

LRU 是 Least Recently Used 最近最少使用算法。使用当成一个 Map 用就可以了,只不过实现了 LRU 缓存策略。
源码中文注释
package com.camnter.newlife.utils.cache;
import java.util.LinkedHashMap;
import java.util.Map;
public class LruCache {
private final LinkedHashMap map;
/**
* 缓存大小的单位。不规定元素的数量。
*/
// 已经存储的数据大小
private int size;
// 最大存储大小
private int maxSize;
// 调用put的次数
private int putCount;
// 调用create的次数
private int createCount;
// 收回的次数 (如果出现)
private int evictionCount;
// 命中的次数(取出数据的成功次数)
private int hitCount;
// 丢失的次数(取出数据的丢失次数)
private int missCount;
/**
* LruCache的构造方法:需要传入最大缓存个数
*/
public LruCache(int maxSize) {
// 最大缓存个数小于0,会抛出IllegalArgumentException
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
/*
* 初始化LinkedHashMap
* 第一个参数:initialCapacity,初始大小
* 第二个参数:loadFactor,负载因子=0.75f
* 第三个参数:accessOrder=true,基于访问顺序;accessOrder=false,基于插入顺序
*/
this.map = new LinkedHashMap(0, 0.75f, true);
}
/**
* 设置缓存的大小。
*/
public void resize(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
// 防止外部多线程的情况下设置缓存大小造成的线程不安全
synchronized (this) {
this.maxSize = maxSize;
}
// 重整数据
trimToSize(maxSize);
}
/**
* 根据key查询缓存,如果存在于缓存或者被create方法创建了。
* 如果值返回了,那么它将被移动到双向循环链表的的尾部。
* 如果如果没有缓存的值,则返回null。
*/
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
// LinkHashMap 如果设置按照访问顺序的话,这里每次get都会重整数据顺序
mapValue = map.get(key);
// 计算 命中次数
if (mapValue != null) {
hitCount++;
return mapValue;
}
// 计算 丢失次数
missCount++;
}
/*
* 官方解释:
* 尝试创建一个值,这可能需要很长时间,并且Map可能在create()返回的值时有所不同。如果在create()执行的时
* 候,一个冲突的值被添加到Map,我们在Map中删除这个值,释放被创造的值。
*/
V createdValue = create(key);
if (createdValue == null) {
return null;
}
/***************************
* 不覆写create方法走不到下面 *
***************************/
/*
* 正常情况走不到这里
* 走到这里的话 说明 实现了自定义的 create(K key) 逻辑
* 因为默认的 create(K key) 逻辑为null
*/
synchronized (this) {
// 记录 create 的次数
createCount++;
// 将自定义create创建的值,放入LinkedHashMap中,如果key已经存在,会返回 之前相同key 的值
mapValue = map.put(key, createdValue);
// 如果之前存在相同key的value,即有冲突。
if (mapValue != null) {
/*
* 有冲突
* 所以 撤销 刚才的 操作
* 将 之前相同key 的值 重新放回去
*/
map.put(key, mapValue);
} else {
// 拿到键值对,计算出在容量中的相对长度,然后加上
size += safeSizeOf(key, createdValue);
}
}
// 如果上面 判断出了 将要放入的值发生冲突
if (mapValue != null) {
/*
* 刚才create的值被删除了,原来的 之前相同key 的值被重新添加回去了
* 告诉 自定义 的 entryRemoved 方法
*/
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
// 上面 进行了 size += 操作 所以这里要重整长度
trimToSize(maxSize);
return createdValue;
}
}
/**
* 给对应key缓存value,该value将被移动到队头。
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
// 记录 put 的次数
putCount++;
// 拿到键值对,计算出在容量中的相对长度,然后加上
size += safeSizeOf(key, value);
/*
* 放入 key value
* 如果 之前存在key 则返回 之前key 的value
* 记录在 previous
*/
previous = map.put(key, value);
// 如果存在冲突
if (previous != null) {
// 计算出 冲突键值 在容量中的相对长度,然后减去
