
假设现在又sds为buf分配5个字符,5个空余空间,则可用下图表示
<img src="https://pic3.zhimg.com/v2-6efe59669eedc205431b26268f0eed22_b.png" data-rawwidth="800" data-rawheight="228" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic3.zhimg.com/v2-6efe59669eedc205431b26268f0eed22_r.png">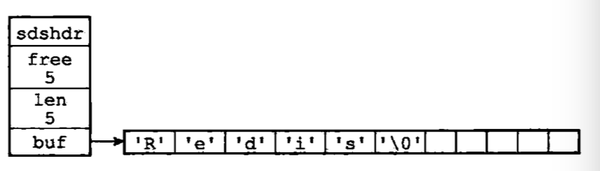
那么,我们谈谈这样设计的好处:
- 常数时间获取字符串长度
由于它底层保存了len,因此可以直接获取sds字符串长度,所以它是以O(1)的时间复杂度获取字符串长度;
2. 避免缓冲区溢出
它与char[]数组长度固定不同的是:它每次在插入元素前会先检查sds空间是否满足,若不满足,则做适当的扩充.因此避免了缓冲区溢出的可能性;
此外,在C字符串中,字符串形式固定为"sdds\0",即保存了n个字符的字符串是通过char[n+1]实现的,因此c字符串的长度和底层char数组是固定的,因为每次插入或删除字符,都要重新分配新的内存,来保存新值,因此它是一个很耗时的操作,那么sds是怎么优化的呢?
3. 减少了连续内存重分配的次数
sds采用空间预分配和惰性空间释放两种策略减少了内存重分配的次数
- 空间预分配:用于优化SDS的字符串增长操作,当sds的api对sds添加内容时,程序不仅会为sds分配修改后所需的空间,还会分配额外的空间(free),具体策略如下
- 如果现有空间足够存放修改后内容,则不进行扩展,直接插入
- 如果现有空间不足以存放修改后内容,且在修改后sds的len小于1MB,则扩展后的空间len==free,比如修改后空间为15byte,那么分配的空间为31byte:15byte(len)+15byte(free)+1byte
- 如果不足以存放修改后内容,且修改后len>1MB,则分配1MB的未使用时间.比如修改后为20MB,则新空间为20MB(len)+1MB(free)+1byte.
在后两种情况后,加入我们再插入abc,因为已有足够空间,所以不需要再重新分配内存,因此,空间预分配策略减少了增长字符串时导致的内存重分配次数.
- 惰性空间释放:用于优化SDS缩减操作.当api对sds进行缩短操作后,程序不会释放缩短后空余出的空间,而是使用free属性把他们记录下来,当我们插入的时候就可以减少内存重分配了.
当然,你也不需要担心,我们以后不添加内容时,造成的内存泄露,因为sds提供了释放空间的API
4. 二进制安全
C字符串的字符必须某种编码(比如ASCII),并且除末尾外,其余地方不能出现空字符串\0,否则会被提前结束,(\0是c字符串的结束标识符),比如acvf\0sdsdsd\0,只能识别到acvf.
而这个特性注定它只能保存文本数据,而不能保存图片,音频等二进制数据.为了确保redis适用于不同的应用场景,SDS的API都是二进制安全的,即所有的SDS都会以处理二进制方式来处理SDS中buf数组内容,程序不会对它的内容进行限制和过滤,以保证它的原有状态.这也是把buf设计成字节数组的原因.举个例子,由于sds是根据len属性来判断字符串的结束,所以对下图数据我们将读取到redis\0cluster
<img src="https://pic3.zhimg.com/v2-6a2f42808be623d14734f7262bf9d4ce_b.png" data-rawwidth="1130" data-rawheight="252" class="origin_image zh-lightbox-thumb" width="1130" data-original="https://pic3.zhimg.com/v2-6a2f42808be623d14734f7262bf9d4ce_r.png">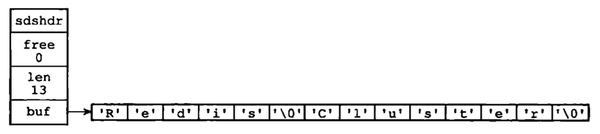
5. 兼容部分C字符串函数
由于SDS的buf数组以\0结尾,符合c字符串特征,因此,它可以使用C字符串的一些api
二.链表
<img src="https://pic3.zhimg.com/v2-e03032e7bd4be0ebb06f4c30cdb4c80a_b.png" data-rawwidth="992" data-rawheight="318" class="origin_image zh-lightbox-thumb" width="992" data-original="https://pic3.zhimg.com/v2-e03032e7bd4be0ebb06f4c30cdb4c80a_r.png">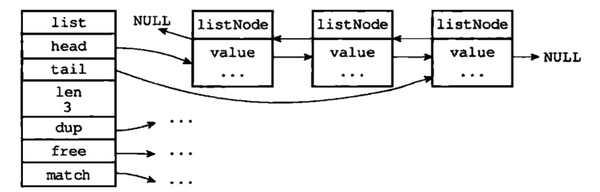
struct listNode{
struct listNode *prev//前置节点
struct listNode *next//后置节点
void *value //节点值
}listNode;
struct list{
listNode *head;
listNode *tail;
unsigned long len//常数时间获取链表长度
....
