

Python中的列表对象是我们编程开发都会遇到的类型,其提供的丰富的方法极大地简化了我们处理数据的过程。但是也很可能在实际使用过程中滥用其特性,降低代码的美观性(说的就是for in)和性能。而对于元组和列表的对比,我们的理解也仅限于可变和不可变,更多的对比,还有待我们探索。
内置序列类型的简单总结
根据存放内容的特性分类:
- 容器序列(Container sequences):
- 如 list, tuple, collections.deque,其特点是可以容纳不同类型的元素
- 扁平序列(Flat sequences):
- 如 str, bytes, bytearray, memoryview, array,array, 只能容纳一个类型的元素
容器序列存放的只是相应对象的引用,而对象本身可以是任意类型。扁平序列则实实在在的把每条元素的值存在了其本身所在的内存中。也因此,扁平序列更加简洁,但他们只能存放原始数据类型,如字符,字节以及数。
根据序列类型是否可变又可以分组为
- 可变序列:list, bytearray, array.array, collections.deque, memoryview
- 不可变序列:tuple, str, bytes
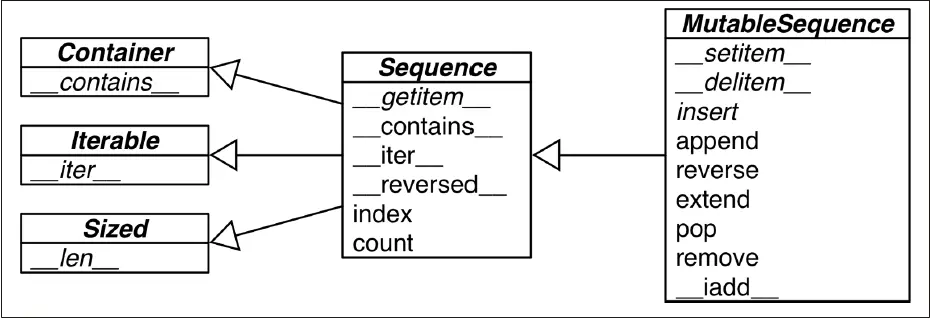
上图并不是真实的继承关系,但是便于理解可变序列和不可变序列的具体区别。和不可变序列相比,可变序列实现了更多的特殊方法,使得我们可以更灵活的操作其中的元素。
列表解析和生成器表达式
列表解析和可读性
# 例子2-1,获取一段字符串中每个字符在Unicode编码下位置的列表
symbols = '$¢£¥€¤'
codes = []
for symbol in symbols:
codes.append(ord(symbol))
print codes对以上代码无需多做解释,当然也还有更加优雅的实现方式,这种方式称为列表解析(list comprehension)
# 例子2-2,获取一段字符串中每个字符在Unicode编码下位置的列表
symbols = '$¢£¥€¤'
codes = [ord(symbol) for symbol in symbols]
print codes小建议:
在 python 中,[], {}, () 内所有的换行都会被忽略。所以我们可以写出很多行的list,而不必使用 '\' 换行号。
在 python 2.x 中,列表解析中的变量赋值会被泄漏到周围的作用域中,这可能会导致一些意想不到的后果。
# python 2.x
x = 'my precious'
dummy = [x for x in 'ABC']
print x # 'C'for 语句中的 x ,被泄漏到了全局作用域中,并且覆盖了已经存在的变量 x 。这在 python 3 中得到了改进
# python 3
x = 'ABC'
dummy = [ord(x) for x in x]
print x # 'ABC'
print dummy # [65, 66, 67]列表解析 VS map filter
列表解析可以在不借助 lambda 表达式的情况下,做到 map 和 filter 能做到的任何事,并且不损失性能。
# 例子2-3,用列表解析和 map/filter 生成列表
symbols = '$¢£¥€¤'
beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
print beyond_ascii # [162, 163, 165, 8364, 164]
beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
print beyond_ascii # [162, 163, 165, 8364, 164]笛卡尔积
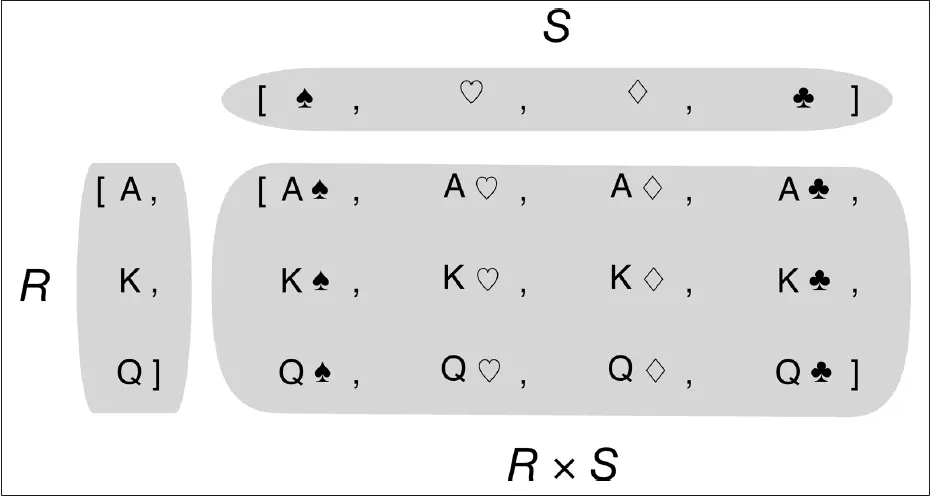
如图所示就是笛卡尔积的图解,而通过列表解析可以非常方便的实现
# 例子2-4,通过列表解析实现笛卡尔积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts = [(color, size) for color in colors for size in sizes] # 注释1
print tshirts
for color in colors: # 注释2
for size in sizes:
print((color, size))
tshirts = [(color, size) for size in sizes for color in colors] # 注释3- 通过列表解析产生了一个元组的列表
