

 作者 | kpaxqin
如何设计 Redux 的 store?这几乎是 Redux 在实践中被问到最多的问题,或许你有自己的方式,却总觉得哪里不太对劲。这篇文章希望从状态是什么,到 Elm 中的状态管理,最后与 Redux 分析和对比,试图找到问题,并推导可行的改良方式。
哪些状态需要被管理?
Domain data
作者 | kpaxqin
如何设计 Redux 的 store?这几乎是 Redux 在实践中被问到最多的问题,或许你有自己的方式,却总觉得哪里不太对劲。这篇文章希望从状态是什么,到 Elm 中的状态管理,最后与 Redux 分析和对比,试图找到问题,并推导可行的改良方式。
哪些状态需要被管理?
Domain data
Domain data 非常好理解,他们直接来源于服务端对领域模型的抽象,比如 user、product。它们可能被应用的多个地方用到,比如当前 user 包含的权限信息所有涉及鉴权的地方都需要。
通常,前端对 Domain data 最大的管理需求是和服务端保持同步,不会有频繁和复杂的变更——如果有的话请考虑合并批处理和转移复杂度到服务端。
甚至有不少页面仅在初始化时获取一次 Domain data,从此就再无瓜葛,直到跳转到下一个页面。
UI state决定当前 UI 如何展示的状态,比如一个弹窗的开闭,下拉菜单是否打开。
在我看来,UI state 是前端真正开始复杂的部分——如果仅仅依靠服务端拿下来的 Domain data 就能做好前端,backbone 的 Model 早就一统江湖了,没后来者们什么事情。
和 Domain data 的简单、稳定不同,UI state 是多变,不稳定的——不同的页面有不同、甚至相似但又细微不同的展现和交互。
同时,UI state 之间也是互相影响的,比如选择列表中的元素 (选中状态是 ui state),当选中数量低于 N 时禁用提交按钮 (按钮是否禁用也是 ui state)。这是前端工作中非常常见的需求,整个场景中没有 Domain data 出现。
UI state 多变、不稳定,但它仍然是需要被复用的。小到弹窗的开闭,大到表单的管理,他们的逻辑都是明显可被抽象的。
App state *App 级的状态,例如当前是否有请求正在加载。个人倾向将它们视为另一种抽象角度下的 UI state。因为本质上它们仍然是服务于 UI 的:一个异步下拉框会发请求,加载页面主要信息也会发请求,而我们通常希望前者加载时只 disable 下拉框,而后者可能要用 Loading mask 遮罩整个页面——场景不同,对状态的需求就不同,单纯关注当前是否有请求正在加载没有意义,只有与 UI 场景结合才会产生价值,因此我倾向认为 App state
的本质是对 UI state 的再抽象。
由 Redux 库贡献者之一维护的 recipes 提到:
Because the store represents the core of your application, you should define your state shape in terms of your domain data and app state, not your UI component tree.
这基本代表了如今社区的主流实践,它包含了两个主要观点:
-
Store 代表了 应用 的状态 (store represents the core of your application)
-
使用 domain data 和 app state 作为 store 的主要抽象依据
很少有人质疑过这两点的正确性,因为第一点和 Flux 社区一脉相承,第二点无论看起来还是写起代码来都显得顺理成章。
有没有可能这两点才是 Redux 实践的问题所在?
