

封面图摄于佛罗伦萨,2014
本文来源于去年在外部做的一个技术分享,简单整理了一下。
先看看项目的技术背景:
公有云服务(阿里云,不是打广告) -- 降低运维成本,快速对外服务
Java 语言 (社区资源丰富,各种现成的轮子)
中间件 Redis,MongoDB,RocketMQ…
Mysql (RDS 实例)
经过紧张的一期工作,项目也可以基本跑起来了,主要的功能也可以正常用起来了,架构如下图:
 ‘
‘
一
在我们深感“欣慰”的同时,发现不合理的地方还是蛮多的,于是很快就开始了紧罗密布的改造:
改造后,在应用服务端对每次请求做读写判断,若是写请求,则把这次请求内的所有DB 操作发向主库;若是读请求,则把这次请求内的所有DB操作发向从库,如下图所示。
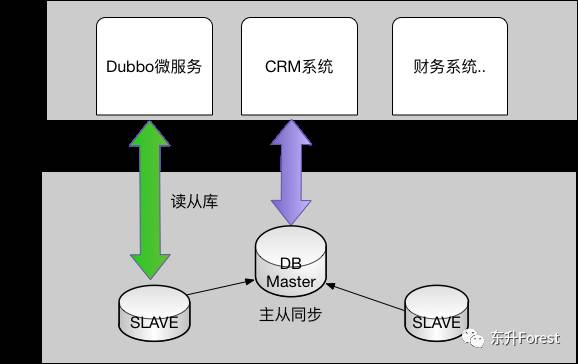
主从同步、读写分离给我们主要带来如下两个好处:
1.减轻了主库压力:业务有大量的读操作,做读写分离后,读压力转移到了从库,主库的压力降低了 1个数量级。
2.从库可以按需水平扩展:当从库压力太时,可直接添加从库机器,缓解读请求压力。
二
如果发现读写分离不够用,下一步该怎么办?比如写操作的压力随着业务爆发式的增长而持续加大,那么解决的方案可以如下:
将主库做拆分,一方面以提升性能,另一方面减少系统间的相互影响,以提升系统稳定性。这一次,将系统按业务进行了垂直拆分,将最初庞大的数据库按业务拆分成不同的业务数据库,每个系统仅访问对应业务的数据库,避免或减少跨库访问。
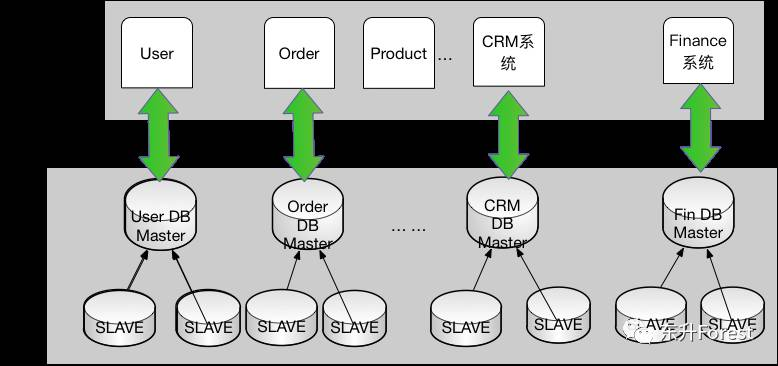
需要注意的是,垂直分库必然是有代价的,比如过去的SQL join自然没法直接使用了。 所以这个时候,除了重构本身,还需要做的就是制定团队的SQL执行标准,将过去一个SQL靠join不同表来拿到完整数据,改为通过请求不同的服务,然后在程序中组装数据。最后,重改代码,建立七API的自动化测试体系,自然最好。
三
再延伸往下讲两句,一般来说,垂直分库基本就够了,但是作为ToC项目,表里的数据会越积越多,而且是非线性增长的,性能某一个时刻是要大幅下滑的,所以还需要再做一层。系统将会如下图来改变:
应用层:即各类业务应用系统
数据访问层:统一的数据访问接口,对上层应用层屏蔽读写分库、分库、缓存等技术细节。
数据层:对DB数据进行分片,并可动态的添加shard分片。
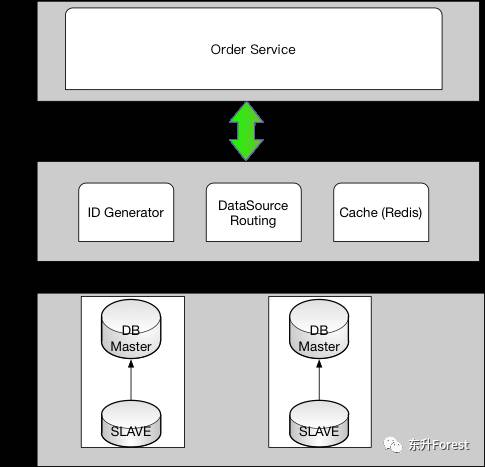
水平分库的技术关键点在于数据访问层的设计,数据访问层主要包含三部分:
IDGenerator:生成每张表的主键
DataSourceRoute:将每次DB操作路由到不同的shard数据源上
Cache: 采用Redis实现数据的缓存,提升性能
其中一个可以参考的主键ID的生成设计思路:
整个ID的二进制长度为64位•前40位使用时间戳,以保证ID是升序增加
中间6位是分库标识,用来标识当前这个ID对应的记录在哪个数据库中
后18位为自增序列,以保证在同一秒内并发时,ID不会重复。
每个shard库都有一个自增序列表,生成自增序列时,从自增序列表中获取当前自增序列值,并加1,做为当前ID的后18位。
最后几点总结
•架构不是简单的“做”或者“规划”,而是动态去演化。
•数据层是后台架构中最重要又最薄弱的一环,需要提前做准备•增强系统和数据监控和报警,否则每天无法入眠
•定期分析系统数据,查漏补缺
•一切脱离业务的架构设计与新技术引入都是耍流氓。
