

本篇文章是讨论热门机器学习算法的文章合集中的一篇。如果你想了解更加详尽的背景知识以及我的写作初衷,请阅读这篇文章。
背景
隐含狄利克雷分布(LDA)算法曾被"提出"过两次,第一次提出是在2000年,用来根据遗传信息将人群划分至K个种族,到了2003年,LDA又一次被提出,用来在文本语料库中构建主题模型。而在本篇文章中,我将专注于主题建模部分的介绍。但是LDA在众多领域有着极为广泛的应用,遗传应用也是其中非常有趣的一个方向。前面提到的分别提出了LDA的论文如下:
- Pritchard, Jonathan K., Matthew Stephens, and Peter Donnelly. "Inference of population structure using multilocus genotype data." Genetics 155.2 (2000): 945–959
- Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation." Journal of machine Learning research 3.Jan (2003): 993–1022
在本篇文章中,我将根据第二篇论文的内容向大家介绍LDA算法。
总体而言
在开始之前,让我们看看LDA算法的黑盒描述。LDA算法要求你选择一些类(主题)并输入一个文档语料库。它的输出是一个主题的列表,每一个主题都是基于单词的概率分布。LDA模型也能够对文档进行分类,并为每个主题分配一个概率值。
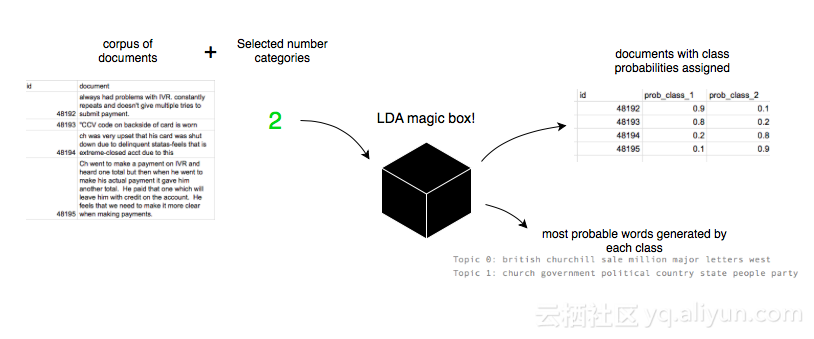
上述描述的可视化表示。算法中会有更多的超参数需要调整,但在这里我们暂时不用考虑它们。
看起来不错!我们现在就搞定它吧。。。但是,先等等。。。

需要注意的一点是,LDA算法并不能保证主题应该是什么,对你的语料库而言也无法保证主题的数量是否充分。在这里,我们通过人类的直觉以及一些优秀的数学优化方法来确定主题,并判断这些主题是否能够被模型充分表示。
你掌握的那些常用的数据科学技巧或许能解决这些问题。我们会得到一些输出结果,这些结果看起来似乎都还不错。
但是,请记住,常用的技巧并不一定就能取得最好的结果,我们接下来会解决这个问题。
理论
LDA是一种生成式概率模型。如果你并不了解什么是生成模型,或者生成模型与判别模型之间的区别,这里有一篇不错的文章,你可以参考下。
给定主题建模的上下文,我们假设所有文档均是一些隐含或潜在变量(主题、主题分配以及主题比例)相互影响的结果(由这些变量生成)。
但是在一开始的时候,我们并不知道那些隐含变量都是什么。我们手头只有一份语料库。为了生成这些隐含变量,我们可以使用统计推断的方法。具体来说,我们将采用吉布斯采样以及变分推断这些近似后验推断的方法。在这里,我不打算深入讨论这些算法的实现。有了神奇的社区,你也不大可能需要自己实现这些算法,但是这能够帮助你很好地理解下面将要介绍的方法。
一些要点:
- 一篇文档可以也通常属于多个主题
- 每个主题都通过一个关于固定词库中各个词的概率分布来表示。这是什么意思呢?对于任意一个主题X,我们可以得到词库中n个词在这个主题下的概率,而它们的概率之和为1。这也意味着我们必须提前确定一个固定的词库。
- 在主题建模时,我们还会将我们的文本数据以词袋的形式进行分析。词序在这里并不重要。
在构建LDA模型的最后,我们会得到一个概率模型,给定我们问题空间中的一篇文档,我们可以得到文档主题的概率分布。
按照Blei等人发表论文中的逻辑顺序,一旦我们构建了LDA模型,语料库中的每篇文档均可通过以下方式生成:

文本语料库中,生成每篇文档需采取的步骤描述。— D. Blei, A. Ng, and M. Jordan. Latent Dirichlet allocation. Journal of Machine Learning Research, 3:993–1022, January 2003
其中,N表示确定词库中单词的总数。我们根据训练语料库中各个词的出现情况来确定词库,进而设置这个值。一般来说,在删除停用词后,我们会提取词干并进行预处理的步骤,具体细节会在下面的实现章节中介绍。你可能还需要删除那些几乎在所有文档中都出现过的词,因为这些词并不会提高模型的判别能力。另一种常见的做法是删除非常罕见的词。在这里不需要过于担心泊松分布。只需要记住N是确定的单词数量即可。
θ表示一个随机的狄利克雷分布,通过一个长度为K的向量α进行参数化。K为我们已经选择出的主题总量。
之后,n从1到N
- 我们从一个由θ参数化的离散(多项式)分布中选择一个主题Zn。注意,在这里我们根据已观察到的一些信息随机选择一个主题。
- 根据所选择主题的条件概率,我们从中选择一个词
根据这个理论模型,如果我们想要生成100篇文档,那么它真的就会生成100篇实际的文档,每篇文档含有N个词,每个词都由一些主题根据其概率分布随机生成。正如论文中所描述的,文档中的每个词都基于预先存在的关于主题与单词的矩阵计算得到。
如果你和我当初一样,刚开始尝试理解这些理论,你现在可能是这个样子:

诚然,这些理论需要花费大量的时间反复研究。但它们是LDA模型的基础。我们显然还没有构建主题所需的概率分布,不过我们很快就能得到它们。
定理
在这里澄清一点,我在本文中使用的"定理"可与假设以及基本构成元素这些概念互换,以便大家更好地理解。
除了要理解多项式分布与狄利克雷分布的基本知识以及它们的共轭性质外,可交换性也是需要深入理解的关键概念。也就是说,LDA以混合模型的形式构建,该模型认为主题与单词(随机变量)间是可交换的。
这个基本性质基于菲尼蒂定理,其对概率推断有着更为广泛的适用性。我建议你深入研究菲尼蒂定理。这肯定能加深你对概率的整体理解。
公式
LDA论文中有许多公式,但是我发现这些公式用盘子表示法表示时,会变得容易理解得多。
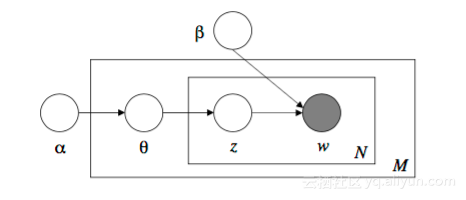
上述生成模型的盘子表示法。阴影节点表示模型中唯一被观察到的变量。
而且,我们在建模过程中遇到的棘手问题(找到隐含变量的后验概率)也因此得以解决。
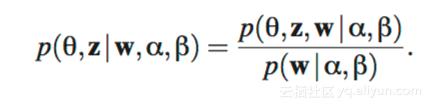
我们可以使用变分推断的方法来估计这些隐含的参数。坦白地说,我对该方法的描述远不如我看到的约旦人Boyd-Graber对这一过程的完美阐述。这是一部30多分钟的视频,它涵盖了平均场变分推断的基础知识:KL散度以及 Jensen不等式,甚至还包括了它们在LDA中的应用。视频链接在 这里。
现实世界中使用的LDA变种与示例
- 空间隐含狄利克雷分布:一个有趣的计算机视觉示例,在图像数据上应用LDA模型,将视觉单词分类至高层次的主题当中。
- 隐含狄利克雷分布的在线学习:用于处理流数据的变分贝叶斯算法的在线方法。嵌入实时的应用程序后,在线方法总是能够生成很有趣的结果。
- 图形处理单元上隐含狄利克雷分布的并行推断:论文讨论了两种用于LDA的并行推断方法:吉布斯采样与变分贝叶斯。并不是LDA算法的普通变种,但是对于那些想要使用更大语料库的人来说,效果非常显著(算法加速20倍)。
实现
在这个例子中,我打算使用一份有趣的数据集,这份数据集总共包含了由国家UFO报告中心(NUFORC)提供的超过8万份的UFO目击报告。感谢Sigmoid Axel对数据集进行的整理与清洗工作,同时也感谢Oliver Cameron在这篇文章中提到了这份数据集,这引起了我的注意。