size -= safeSizeOf(key, previous);
}
}
// 如果上面发生冲突
if (previous != null) {
/*
* previous值被剔除了,此次添加的 value 已经作为key的 新值
* 告诉 自定义 的 entryRemoved 方法
*/
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
/**
* 删除最旧的数据直到剩余的数据的总数以下要求的大小。
*/
public void trimToSize(int maxSize) {
/*
* 这是一个死循环,
* 1.只有 扩容 的情况下能立即跳出
* 2.非扩容的情况下,map的数据会一个一个删除,直到map里没有值了,就会跳出
*/
while (true) {
K key;
V value;
synchronized (this) {
// 在重新调整容量大小前,本身容量就为空的话,会出异常的。
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(
getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
// 如果是 扩容 或者 map为空了,就会中断,因为扩容不会涉及到丢弃数据的情况
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
// 拿到键值对,计算出在容量中的相对长度,然后减去。
size -= safeSizeOf(key, value);
// 添加一次收回次数
evictionCount++;
}
/*
* 将最后一次删除的最少访问数据回调出去
*/
entryRemoved(true, key, value, null);
}
}
/**
* 如果对应key的entry存在,则删除。
*/
public final V remove(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V previous;
synchronized (this) {
// 移除对应 键值对 ,并将移除的value 存放在 previous
previous = map.remove(key);
if (previous != null) {
// 拿到键值对,计算出在容量中的相对长度,然后减去。
size -= safeSizeOf(key, previous);
}
}
// 如果 Map 中存在 该key ,并且成功移除了
if (previous != null) {
/*
* 会通知 自定义的 entryRemoved
* previous 已经被删除了
*/
entryRemoved(false, key, previous, null);
}
return previous;
}
/**
* 1.当被回收或者删掉时调用。该方法当value被回收释放存储空间时被remove调用
* 或者替换条目值时put调用,默认实现什么都没做。
* 2.该方法没用同步调用,如果其他线程访问缓存时,该方法也会执行。
* 3.evicted=true:如果该条目被删除空间 (表示 进行了trimToSize or remove) evicted=false:put冲突后 或 get里成功create后
* 导致
* 4.newValue!=null,那么则被put()或get()调用。
*/
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {
}
/**
* 1.缓存丢失之后计算相应的key的value后调用。
* 返回计算后的值,如果没有value可以计算返回null。
* 默认的实现返回null。
* 2.该方法没用同步调用,如果其他线程访问缓存时,该方法也会执行。
* 3.当这个方法返回的时候,如果对应key的value存在缓存内,被创建的value将会被entryRemoved()释放或者丢弃。
* 这情况可以发生在多线程在同一时间上请求相同key(导致多个value被创建了),或者单线程中调用了put()去创建一个
* 相同key的value
*/
protected V create(K key) {
return null;
}
/**
* 计算 该 键值对 的相对长度
* 如果不覆写 sizeOf 实现特殊逻辑的话,默认长度是1。
*/
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
/**
* 返回条目在用户定义单位的大小。默认实现返回1,这样的大小是条目的数量并且最大的大小是条目的最大数量。
* 一个条目的大小必须不能在缓存中改变
*/
protected int sizeOf(K key, V value) {
return 1;
}
/**
* Clear the cache, calling {@link #entryRemoved} on each removed entry.
* 清理缓存
*/
public final void evictAll() {
trimToSize(-1); // -1 will evict 0-sized elements
}
/**
* 对于这个缓存,如果不覆写sizeOf()方法,这个方法返回的是条目的在缓存中的数量。但是对于其他缓存,返回的是
* 条目在缓存中大小的总和。
*/
public synchronized final int size() {
return size;
}
/**
* 对于这个缓存,如果不覆写sizeOf()方法,这个方法返回的是条目的在缓存中的最大数量。但是对于其他缓存,返回的是
* 条目在缓存中最大大小的总和。
*/
public synchronized final int maxSize() {
return maxSize;
}
/**
* Returns the number of times {@link #get} returned a value that was
* already present in the cache.