- 通过传统的语句产生,和列表解析结果的顺序完全一样
- 注意结果的顺序和之前的不一样
生成器表达式
我们可以直接通过列表解析来初始化元组,数组或者其他的序列类型,但是用生成器更节省空间,因为它通过迭代器协议 (iterator protocol) 一个个地产生 (yield) 元素,而不是生成一整个列表。
生成器的语法和列表解析的语法相同,不同的是生成器表达式由圆括号包裹,而列表解析由方括号包裹。
# 例子2-5,通过生成器表达式建立元组和数组
symbols = '$¢£¥€¤'
tuple(ord(symbol) for symbol in symbols) # (36, 162, 163, 165, 8364, 164) 注释1
import array
array.array('I', (ord(symbol) for symbol in symbols)) # array('I', [36, 162, 163, 165, 8364, 164]) 注释2- 如果生成器表达式是一个函数调用的唯一参数,那么圆括号可以省略
- 数组的构造函数接收两个参数,所以生成器表达式两边的圆括号不能省略。
# 例子2-6,用生成器表达式做笛卡尔积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
print(tshirt)例子 2-6 做了一个简单的笛卡尔积,但是不需要在内存中生成包含六种T恤的列表。当数据量很大的时候,这个可以节省很多内存。
元组不只是不可变列表
我们都习惯性的认为元组是不可变的列表(至少我是这么认为的)。但是还有一个不为人知的意义在于,元组可以当做没有键名的记录。
用元组做记录
元组可以用来存储数据,每条数据的位置信息都是有其意义的。
# 例子2-7,元组做记录
lax_coordinates = (33.9425, -118.408056) # 注释1
city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014) # 注释2
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')] # 注释3
for passport in sorted(traveler_ids): # 注释4
print('%s/%s' % passport) # 注释5
# 输出结果
# BRA/CE342567
# ESP/XDA205856
# USA/31195855
for country, _ in traveler_ids: # 注释6
print(country)
# 输出结果
# USA
# BRA
# ESP- 洛杉矶国际机场的经纬度
- 东京的数据:依次是名称,年份,人口(百万),人口变化率(%),面积(平方公里)
- 由国家编号和护照号码组成的元组列表
- 当我们遍历列表时,passport指的即是每个元组
- % 格式符可以正确的识别元组
- for 循环知道如何将元组中的元素分别取出来,这就是所谓的解包 (unpacking) 。由于我们对元组中的第二条元素不感兴趣,所以用 '_' 来代指。
由于列表良好的解包特性,所以可以用其来存储我们的数据,并且方便的处理
元组解包
最简单明了的元组解包的例子就是平行赋值 (parallel assignment) 。也就是将一个可遍历对象赋值给多个变量。
lax_coordinates = (33.9425, -118.408056)
latitude, longitude = lax_coordinates # tuple unpacking
print(latitude)
33.9425
print(longitude)
-118.408056一元组解包的一个很好应用就是,交换变量的值,而不需要使用一个临时变量
b, a = a, b另一个例子就是,调用函数时,在参数前加星。
divmode(20, 8) # (2,4)
t = (20, 8)
divmode(*t) # (2, 4)
quotient, remainder = divmode(*t)这样方便了函数调用者,可以直接通过相应变量获取结果。这可以带来很多便利,例如打开一个文件
import os
_, filename = os.path.split('/home/luciano/.ssh/idrsa.pub')
print(filename) # 'idrsa.pub'使用星 (*) 来获取超出的元素
在 python 3 中,* 可以直接用在平行赋值中。
a, b, *rest = range(5)
a, b, rest # (0, 1, [2, 3, 4])
a, b, *rest = range(3)
a, b, rest # (0, 1, [2])
