

下周二柯洁和阿尔法狗狗的围棋对战就要开始啦。一定有不少好奇宝宝想知道这个已经横扫世界顶尖围棋手的 AlphaGo 背后究竟发生了什么,在这里小编就带大家简单了解一下狗狗的背后的故(yuan) 事 (li)。
AlphaGo 是谷歌公司的 DeepMind 小组开发的、用来玩围棋的窄域 AI(Narrow AI, 又称 Weak AI, 是相对于 Strong AI 而言的,只重点关注一个任务的人工智能)。AlphaGo 整体由(走子)策略网络,快速走子,估值网络和蒙特卡洛树搜索构成。
总的来说,狗的构成有以下几个部分:
<img src="https://pic1.zhimg.com/v2-81b3011e39877a7aec89579d5caf572c_b.png" data-rawwidth="1948" data-rawheight="618" class="origin_image zh-lightbox-thumb" width="1948" data-original="https://pic1.zhimg.com/v2-81b3011e39877a7aec89579d5caf572c_r.png">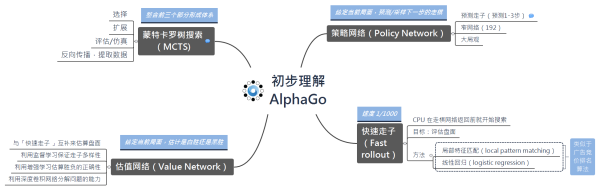
(点击查看原图更清楚)
策略网络(Policy network)
策略网络的目的,简单地说,就是用来预测下一步要怎么走的。一般狗会预测1-3 步盘面,而这个预测判断的来源是大量机器学习的训练。主要包含了两个阶段。
阶段一是监督学习(SL)。规则网络从 KGS Go 服务器的 3000 万个位点进行训练。这样可以把预测准确性提高到 57%。但这样做的缺点是估值会变得巨慢,于是在这里会引入「快速走子 」策略(FR Policy)。FR 没有那么准确(27%),但快很多。所以这两者其实就是一个准确度与速度互补的关系。
阶段二是增强学习(RL)。如果说监督学习是为了预测下一步最可能的走子的话,那么增强学习就是预测下一步最优的走法。在这个阶段,狗狗与随机选取的自己之前迭代的 120 万局比赛再对弈(避免过度拟合)。
估值网络(Value network)
最后一个训练阶段目的是评估位点(也就是说,计算现在走的这一步导向胜利的可能性有多大)。为了避免过度拟合(总之就是为了得到更普遍的位点数据),新的数据集还是从狗狗自己训练过的棋局数据里面产生(3000 万个不同的位点,每个都来自不同的棋局)。
训练后的估值函数比蒙特卡洛树搜索的快速走子更准确。监督学习保证了走子训练的多样性,增强学习估算某个位点的胜负概率。
蒙特卡洛树搜索
一句话概括,蒙特卡洛树搜索是用来整合前几个部分形成体系的。其原理是在随机采样上计算得到近似结果。采样越多,得到结果接近最优解的概率越大。也就是狗在对弈的时候,随机在棋盘上下棋,快速下满棋盘,怎样得最高分就怎样走(当然在采用蒙特卡洛树搜索的时候,实际算法更复杂)。这种方式尤其适合解决对弈问题。
如果翻译成流程图,就是这样的
<img src="https://pic2.zhimg.com/v2-5927b95c54963280e97647bd57ec46dd_b.png" data-rawwidth="1679" data-rawheight="1323" class="origin_image zh-lightbox-thumb" width="1679" data-original="https://pic2.zhimg.com/v2-5927b95c54963280e97647bd57ec46dd_r.png">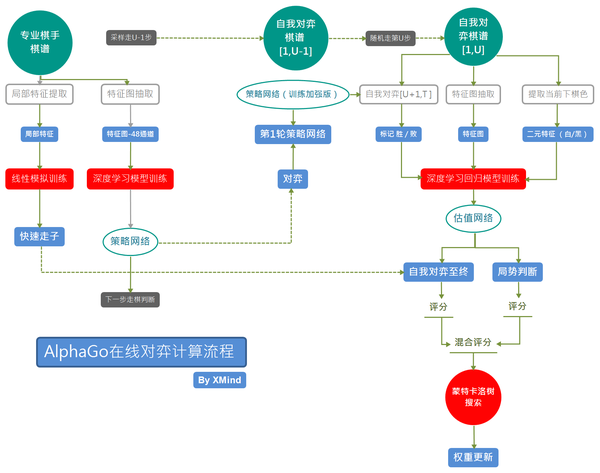 下载这张思维导图
下载这张思维导图
山雨欲来风满楼
很多年以后,中学的历史书课本上会写着:
2017 年 5 月,柯洁与 AlphaGo 的围棋对弈是人类历史上与人工智能围棋单挑的最后一役。而 2016 年 AlphaGo 与李世石的那次对战,则是摧毁人类满满信心和不自量力的转折点。
回到现实。目前也只有世界围棋等级分排名第一的柯洁可以和(排名第二的) AlphaGo 对战了。狗的厉害大家都有目共睹。去年大胜李世石之后,又以 Master* 的身份在网络上以 60 胜 0 负的战绩横扫中日韩顶尖棋手。事实上,去年狗在世界围棋分榜排名一度超过柯洁登顶,随后又被柯洁赶超。不过,今年世界围棋等级分榜已将人工智能移出榜单,不再计入排名。
<img src="https://pic2.zhimg.com/v2-c6379c36f0e913aa713880f6ff4dded1_b.png" data-rawwidth="650" data-rawheight="366" class="origin_image zh-lightbox-thumb" width="650" data-original="https://pic2.zhimg.com/v2-c6379c36f0e913aa713880f6ff4dded1_r.png">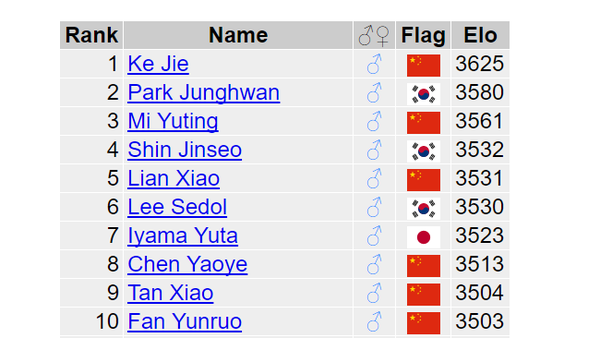
最新世界围棋分榜排名
考虑到柯洁的状态,以及狗的技术随时间呈指数级的增长,大家对于柯洁的低胜算基本没有什么争议(此前柯洁已连续两轮输给 AlphaGo 升级版 Master)。根据古力的看法,「柯洁赢一局的可能性不到10% 」。
或许,我们还可以把这次的希望寄托在团体赛上。五个人对战一个 AI,会不会有赢一局的胜算呢?
(当然,还是希望柯洁能像李世石去年第四局那样神赢一场,求打脸)。
*注:和 Master 对弈的网棋是 30 秒一手的快棋,让 AI 处于更有利的地位。
干货部分参考:Understanding AlphaGo
想每天第一时间收到 AI 相关高质量技术内容?
扫描二维码关注公众号:AI训练场