* 返回的次数{@link #get}这是返回一个值在缓存中已经存在。
*/
public synchronized final int hitCount() {
return hitCount;
}
/**
* 返回的次数{@link #get}返回null或需要一个新的要创建价值。
*/
public synchronized final int missCount() {
return missCount;
}
/**
* 返回的次数{@link #create(Object)}返回一个值。
*/
public synchronized final int createCount() {
return createCount;
}
/**
* 返回put的次数。
*/
public synchronized final int putCount() {
return putCount;
}
/**
* 返回被收回的value数量。
*/
public synchronized final int evictionCount() {
return evictionCount;
}
/**
* 返回当前缓存内容的一个副本,从最近很少访问到最最近经常访问。
*/
public synchronized final Map snapshot() {
return new LinkedHashMap(map);
}
@Override public synchronized final String toString() {
int accesses = hitCount + missCount;
int hitPercent = accesses != 0 ? (100 * hitCount / accesses) : 0;
return String.format("LruCache[maxSize=%d,hits=%d,misses=%d,hitRate=%d%%]", maxSize,
hitCount, missCount, hitPercent);
}
}简单使用
使用的时候记住几点即可:
- (必填)你需要提供一个缓存容量作为构造参数。
- (必填) 覆写 sizeOf 方法 ,自定义设计一条数据放进来的容量计算,如果不覆写就无法预知数据的容量,不能保证缓存容量限定在最大容量以内。
- (选填) 覆写 entryRemoved 方法 ,你可以知道最少使用的缓存被清除时的数据( evicted, key, oldValue, newVaule )。
- (记住)LruCache是线程安全的,在内部的 get、put、remove 包括 trimToSize 都是安全的(因为都上锁了)。
- (选填) 还有就是覆写 create 方法 。一般做到 1、2、3、4就足够了,5可以无视 。
private static final float ONE_MIB = 1024 * 1024;
// 7MB
private static final int CACHE_SIZE = (int) (7 * ONE_MIB);
private LruCache bitmapCache;
this.bitmapCache = new LruCache(CACHE_SIZE) {
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
//自定义逻辑
//1.当被回收或者删掉时调用。该方法当value被回收释放存储空间时被remove调用或者替换条目值时put调用,默认实现什么都没做。
//2.该方法没用同步调用,如果其他线程访问缓存时,该方法也会执行。
@Override
protected void entryRemoved(boolean evicted, String key, Bitmap oldValue, Bitmap newValue) {
...
}
};LinkedHashMap
继承自HashMap,一个有序的Map接口实现,这里的有序指的是元素可以按插入顺序或访问顺序排列;与HashMap的异同:同样是基于散列表实现,区别是,LinkedHashMap内部多了一个双向循环链表的维护,该链表是有序的,可以按元素插入顺序或元素最近访问顺序(LRU)排列,简单地说:LinkedHashMap=散列表+循环双向链表用画图工具简单画了下散列表和循环双向链表,如下图,简单说明下:第一张图是LinkedHashMap的全部数据结构,包含散列表和循环双向链表,由于循环双向链表线条太多了,不好画,简单的画了一个节点(黄色圈出来的)示意一下,注意左边的红色箭头引用为Entry节点对象的next引用(散列表中的单链表),绿色线条为Entry节点对象的before, after引用(循环双向链表的前后引用);
第二张图专门把循环双向链表抽取出来,直观一点,注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口;
源码分析
LruCache原理概要解析
LruCache 就是 利用 LinkedHashMap 的一个特性( accessOrder=true 基于访问顺序 )再加上对 LinkedHashMap 的数据操作上锁实现的缓存策略。LruCache 的数据缓存是内存中的。
- 首先设置了内部
LinkedHashMap构造参数accessOrder=true,保证了Map内部基于访问顺序,按照访问顺序逆序排列。也就是说,最近访问的元素排在Map的最后。当需要删除元素时,将会从头部开始删除。正是这个特性,使得通过LinkedHashMap可以实现LRU算法。- 然后在每次
LruCache.get(K key)方法里都会调用LinkedHashMap.get(Object key)。- 如上述设置了
accessOrder=true后,每次LinkedHashMap.get(Object key)都会进行LinkedHashMap.makeTail(LinkedEntry<K, V> e)。LinkedHashMap是双向循环链表,然后每次LruCache.get->LinkedHashMap.get的数据就被放到最末尾了。- 在
put和trimToSize的方法执行下,如果发生数据量移除,会优先移除掉最前面的数据(因为最新访问的数据在尾部)。
LruCache的唯一构造方法
/**
* LruCache的构造方法:需要传入最大缓存个数
*/
public LruCache(int maxSize) {
...