外星人来到地球只是为了寻找爱情。不要害怕️
这里有一些有趣的报告片段。我保留了它们的原始格式,以便于向你展示自由格式文本字段生成的数据示例。
"电视节目上有一个可能异常的物体"
可能是一个正在创作的人工制品,也可能是昨晚吃的千层面粘到了屏幕上。报告得再详细一点。
"这里出现了猴子,它们不应该'出现,在这里,其他人也看到了"
无法解释的猴子。一定是外星人。
"我看到一个四周闪着光的蓝色星星缓缓移动它在天空中央停顿了两秒钟然后向西飞去发出了五颜六色的光芒随后光源慢慢变暗"
没有时间加空格了——大家一定能读懂!
这里也有一个内容详实而且描述得比较清楚的例子:
"三个白色光源呈三角队形指向下方的一个绿色光源。光源并不闪烁,只发出普通的光线"

上面的例子可以很好地向你说明了非学术领域种的文本语料库是什么样子。我们看到了一些编码字符&#..、错误的单词拼写以及一些根本不知道在说些什么的报告。
对于LDA模型而言,输入质量与输出质量等同非常重要,这一点应该牢记。我们可使用预处理步骤来提高文本语料的质量。
接下来,我将使用优秀的文本挖掘工具库gensim。gensim不仅提供了现成可用的LDA算法实现,还提供一个不错的用于流式主题建模的API、一些用于创建不同格式语料库的便捷工具、TF-IDF算法的实现以及其他许多有用的功能。如果你使用Python来进行数据科学的学习,而且还没有了解过这个工具库,它绝对值得你留意。
特征预处理
这些预处理步骤适用于任何以简单词袋形式表示的数据作为输入的机器智能问题。
基本文本预处理操作
- 断词:从用于标准词袋表征的一元词串开始。正如前面引用论文的介绍,这种方法可以推广至n元词串或者文本段落。
- 删除停用词。
- 提取词干或词形还原:你可能想对语料进行更进一步的处理,简化单词以达到更高层面的表示。在我们这个简单的语料库中,light、lighter和lights这样的单词都应该统一简化成light。在这种情况下,我删除了这些词,因为几乎在每篇文档中都能找到这些单词。
- 扩展/替换缩略语:我发现在现实生活中一些特定领域的语料库中,缩略语的使用非常频繁,这可能需要一些学科问题专家来帮助理解这些词。
工具库的具体应用
使用gensim时,我们需要确保我们的语料库文件满足gensim库要求的格式。这里有一些不错的教程,介绍如何使用genism。
调整超参数
有一对非常关键的超参数需要我们确定:
1. K,用来表示我们语料库中隐含主题的数量
2. α,狄利克雷参数
幸运的是,我们使用的gensim工具库提供了一个API,可根据我们使用的训练数据自动估计α参数的取值。
然而,要优化K参数的取值,我们只能慢慢来。虽然有一些计算方法可以用来求解K,但这些方法通常会产生不同的K值,并根据困惑度的度量重新进行训练。
直观地说,随着我们增加主题的数量,困惑度也应随之降低。然而,我们最终会陷入过拟合的状态,无法进一步提高模型的泛化能力。
我最后使用了不同的K值来训练模型,在检查每个主题的困惑度以及产生的标记数组后,我最终选出了20个主题。
结果
在展示结果之前我想说,模型结果的质量并不是最好的。但这没有关系。稍加处理就可以让结果看起来更好。
首先,我不得不从词库中剔除许多单词。词库往往含有大量拼写错误的单词。有些拼写错误可以用nltk解决,但有时nltk没那么有效,甚至不起作用。如果你仔细查看我在文章末尾给出的github gist,你会看到我的处理方式。
此外,有一些文本描述的长度很短,仅由几个单词构成,也有一些描述不完整。我不知道这是否是由于数据库中字段的字符数限制所导致的,或者是在数据导出的过程中造成的。