}list;
链表结构为双向无环结构(tail.next==null,header.pre==null),可直接获取节点个数,它被广泛用在redis的各种功能,如列表键,发布和订阅,慢查询,监视器等
三.字典(dict)
字典是一种用来存放键值对的数据结构,它在redis中应用非常广泛,增删改查都是基于它,如set a hello 就是创建了一个key为a值为hello的键值对.
它使用哈希表作为底层实现,一个哈希表中可有多个哈希节点,每个节点又保存一个键值对
哈希表节点:
struct ditch{
dictEntry **table //哈希表数组
unsigned long len//table.size
unsigned long sizemask//哈希表大小的掩码,等于size-1,用来计算索引值
unsigned long used //该哈希表已有节点的数量
}ditch;
struct dictEntry{
void *key;
union{void val;
uint64_tu64;
int64_ts64}v;
struct dictEntry *next//指向下个节点形成链表,以解决哈希冲突
}
字典:dict(摘自redis设计与实现)
<img src="https://pic2.zhimg.com/v2-6ba048265cda1b1e57759996c87631d9_b.png" data-rawwidth="972" data-rawheight="1152" class="origin_image zh-lightbox-thumb" width="972" data-original="https://pic2.zhimg.com/v2-6ba048265cda1b1e57759996c87631d9_r.png">
<img src="https://pic4.zhimg.com/v2-ec2997e973981b46a2e662e2aacf0797_b.png" data-rawwidth="1282" data-rawheight="760" class="origin_image zh-lightbox-thumb" width="1282" data-original="https://pic4.zhimg.com/v2-ec2997e973981b46a2e662e2aacf0797_r.png">对于hash算法以及hash求索引和java中的HashMap思路大同小异,这里就不提了,下面说说它的重新散列rehash
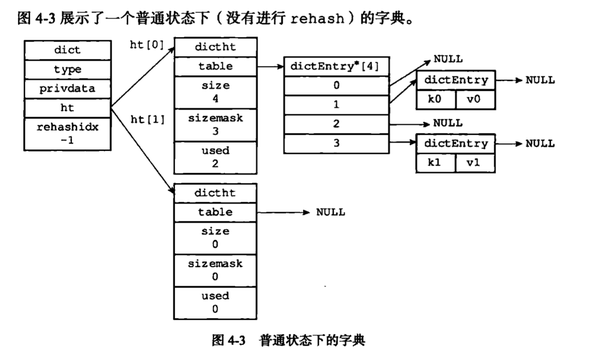 对于hash算法以及hash求索引和java中的HashMap思路大同小异,这里就不提了,下面说说它的重新散列rehash
对于hash算法以及hash求索引和java中的HashMap思路大同小异,这里就不提了,下面说说它的重新散列rehash
- rehash
随着操作的不断执行,哈希表键值对数目也会变化,为了始终控制负载因子在合适的范围,程序需要对哈希表大小进行扩展或收缩,扩展和收缩工作可通过重新散列完成,步骤如下:
- 为字典的h[1]哈希表分配空间,大小取决于要执行的操作:扩展操作则h[1].size为第一个大于h[0].size*2的2^n,若是收缩,则h[1].size为第一个大于h[0].size的2^n,如h[0].size=3,那么扩展时3*2=6,则h[1].size=2^3,若收缩,则为2^2
- 把h[0]中所有键值对重新散列(rehash)到h[1]
- 当2完成后,释放h[0],把h[1]设置为h[0],并在h[1]新建一个空白hash表,为下次rehash做准备
上面的一切看似完美,但是假象如果有千万级数据需要迁移,那么这样集中式的处理必将耗费大量时间,所以redis采用分而治之的思想,把rehash操作分摊到接下来的数据库操作上,过程如下:
<img src="https://pic4.zhimg.com/v2-fc6890d4c9856f8d4a509a2020306b93_b.png" data-rawwidth="1318" data-rawheight="522" class="origin_image zh-lightbox-thumb" width="1318" data-original="https://pic4.zhimg.com/v2-fc6890d4c9856f8d4a509a2020306b93_r.png">图解部分,可查阅<<redis设计与实现33页>>
 图解部分,可查阅<<redis设计与实现33页>>
图解部分,可查阅<<redis设计与实现33页>>四. 跳跃表
跳跃表是一种有序的数据结构,通过在节点中维持多个指向其它节点的指针,达到快速访问的目的.由于节点中按照score排序,所以被用来实现sorted set,下面贴出它的示意图(null标志着遍历结束)