a, b, *rest = range(2)
a, b, rest # (0, 1, [])平行赋值的时候,* 前缀的变量还可以放在其他位置,不一定必须得是末尾
a, *body, c, d = range(5)
a, body, c, d # (0, [1, 2], 3, 4)
*head, b, c, d = range(5)
head, b, c, d # ([0, 1], 2, 3, 4)上面的代码只限 python 3 ,python 2 运行会失败,sad。
嵌套元组的解包
# 例子2-8,解包嵌套元组来获取经度
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
] # 注释1
print('{:15} | {:^9} | {:^9}'.format('', 'lat.', 'long.'))
fmt = '{:15} | {:9.4f} | {:9.4f}'
for name, cc, pop, (latitude, longitude) in metro_areas: # 注释2
if longitude <= 0: # 注释3
print(fmt.format(name, latitude, longitude))- 每个元组包含四个域,最后一个域是经纬度信息
- 把最后一个域赋值给一个元组,就可以将对应的经纬度信息解包出来
- 只输出西半球的信息
最后的输出为:
| lat. | long.
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
Sao Paulo | -23.5478 | -46.6358有键名的元组
上一篇博客有说到 collections.namedtuple ,用这个可以实现有键名的元组
# 例子2-9,定义和使用有键名的元组类型
from collections import namedtuple
City = namedtuple('City', 'name country population coordinates') # 注释1
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667)) # 注释2
print tokyo # City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722,
139.691667))
print tokyo.population # 36.933 注释3
print tokyo.coordinates # (35.689722, 139.691667)
print tokyo[1] # 'JP'- 创建一个有键名的元组需要两个参数,类名和一个键名列表。键名可以通过一个可遍历的字符串列表或者用空格分隔开的字符串来给出。
- 数据必须按照对应的位置给出,作为比较,元组的构造函数只需要一个可遍历对象作为参数
- 可以通过键的名称,或者键所在的位置直接获取数据
一个有键名的元组还有若干方法和属性。
# 例子2-10,有键名元组的属性和方法
print City._fields # ('name', 'country', 'population', 'coordinates') 注释1
LatLong = namedtuple('LatLong', 'lat long')
delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
delhi = City._make(delhi_data) # 注释2
print delhi._asdict() # 注释3
# 输出
# OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
for key, value in delhi._asdict().items():
print(key + ':', value)
# 输出
# name: Delhi NCR
# country: IN
# population: 21.935
# coordinates: LatLong(lat=28.613889, long=77.208889)- _fields 是键名组成的元组
- _make() 使我们可以直接通过一个可遍历对象来创建一个有键名的元组
- _asdict() 返回一个由这个带键名元组实例产生的
collections.OrderedDict
不可变的列表:元组
对于这个话题,我们已经很熟悉了,下图直接给出了两者的不同之处


源码的github地址
源代码
以上源代码均来自于 fluent python 一书,仅为方便阅读之用。如侵删。