最终主题、概率较高的标记以及我对这些结果的理解如下。为了理解这些结果的含义,我查看了一些关于这些标记的描述,发现这些结果非常准确!
1.银色雪茄
0.113*"形状" + 0.058*"飞行器" + 0.033*"雪茄" + 0.027*"银色" + 0.016*"看到" + 0.016*"两个" + 0.015*"碟状物" + 0.014*"飞行" + 0.013*"物体" + 0.012*"高"
2.快速移动的三角形
0.059*"速度" + 0.053*"高" + 0.051*"移动" + 0.032*"快" + 0.027*"编队" + 0.026*"三角形" + 0.024*"白色" + 0.017*"速度" + 0.014*"海拔" + 0.014*"穿过"
3.房间内部看到的UFO
0.041*"看到" + 0.016*"外面" + 0.015*"晚上" + 0.015*"朋友" + 0.014*"发现" + 0.014*"房间" + 0.013*"家" + 0.012*"刚刚" + 0.011*"看见" + 0.010*"窗户"
4.海岸附近的UFO
0.029*"红色" + 0.028*"海岸" + 0.027*"像" + 0.020*"大海" + 0.017*"三角形" + 0.016*"看到" + 0.012*"橙色" + 0.012*"旧金山" + 0.011*"飞行" + 0.010*"黑色"
5.爱国UFO!
0.062*"白色" + 0.036*"蓝色" + 0.035*"红色" + 0.030*"闪光" + 0.022*"圆盘" + 0.022*"放大" + 0.020*"绿色" + 0.018*"形状" + 0.015*"椭圆" + 0.013*"徘徊"
6.来自加拿大的报告
0.048*"晚上" + 0.026*"报告" + 0.023*"湖" + 0.022*"物体" + 0.022*"时间" + 0.019*"三个" + 0.012*"奇怪" + 0.011*"加拿大" + 0.010*"hbcc" + 0.010*"橙色"
7.喷气式三角形飞行器
0.027*"喷气式" + 0.024*"白色" + 0.022*"汽车" + 0.021*"红色" + 0.017*"方向" + 0.017*"前面" + 0.016*"飞行器" + 0.013*"底部" + 0.011*"三角形" + 0.011*"形状"
8.白天出现的UFO
0.030*"飞行器" + 0.024*"附近" + 0.023*"三个" + 0.021*"白天" + 0.019*"近" + 0.015*"物体" + 0.013*"未知" + 0.012*"徘徊" + 0.011*"两个" + 0.011*"观察到"
9.模糊不清/烟雾
0.039*"云" + 0.019*"发现" + 0.016*"空白" + 0.014*"轨迹" + 0.013*"北" + 0.013*"看到" + 0.011*"看见" + 0.010*"两个" + 0.009*"烟雾" + 0.009*"推动"
10.闪着光的UFO
0.059*"移动" + 0.053*"闪光" + 0.039*"形状" + 0.035*"颜色" + 0.031*"红色" + 0.025*"变化" + 0.023*"白色" + 0.016*"慢" + 0.014*"蓝色" + 0.014*"快"
11.黑色三角形
0.020*"右侧" + 0.019*"移动" + 0.018*"水平" + 0.017*"黑色" + 0.017*"缓慢" + 0.017*"你" + 0.016*"树" + 0.016*"左侧" + 0.015*"三角形" + 0.015*"线"