this.maxSize = maxSize;
/*
* 初始化LinkedHashMap
* 第一个参数:initialCapacity,初始大小
* 第二个参数:loadFactor,负载因子=0.75f
* 第三个参数:accessOrder=true,基于访问顺序;accessOrder=false,基于插入顺序
*/
this.map = new LinkedHashMap(0, 0.75f, true);
}第一个参数
initialCapacity用于初始化该 LinkedHashMap 的大小。先简单介绍一下 第二个参数loadFactor,这个其实的 HashMap 里的构造参数,涉及到扩容问题,比如 HashMap 的最大容量是100,那么这里设置0.75f的话,到75容量的时候就会扩容。主要是第三个参数accessOrder=true,这样的话 LinkedHashMap 数据排序就会基于数据的访问顺序,从而实现了 LruCache 核心工作原理。
LruCache.get(K key)
/**
* 根据 key 查询缓存,如果存在于缓存或者被 create 方法创建了。
* 如果值返回了,那么它将被移动到双向循环链表的的尾部。
* 如果如果没有缓存的值,则返回 null。
*/
public final V get(K key) {
...
V mapValue;
synchronized (this) {
// 关键点:LinkedHashMap每次get都会基于访问顺序来重整数据顺序
mapValue = map.get(key);
// 计算 命中次数
if (mapValue != null) {
hitCount++;
return mapValue;
}
// 计算 丢失次数
missCount++;
}
/*
* 官方解释:
* 尝试创建一个值,这可能需要很长时间,并且Map可能在create()返回的值时有所不同。如果在create()执行的时
* 候,一个冲突的值被添加到Map,我们在Map中删除这个值,释放被创造的值。
*/
V createdValue = create(key);
if (createdValue == null) {
return null;
}
/***************************
* 不覆写create方法走不到下面 *
***************************/
/*
* 正常情况走不到这里
* 走到这里的话 说明 实现了自定义的 create(K key) 逻辑
* 因为默认的 create(K key) 逻辑为null
*/
synchronized (this) {
// 记录 create 的次数
createCount++;
// 将自定义create创建的值,放入LinkedHashMap中,如果key已经存在,会返回 之前相同key 的值
mapValue = map.put(key, createdValue);
// 如果之前存在相同key的value,即有冲突。
if (mapValue != null) {
/*
* 有冲突
* 所以 撤销 刚才的 操作
* 将 之前相同key 的值 重新放回去
*/
map.put(key, mapValue);
} else {
// 拿到键值对,计算出在容量中的相对长度,然后加上
size += safeSizeOf(key, createdValue);
}
}
// 如果上面 判断出了 将要放入的值发生冲突
if (mapValue != null) {
/*
* 刚才create的值被删除了,原来的 之前相同key 的值被重新添加回去了
* 告诉 自定义 的 entryRemoved 方法
*/
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
// 上面 进行了 size += 操作 所以这里要重整长度
trimToSize(maxSize);
return createdValue;
}
}上述的
get方法表面并没有看出哪里有实现了 LRU 的缓存策略。主要在mapValue = map.get(key);里,调用了 LinkedHashMap 的 get 方法,再加上 LruCache 构造里默认设置 LinkedHashMap 的 accessOrder=true。
LinkedHashMap.get(Object key)
/**
* Returns the value of the mapping with the specified key.
*
* @param key
* the key.
* @return the value of the mapping with the specified key, or {@code null}
* if no mapping for the specified key is found.
*/
@Override public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
}
return null;
}其实仔细看
if (accessOrder)的逻辑即可,如果accessOrder=true那么每次get都会执行 N 次makeTail(LinkedEntry<K, V> e)。接下来看看:
LinkedHashMap.makeTail(LinkedEntry e)
/**
* Relinks the given entry to the tail of the list. Under access ordering,
* this method is invoked whenever the value of a pre-existing entry is
* read by Map.get or modified by Map.put.
