

作者简介
方建,卡内基梅隆大学硕士,本科毕业于清华大学计算机系。目前任职于硅谷著名独角兽公司 Pinterest,参与 Pinterest 多个高性能实时系统的研发的工作。曾作为早期员工参与创新工场重点孵化项目行云的研发工作。
项目介绍
Terrapin 是一款 Pinterest 自主研发的,目标服务PB级别离线生成数据的存储系统。目前 Terrapin 经过两年半的迭代,已经成为 Pinterest 内部使用最为广泛的存储系统,存储着超过200个数据集,算上数据冗余,总共有超过 1PB 的数据,高峰时段超过了每秒百万次查询。Terrapin 的数据导入非常简单,不管什么背景的工程师,简单的几行 Python 代码可以实现数据导入。
项目背景
Pinterest 作为一家月活跃用户超过1.6亿,不断有海量数据产生的互联网公司,Hadoop 生态系统在其内部有着广泛的应用。 每天有数以万记的 Hadoop 任务对平台上的原始数据进行整理,聚合,计算以及分析。伴随这些 Hadoop 任务,一批批高度物化(materialized)的数据集不断的产生。这些数据集对Pinterest各个产品环节有着重大意义,因此摆在工程师面前的一个问题是,如何设计一个高可用,高吞吐,低延迟的业务系统来支撑针对这些数据的查询。

上面所描述的问题在 Pinterest 很早期就已经出现,因此在2014年之前,我们尝试利用 HBase 去解决这个问题。起初,在数据大小为几十GB级别的时候,这个方案是行得通的。但是随着公司用户的快速增长,数据规模很快成长到了TB级,这个方案的局限性就体现出来了:首先是导入数据太慢,一开始我们利用 HBase 的实时写操作来导入数据,这样不仅用时过长,还容易对读操作产生影响。后来我们尝试利用 HBase 的批量导入(Bulk Upload)HFile(先把数据集转换成 HFile 格式) 的方式来上传数据集,虽然很大程度上提高了导入速度,但是这种方式无法保证数据的局部性(locality),HBase 将这些导入的 HFile 分散在整个集群里面,因此在做查询的时候经常有跨 RegionServer 的数据查询,这样一来低延迟的这个要求就很难达到。虽然我们尝试通过定期的归整(Compaction)来最大化数据的局部性,但是有过 HBase 经验的同学应该知道,数据归整会显著增加服务器的负载,因此还是可以经常观察到延迟的不稳定。