12.德克萨斯UFO
0.049*"西" + 0.048*"目睹" + 0.044*"东" + 0.020*"南" + 0.019*"移动" + 0.018*"北" + 0.014*"彩色的" + 0.013*"行进" + 0.011*"德克萨斯" + 0.011*"近"
13.橙色与红色的环形
0.063*"分钟" + 0.027*"橙色" + 0.023*"红色" + 0.023*"移动" + 0.017*"闪烁" + 0.017*"两个" + 0.014*"看到" + 0.014*"环形" + 0.013*"白色" + 0.012*"巨大"
14.可能的流星或太空垃圾
0.082*"星星" + 0.081*"像" + 0.036*"移动" + 0.028*"滑行" + 0.025*"看到" + 0.018*"看见" + 0.015*"射向" + 0.012*"运动" + 0.011*"认为" + 0.011*"慢"
15.火球
0.114*"橙色" + 0.057*"球形" + 0.034*"炽热的" + 0.024*"编队" + 0.024*"移动" + 0.023*"红色" + 0.019*"穿过" + 0.018*"物体" + 0.017*"飞行" + 0.015*"两个"
16.红色或白色低空飞行的物体
0.049*"飞行" + 0.041*"低" + 0.036*"白色" + 0.026*"噪声" + 0.022*"红色" + 0.019*"听" + 0.017*"橙色" + 0.016*"飞行器" + 0.014*"巨大" + 0.013*"地面"
17.单个飞行器间编队飞行
0.065*"一个" + 0.028*"两个" + 0.016*"移动" + 0.015*"另一个" + 0.015*"转" + 0.012*"回" + 0.012*"急转" + 0.012*"物体" + 0.011*"运动" + 0.011*"模式"
18.月亮火球
0.051*"球" + 0.023*"看见" + 0.022*"橙色" + 0.021*"移动" + 0.021*"火" + 0.017*"消失" + 0.016*"穿过" + 0.016*"白色" + 0.016*"球体" + 0.015*"月亮"
19.金星目击报告
0.073*"记录" + 0.073*"nuforc" + 0.072*"局部" + 0.029*"目睹" + 0.029*"可能" + 0.024*"奇怪的" + 0.021*"星星" + 0.014*"报告" + 0.012*"金星" + 0.010*"看到"
20.许多彩色光
0.087*"看见" + 0.070*"火球" + 0.040*"绿色" + 0.025*"红色" + 0.023*"橙色" + 0.018*"飞行器" + 0.015*"巨大" + 0.013*"三角形" + 0.012*"蓝色" + 0.011*"穿过"
现在,让我们来看一些人们的推理。声明:除了偶尔看看X档案的电视剧,我从未真正研究过UFO现象。所以,让我们看看我们能联想到什么。
- 银色雪茄:UFO观察者社区已经对这些UFO进行了明确的分类。在谷歌上随便查一下雪茄形UFO就能找到大量的结果。考虑到这些报告没有使用其他描述性术语,如圆柱形、管状等,我猜测它们来自那些受UFO文化影响的观察者。因此,当他们在天空中看到一个无法分类至常见类别的物体时,如飞机、小鸟或者超人,他们就会默认把它归为雪茄形UFO。当然,这不是说雪茄形状的飞行器不存在。这里甚至还有一篇哈芬登邮报关于乌克兰目击者的文章,有视频!