在往下讨论之前,不妨看看 Redux 最重要的借鉴对象——Elm 是如何管理状态的。
Elm 中的状态树 Elm 简介先用一张图表达 Elm 的架构:
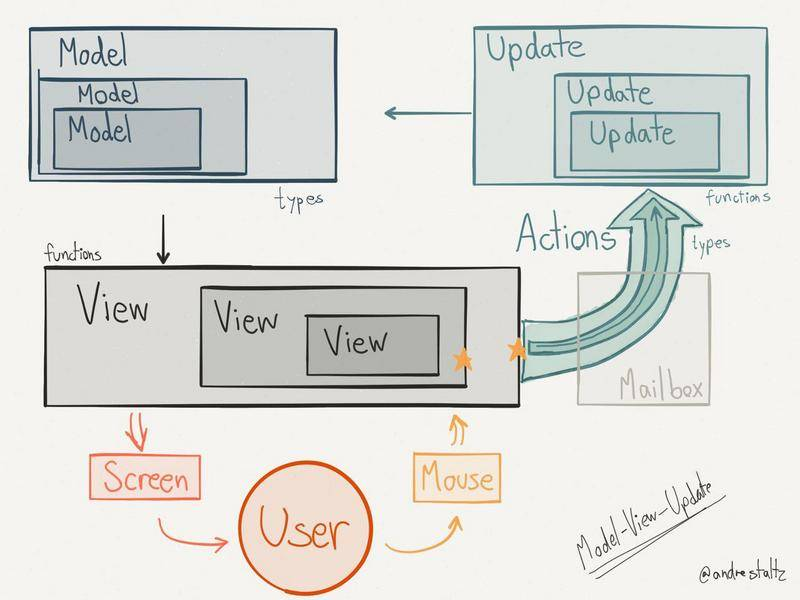
结合代码往下看,首先在 Elm 中定义一个组件 Counter,没有 Elm 相关基础也没关系,可以结合注释理解大概即可:
-- 定义数据模型
type alias Model = Int
-- 定义消息
type Msg = Increment | Decrement
-- 定义更新函数
update : Msg -> Model -> Model
update msg model =
case msg of
Increment ->
model + 1
Decrement ->
model - 1
-- 定义渲染函数
view : Model -> Html Msg
view model =
div []
[ button [onClick Decrement] [text "-"]
, text (toString model)
, button [onClick Increment] [text "+"]
]
-- 定义初始数据
initModel : Model
initModel = 3有人可能要问了,"组件呢?在哪?这几个变量哪个是组件?"。答案是:加在一起就是。
这是 Elm 架构的标志:每个组件都被分成了 Model/View/Update/Msg 四个部分。
当它需要作为应用单独运行时,就将这几个部分"绑"在一起:
main = App.beginnerProgram {model = initModel, view = view, update = update}而当它需要被上层组件使用时,则由上层组件使用这些分立的元件构建自己的对应部分,下面是使用 Counter 构建一个 CounterList:
以下主要关注对 Counter.XXX 的使用
import Counter
-- 使用 Counter.Model 组合新的 Model
type alias IndexedCounter = {id: Int, counter: Counter.Model}
type alias Model = {uid: Int, counters: List IndexedCounter}
-- 使用 Counter.Msg 组合新的 Msg
type Msg = Insert | Remove | Modify Int Counter.Msg
update : Msg -> Model -> Model
update msg model =
case msg of
Modify id counterMsg ->
let
counterMapper = updateCounter id counterMsg -- 调用 updateCounter 函数
in
{model | counters = List.map counterMapper model.counters}
-- 调用 Counter.update
updateCounter : Int -> Counter.Msg -> IndexedCounter -> IndexedCounter
updateCounter id counterMsg indexedCounter =
if id == indexedCounter.id
then {indexedCounter | counter = Counter.update counterMsg indexedCounter.counter}
else indexedCounter
view : Model -> Html Msg
view model =
div []
[ button [onClick Insert] [text "Insert"]
, button [onClick Remove] [text "Remove"]
, div [] (List.map showCounter model.counters) -- 调用 showCounter
]
-- 调用 Counter.view
showCounter : IndexedCounter -> Html Msg
showCounter ({id, counter} as indexedCounter) =
App.map (\counterMsg -> Modify id counterMsg) (Counter.view counter)
-- 调用 Counter.initModel
initModel = {uid= 0, counters = [{id= 0, counter= Counter.initModel}]}可以看到,上层组件同样是分成了四个部分,而每个部分都分别调用了子组件的对应元素。