针对上面所遇到的问题以及所服务数据的特点,我们决定设计一个全新的系统从根本上解决这些问题,因此 Terrapin 由此诞生,笔者有幸参与此系统的实现和维护工作,希望通过这片文章分享一些关于 Terrapin 的知识。
系统设计
我们观察到需要 Terrapin 支持的数据有以下这些特点:
-
固定周期生成整个数据集,不需要支持增量的写操作或者随机写操作
-
数据结构都是键值对(Key/Value)
-
查询操作为随机精确查询(Point Lookup),无需支持扫表操作(Scan)
同时针对使用 Terrapin 的客户,此系统需要达到如下要求:
-
低延迟 - 单个键值对查询应该小于5毫秒
-
高吞吐 - 支持每秒超过百万次的查询
-
高可用 - 达到99.5%的可用性
-
易伸缩 - 扩容需要相对简单且不影响可用性和延迟
-
多租户(mult-tenancy)- 同一个集群需要服务多个不同的数据集
-
易导入数据 - 需要支持轻松从 S3/HDFS/Hadoop/Hive 导入数据集
基于以上的特点和要求,以及 Pinterest 当时的技术栈,我们决定设计一个基于 HDFS + HFile(HBase 底层存储格式)的系统。选用 HDFS 有如下好处:
-
解决了大部分的分布式问题(数据复制,伸缩性,容错能力)
-
社区很大,工具集完善
-
与 Hadoop 生态系统兼容性很好
-
类似于文件系统的读写接口简单易用
而 HFile 作为 HBase 的底层存储格式,本身支持随机键值查询,因此可以契合我们的查询要求。所以这套方案我们要解决的首要问题是数据的局部性(locality),我们需要确保不会有跨机器的键值查询,所有的查询应该落到本地硬盘之上。因此我们做出了如下的系统架构:
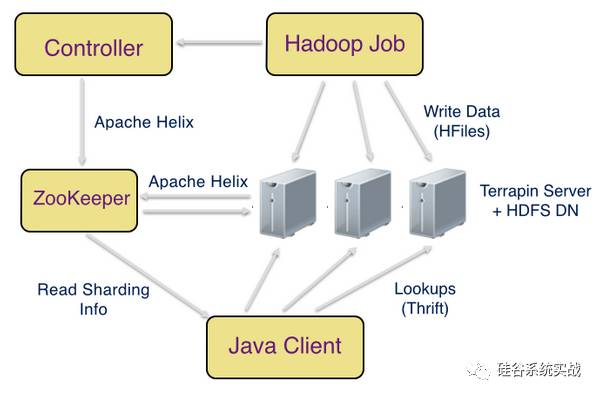
在上图中,有如下几个关键组件:
-
ZooKeeper - 我们使用 ZooKeeper 存储集群的元数据,主要包括各个服务器的状态以及文件和服务器的映射关系(例如:abc/part-00000 -> [terrapin-host-1, terrapin-host-2])。客户端利用这里的元数据找到相应键所在的服务器,然后直接发送请求到该服务器进行查询操作
-
Terrapin Server - Terrapin Server 部署到每个 HDFS 的 DataNode 之上,其负责接收键值对的查询请求,然后利用 HDFS 的接口对相应文件进行查询。同时,Terrapin Server 需要定期查询(10分钟) HDFS DataNode 以了解数据块的分布情况,然后综合信息汇报给 ZooKeeper。Terrapin Server 这个进程也会负责缓存那些热的数据块到内存里面,来提高查询性能。
-
Terrapin Controller - Terrapin Controller 主要负责监听来自 ZooKeeper 关于数据块分配的消息,然后综合成一个物化视图写入 ZooKeeper 提供给客户端使用。同时,Terrapin Controller 需要负责数据集的更新,删除,回滚和重新分配(rebalance)这些维护性的操作。
-
Java Client - 客户端需要负责查询的路由操作,简单来说流程就是客户端监听 ZooKeeper 的元数据,物化之后放入内存,然后每当有查询过来,找出相应键的服务器列表,发送请求到相应的服务器
-
Hadoop Job - Hadoop 任务负责数据的导入工作,具体来说就是通过 DistCp 把数据从 S3 导入 Terrapin 下的 HDFS 集群,一旦导入完成,Hadoop Job 需要通知 Terrapin Controller 新的版本已经就绪,然后 Terrapin Controller 会更新 ZooKeeper,以让所有的 Terrapin Server 来查询这些新的数据。
一些细节
如何保证 HDFS 不把文件分块存储到不同的 DataNode 上?
我们知道当文件写入 HDFS 的时候,HDFS 会根据文件大小将文件进行分块,然后分散存储到不同的 DataNode。这么做的目的是更好的负载均衡,但是给我们带来一个问题。HDFS 的分块策略无法直接控制,因此我们无法知道到底哪些键值对被分配到了哪些 DataNode 上,这样一来数据的局部性无法保证。因此我们要求每个存储到 HDFS 上的文件应该只有一个文件块,这样一来虽然我们无法控制 HDFS 的分块策略,但是我们可以确保文件不需要分块。可是如果一个文件块过大也会影响读的性能,因此在 Hadoop 生成数据的时候,我们要求客户保证每个文件不操作 4G,从我们将近三年的运行经验来看,这个单数据块4G文件的设计没有对性能造成显著影响
如何保证有数据上传不会对性能造成影响?
通常来说,Terrapin 所储存的数据需要做到每天更新,而且一个 Terrapin 集群需要服务上百个不同的数据集,因此几乎每隔几十分钟就会有数据上传。我们知道当数据在上传的时候,他会占用两个资源,一个是磁盘的IO,一个是网络带宽。这两个资源会对 Terrapin 的查询性能造成显著的影响(>100% 延迟增长)。为了解决这个问题我们采用了三个策略:1)配置系统使得 HDFS DataNode 进程只使用一个 CPU 核来进行写入操作;2)限制 DistCp 每个 mapper 所能够使用的带宽。3)采用两个集群存储同样的数据,当客户端见到某个集群有延迟增长的时候,会采用另外一个集群进行查询。总体来说策略 3 对我们的帮助最大,虽然其增加了数据冗余,但是集群层面的数据冗余还有有如下好处:
-
不同的集群位于不同的数据中心,可以避免某个数据中心突然的不可用所造成的灾难
-
日常的维护操作变得更加透明,比如我们部署,重启这些 Terrapin Server 的时候,客户端很难见到读失败,因为客户端会自动 Failover 到另外一个集群上去
总结
本文介绍了 Pinterest 的离线大数据服务系统 Terrapin 的设计和一些实现细节。感兴趣的朋友欢迎提供您宝贵的意见和建议,同时 Terrapin 已于2015年9月份在 Facebook @Scale 大会上宣布了开源,有兴趣的同学可以去 Github 下关注下( https://github.com/pinterest/terrapin)。

请扫码关注我们的公众号,谢谢!