&amp;amp;lt;img src="https://pic3.zhimg.com/v2-4f521f403eaed76164d4bdb8d7fb5d66_b.png" data-rawwidth="1102" data-rawheight="416" class="origin_image zh-lightbox-thumb" width="1102" data-original="https://pic3.zhimg.com/v2-4f521f403eaed76164d4bdb8d7fb5d66_r.png"&amp;amp;gt;下面我们先介绍它的跳跃节点:一个跳跃节点由以下几部分组成:
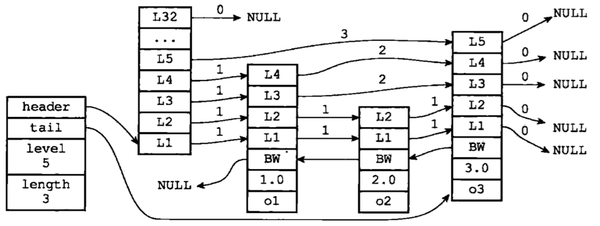 下面我们先介绍它的跳跃节点:一个跳跃节点由以下几部分组成:
下面我们先介绍它的跳跃节点:一个跳跃节点由以下几部分组成:
- 层level:跳跃表节点的level数组可以包含多个元素,每个元素都是一个指向其他节点的指针.层由前进指针和跨度组成,这两个属性可以唯一确定一个前方节点.
- 后退节点backword(bw),指向前置节点的指针
- 分值(score):score,double类型,跳跃表的节点是按分值大小升序排列,如果分值相同,按照成员对象在字典序中的大小排序
- 成员对象obj,指向一个字符串对象
下面看看跳跃表节点的数据结构代码
typedef struct zskiplistNode {
robj *obj;//成员对象obj
double score;//分值
struct zskiplistNode *backward;//后退节点
struct zskiplistLevel {
struct zskiplistNode *forward;//前进节点
unsigned int span;//跨度
} level[];//层数组,元素指向其他节点(表头除外)
} zskiplistNode
再看看跳跃表的数据结构代码
typedef struct zskiplist {
struct zskiplistNode *header, *tail;//头尾
unsigned long length;//长度,以O(1)获取跳跃表长度
int level;//表中层最大的节点的层数
} zskiplist;
五. 整数集合
整数集合(intset)是集合建的底层实现之一,当一个集合只包含整数值元素,且数量不多时,redis会采用intset作为集合建的底层实现.它可以保存int16_,int32_,int64_的整数值,并且保证集合中元素不重复,接下来看看它的数据结构代码
typedef struct intset {
uint32_t encoding; //编码方式
uint32_t length; //集合中包含的元素数量
int8_t contents[]; //保存元素的数组
} intset;
需要提一点:contents数组存放的元素类型是由encoding决定,encodin是int16_,int32_,int64_,contents元素类型也将对应为int16_,int32_,int64_
- 升级
每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现在所有元素的类型都要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合.
1. 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
2. 将底层数组现有的所有元素都转换成与新元素相同的类型,并将新类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
3.将新元素添加到底层数组里面。
- 升级的好处:
- 提升整数集合的灵活性:由于可以自动升级,我们可以随意的插入元素
- 尽可能地节约内存:C字符串中要让一个数组同时保存16,32,64位是直接声明一个int64数组,而redis的intset它可以先用16位存,等遇到更大的时,再升级,避免了盲目使用大内存
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
最后看看intset数据结构示意图:
&amp;amp;lt;img src="https://pic3.zhimg.com/v2-867b56401da0d668ab45a152f2532d5a_b.png" data-rawwidth="684" data-rawheight="240" class="origin_image zh-lightbox-thumb" width="684" data-original="https://pic3.zhimg.com/v2-867b56401da0d668ab45a152f2532d5a_r.png"&amp;amp;gt;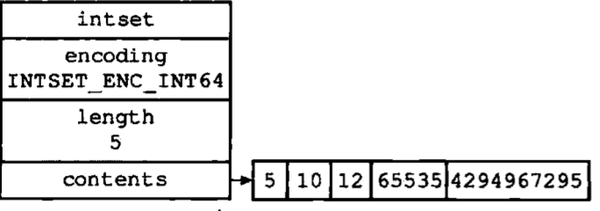
redis的基本数据结构已经介绍完,接下来让我们学习 图解redis之对象