整个 Elm 的组件树,就是这样一层层组合起来,直到最顶层,仍然是分立的四部分,需要运行时,才被粘合到一起。
最终被运行的根节点组件,无论是 Model、View 还是 Update,都是由整个组件树上无数个小组件组合出来的,在组合的过程中,只有使用 A 组件的 Model,而不会有使用 User Model——整个架构从抽象、到组合,都是完全面向组件,而非面向领域模型的。
在谈论 Elm 的Model/Update/Msg时,熟悉 Redux 的读者应该很快就联想到了Store/Reducer/Action,然而它们间的差异也是显而易见的:Elm 中Model/Update/Msg/View是 创造组件时 定义的,而 Redux 中的 Reducer/Action 则是在 组件树之外 定义的。
脱离具体的组件与交互场景,面向组件抽象就变得非常困难,此时领域模型成了几乎唯一可靠的抽象依据。
领域模型与组件树无关,加上之前 flux 社区的惯性,社区很自然就把 store 做成了 App 级的全局单例。
然而,管理 UI state 的需求仍然存在,一个 Web 应用可以有无数个页面,相应地有无数的 UI state 需要管理,如果状态管理框架不能有效地解决它们,也就失去了存在的意义。
在 Elm 中,应用的状态树随着组件树而变化,假设组件树的根结点是页面,那么页面 A 和 B 的状态树必然是不同的,而 Redux 却需要用唯一一个状态树,去满足整个应用——N 个组件树 (页面) 的需求,这显然是有问题的。
因此在 Redux 中有 reselect, 有 normalize,有 mapStateToProps,这些 Elm 中通通不存在的东西,它们面向的其实是同一个问题:状态树到组件树如何映射。然而它们都只能起缓冲作用,因为状态树与组件树一对 N 的关系并没有改变。
举个例子:A 页面有个复杂的 Counter 组件,我们希望它被状态管理框架管理起来——这显然比 setState 更清晰更易维护。于是我们设计了 counterReducer,并把它放到了 store 中:
const rootReducer = combineReducers({
user: userReducer,
product: productReducer,
// 添加 counterReducer
counter: counterReducer,
})假设 B 页面用到了同样的组件——但是需要两个 counter,现有的状态树就无法满足需要了,只能改成:
const rootReducer = combineReducers({
user: userReducer,
product: productReducer,
// 添加 counterReducer
pageA: combineReducers({
counter: counterReducer,
}),
pageB: combineReducers({
counter1: counterReducer,
counter2: counterReducer,
})
})这个例子既体现了 Redux 相对于 Flux 的进步 (在 Flux/Reflux 中,要复用 counter 的逻辑非常困难),也体现了 Redux 在 store 设计上的尴尬:
-
Domain data 与 UI state 混搭
-
理论上页面有无穷多个,未来 rootReducer 里还需要装下 page(CDEFG)
-
rootReducer 具有全局性,而页面、组件通常是局部的,修改全局去服务局部是 bad smell
"如何设计 Redux 的 store?"这个问题的背后,便是如上所述的,Redux 在设计上相对于 Elm 的偏离导致的。这种偏离导致 Redux 仍然不能非常好地驾驭 UI state,最终不得不表示"You might not need Redux"和"setState is OK"。
Reducer 的优势客观地讲,脱离组件树定义的 Reducer 并非一无是处。它确实很难处理细碎、嵌套的 UI 状态。但在处理某一"类"UI 状态时却显得得心应手——有些 UI 状态是可以被脱离组件树抽象的(类似前面提到的 App state)。
一个著名的例子是 redux-form,它把表单这一"类"行为进行了抽象,并且挂载在根 reducer 下:
import { createStore, combineReducers } from 'redux'
import { reducer as formReducer } from 'redux-form'
const reducers = {
// ... your other reducers here ...