- 快速移动的三角形:也是社区中的另一类UFO。我猜很可能是军用飞机。比如可能是B-2隐形轰炸机"精灵"或F-117战斗机"夜莺"。
- 房间内部看到的UFO:没什么特别有趣的,都是些关于人们在房间内部看到的飞行器的目击报告。
- 海岸附近的UFO:这些也没什么特别好玩的,关于在海边看到UFO的目击报告。
- 爱国UFO!:在这里我大胆地称这些UFO是爱国的,因为有关它们的目击报告提到了蓝色的灯光。标准的航空灯都是白色、红色和绿色的。没有蓝色。而美国国旗则由白色、红色和蓝色组成。我们仔细想一想——一种可能的解释是色觉辨认障碍,目击者受色盲的影响误将可见光谱中的绿色识别成了蓝色。虽然这是一种罕见的遗传性状,但色盲患者可能比我们想象中更多。当然,这也可能是外星人。
- 来自加拿大的报告:似乎是从另外一个系统中导出的,这些报告使用了一些标准的格式。
- 喷气式三角形飞行器:军用飞机通常按编队飞行。
- 白天出现的UFO:除了悬浮飞行器,没什么让人感兴趣的。
- 模糊不清/烟雾:这些报告描述的要么是不规则形状的飞行器,要么是飞行器留下的凝结尾迹。
- 闪着光的UFO:飞机的照明设备一般都会闪光,唉。
- 黑色三角形:UFO观察者社区定义的另一种UFO。报告可能受到人们对UFO超科学越来越大的兴趣影响。此外,这类UFO可能是"快速移动的三角形"这一主题里面提到的隐形战斗机。
- 德克萨斯UFO:出现在德克萨斯州的UFO——清澈的天空、居住在德克萨斯州的大部分居民。美国有大量空军基地都建在这里。可能是这个原因导致的。
- 橙色和红色的环形:这是另一类经常被观察到的UFO:火球形UFO。可能的情况有很多——太空垃圾或者陨石。几乎任何进入地球大气层的东西都会因为大气层摩擦而燃烧。
- 可能的流星或太空垃圾:这些报告仅仅提到了类似"像星星一样"的描述。
- 火球:橙色或红色的球状物都可归为火球这一类。
- 红色或白色低空飞行的物体:这里的低空飞行指的要么是飞行轨迹,比如"飞向地面",要么是飞行高度,比如"距离地面较近地飞行"。
- 单个飞行器间编队飞行:更多关于飞行器编队飞行的目击报告。
- **月亮火球:围绕月亮运动的火球UFO。
- 金星目击报告:这些可能是与金星相关的目击报告的追加描述。
- 许多彩色光:里面的描述似乎是火球UFO与其他发出各种彩色光的UFO的目击报告的混合。
可见,我们的LDA模型能够成功找到一些常见的UFO种类。机器学习方法证明了外星人的存在了吗?这并不好说。
我对这个LDA模型使用的UFO目击报告描述还有一些别的猜想和问题,但光有这些描述是不够的,可能只有在完整数据集中才能找到答案。也希望有人能够公开这份数据。
- 这些UFO目击事件的发生在时间和空间上有联系吗?比如,是否有特定的飞行器会在相似的时间或地点出现?
- 这些UFO目击事件都发生在美国空军基地附近吗?
如果你也打算分析这份数据,一定要告诉我!
我想说,如果我是一个穿越整个宇宙来到地球的外星人,我才不会漫无目的地在美国偏远地区浪费时间,也不愿意让人类注意到我。我宁可去伊维萨岛的夜总会跳舞。要知道,星际旅行可不便宜。
我用来构建模型的github gist在这里,请随意修改!
你也可以在Twitter上找到我!如果你喜欢这篇文章,欢迎分享。
以上为译文
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Optimal Data Science: Latent Dirichlet Allocation》,作者:Sam,译者:6816816151
文章为简译,更为详细的内容,请查看原文