form: formReducer // <---- Mounted at 'form'
}
const reducer = combineReducers(reducers)
const store = createStore(reducer)类似的例子还有全局的错误处理、loading 状态管理以及模态窗的开闭管理。他们都是脱离组件树定义 Reducer 带来正面价值的案例——对于行为高度固定的、没有复杂嵌套关系的 UI 状态,脱离组件树几乎不会带来抽象上的缺失,用全局的方式进行抽象是可行的。
题外话:WebApp 场景下的隐患Store 对象存在于内存中,在用户没有刷新的情况下是一直存在并且可访问的,而一旦用户刷新、分享链接,Store 就会重新创建。由于 Store 是"应用"级的,开发者使用 Store 中的数据时,很难知道数据在刷新、分享后是否可用。
举个我曾经在 另一篇博客 中提到过的例子,一个业务流程有三个页面 A/B/C,用户通常按顺序访问它们,每步都会提交一些信息,如果把信息存在 Store 中,在不刷新的情况下 C 页面可以直接访问 A/B 页面存进 Store 的数据,而一旦用户刷新 C 页面,这些数据便不复存在,使用这些数据很可能导致程序异常。
如果在设计 Store 时,是像上面提到的 store.pageA 这样的形式,情况会稍有缓解,因为至少开发者知道这个数据属于 pageA,对数据的来源有认知,如果 Store 是按领域模型划分的,情况会变得非常糟:开发者在使用 store.user 这样的数据时不可能知道这个数据是否可靠,最终要么花费额外的精力去确认,要么给应用留下隐患——显然后者会是更常见的情况。
Store 这个名字给人以"Storage"的错觉,面向领域模型的设计使得这种错觉被进一步巩固。
从辩护的角度,这个问题不是 Redux 独有,它是 App 级 Store 在 Web 场景下的通病,从 Flux/Reflux 开始就已经存在。另外也可以把问题推给开发者:你不确认数据的可靠性,出了问题怪谁?
然而,好的框架、范式应该具备足够的"防御性",当前 Redux 的主流实践在这个问题上并没有给出让人满意的答案。
改良版的实践例:React-Redux 的 Real-World example 就把分页信息存进了 store 导致刷新后页码丢失。
尽管 Redux 有上面提到的问题,但它在单向数据流、提倡纯函数、解耦输入与响应等方面仍然有非常大的价值。对上面提到的问题,我试图通过改良实践去缓解:Page 独立声明 reducers 并创建 store。
这个过程可以使用高阶组件封装起来,代码:
const defaultConfig = {
pageReducers: {},
reducers: commonReducers, // import from other files
middlewares: commonMiddlewares, // import from other files
};
const withRedux = config => (Comp) => {
const finalConfig = {
...defaultConfig,
...config,
};
const { middlewares, reducers } = finalConfig;
return class WithRedux extends Component {
constructor(props) {
super(props);
const reducerFn = combineReducers({
...finalConfig.pageReducers,
...reducers,
});
this.store = applyMiddleware(
...middlewares,
)(createStore)(reducerFn);
}
render() {
return (
<Provider store={this.store}>
<Comp {...this.props} />
</Provider>
);
}
};
};接下来,只需要在 依赖 Redux 的页面 使用 withRedux 即可:
const PageA = ()=> <div>A</div>;
export default withRedux({
pageReducers: {
foo, // 和 commonReducers 合并成最终页面的 reducer
},
// reducers: {}, // 直接替换 commonReducers
})(PageA)它可以从两方面缓解上述问题:
-
抽象问题:每个 Page 独立创建 store,解决状态树的一对多问题,一个状态树 (store) 对应一个组件树 (page),page 在设计 store 时 不用考虑其它页面,仅服务当前页。当然,由于 Reducer 仍然需要独立于组件树声明,抽象问题并没有根治,面向领域数据和 App state 的抽象仍然比 UI state 更自然。它仅仅带给你更大的自由度:不再担心有限的状态树如何设计才能满足近乎无限的 UI state。
-
刷新、分享隐患:每个 Page 创建的 Store 都是完全不同的对象,且只存在于当前 Page 生命周期内,其它 Page 不可能访问到,从根本上杜绝跨页面的 store 访问。这意味着 能够从 store 中访问到的数据,一定是可靠的。
通过 commonReducers/commonMiddleware 可以方便复用一些全局性的解决方案,比如 redux-thunk/redux-form。页面默认使用 commonReducers/commonMiddlewares,也可以完全不用,甚至页面可以不使用 redux。 复用行为,而不是共用状态,这是 Redux 相对于 Flux 最大的进步,现在我们将这个理念继续推进。
A: 没有,它只是明确了组件树和状态树一一对应的关系,一个应用会有 N 个页面,但不会同时显示两个页面,因此,任何时刻当前页面对应的状态树都是 single source of truth。
Q:和社区主流库集成是否会有问题A: 是的,由于和社区主流实践有差异,遇到问题是难以避免的。
假设你正在使用 ReactRouter,采用上述方案后组件树的结构将会变成 Router > Route > Provider > PageA,而react-router-redux则需要 Provider > ConnectedRouter > Route > PageA 这样的组件结构:ConnectedRouter 是react-router-redux引入的,依赖
Provider 向 context 中注入 store,这意味着 Redux 的 Provider 必须是路由的父元素,和我们将 Redux 下放到页面的思路相冲突。
对此,我们的选择是:放弃react-router-redux。
我强烈建议你回顾当初引入 react-router-redux的原因:如果是希望通过 action 操作 history,那么一个独立的中间件可以轻易做到;如果是希望通过 store 访问 location/history,在页面初始化时把 location/history 放进 store 也非常简单;如果不知道为什么,仅仅因为它是全家桶的一部分——何不干掉他试试?
在移除react-router-redux后,我们不仅没有受到任何功能性的影响,反而使得架构层面的耦合更低了:路由与状态管理方案不再有耦合关系。
这种从耦合中解放的感觉就像水里穿着衣服游泳的人终于脱掉了外套,之前是视图 (react)- 路由 (router)- 状态管理 (redux) 相互耦合,却并没有带来明显的收益,而现在我们已经开始考虑换掉 react-router 了。
甚至,既然是由页面决定是否引入 Redux、使用哪些 reducers/middlewares,那么一个项目中不同的页面采用不同技术栈是完全可行的,这允许你在某些页面上大胆尝试新的方案而不用担心影响全局:架构上的低耦合使我们拥有更多的选择余地。
Q: 谈到 UI state,社区有以 redux-ui 为代表的方案,怎么看?A: 它们恰恰呼应了本文提到的另一个侧面:Reducer 的抽象问题。redux-ui 让组件状态、行为与组件定义重新回到了一起,从而使"让 redux 管理 UI state"变得更自然。当然它也带来了一些代码结构上的限制,是否采用取决于具体场景下的考量。它和本文最后提倡的改良实践并不冲突,甚至,改良版实践能更容易地在部分页面先行尝试这些新方案。
本文小结本文从 Elm 的角度剖析了 Redux 存在的问题,也分享了我目前采用的实践方式,这个实践方式不是神奇药水,仅仅是权衡问题和现状后的小步改良。
回顾和对比主流实践的两个重点:

同时我也深知这还远远不够,期待能有更好的实践方式和更好的轮子出现。从程序设计的角度,我相信改良后的实践又进步了一点点:更低的耦合、更准确的对应关系、更可靠的数据依赖,与 Elm 也更加接近。

本文系作者授权转发,原文链接:https://segmentfault.com/a/1190000009540007 。投稿请发邮件至 luna.han@infoq.com 。
今日荐文点击下方图片即可阅读

React Native 应用如何实现 60 帧 / 秒的流畅动画?
视野拓展InfoQ 主办的移动和前端开发领域的精品大会【GMTC 2017】将于 6 月 9~10 日在北京举行,作为首届以“大前端”为主题的大会,GMTC 涉及移动、前端、跨平台、AI 应用等多个技术领域,帮助你方方面面提高技术水平。扫描下图二维码,前往官网了解详细信息!

「前端之巅」是 InfoQ 旗下关注前端技术的垂直社群,加入前端之巅学习群请关注「前端之巅」公众号后回复“加群”。推荐分享或投稿请发邮件到 editors@cn.infoq.com,注明“前端之巅投稿”。