*/
private void makeTail(LinkedEntry e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
}Unlink e
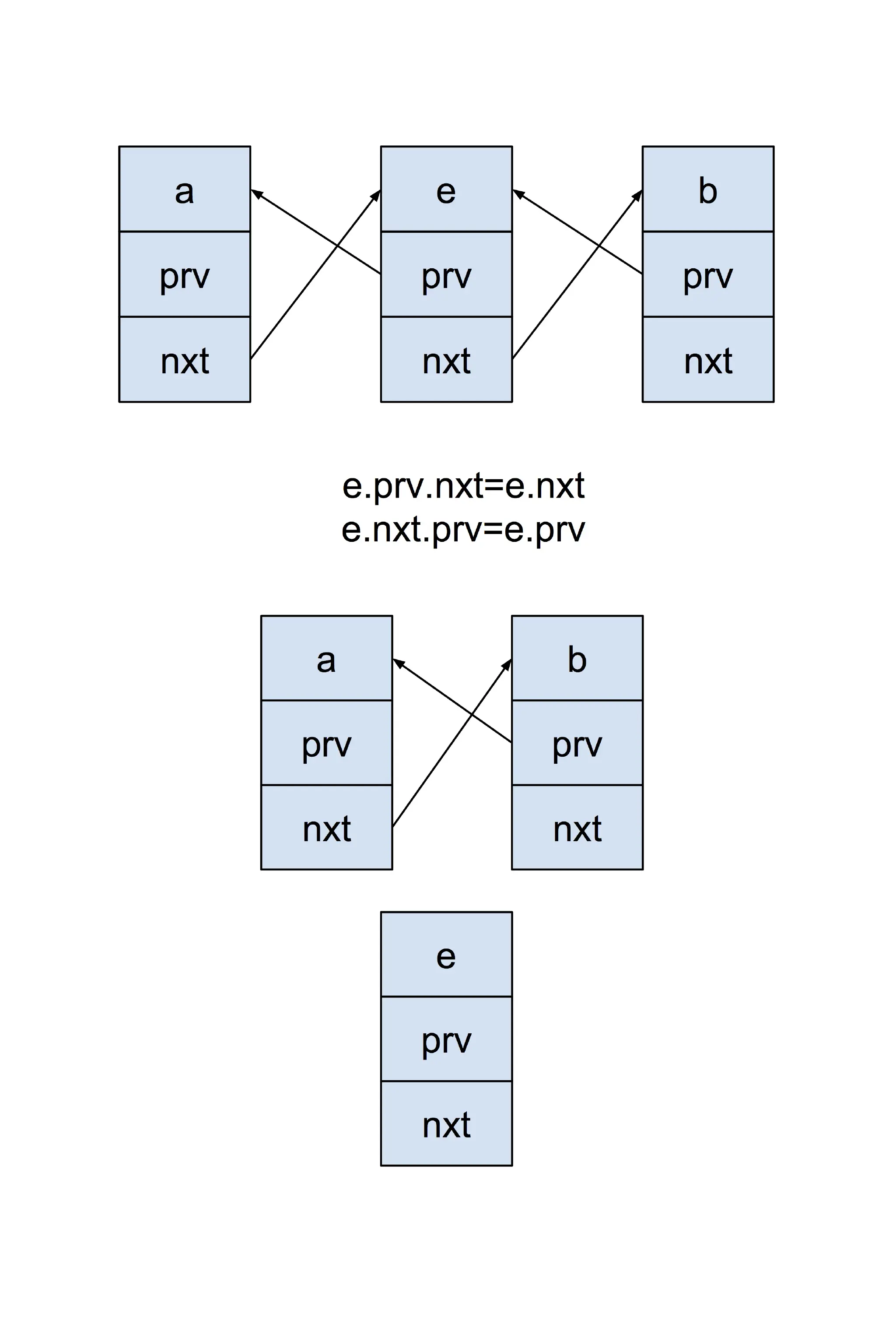
Relink e as tail
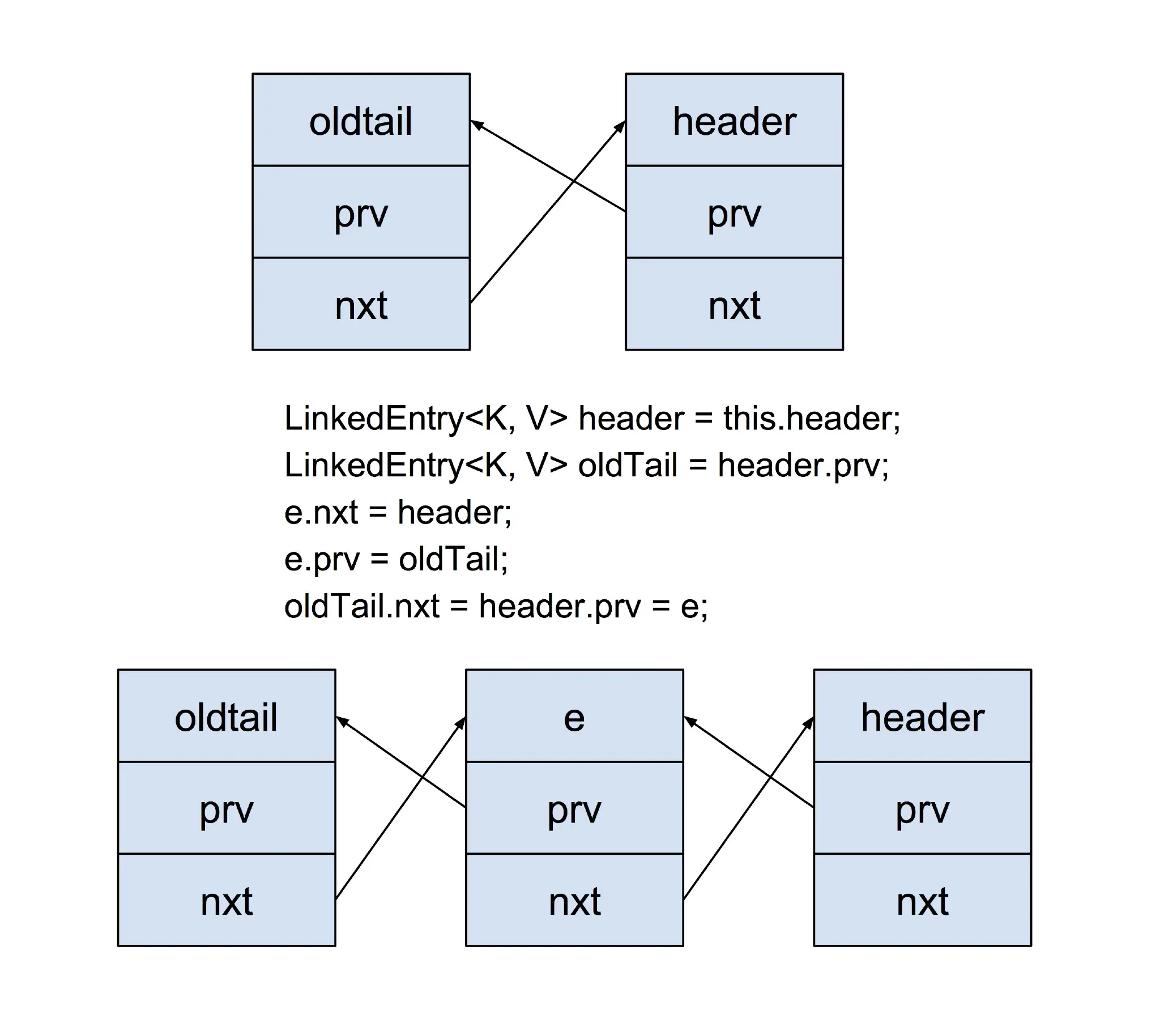
LinkedHashMap 是双向循环链表,然后此次 LruCache.get -> LinkedHashMap.get 的数据就被放到最末尾了。
以上就是 LruCache 核心工作原理。
接下来介绍 LruCache 的容量溢出策略。
LruCache.put(K key, V value)
public final V put(K key, V value) {
...
synchronized (this) {
...
// 拿到键值对,计算出在容量中的相对长度,然后加上
size += safeSizeOf(key, value);
...
}
...
trimToSize(maxSize);
return previous;
}记住几点:
- put 开始的时候确实是把值放入 LinkedHashMap 了,不管超不超过你设定的缓存容量。
- 然后根据
safeSizeOf方法计算 此次添加数据的容量是多少,并且加到size里 。- 说到
safeSizeOf就要讲到sizeOf(K key, V value)会计算出此次添加数据的大小 。- 直到 put 要结束时,进行了
trimToSize才判断size是否 大于maxSize然后进行最近很少访问数据的移除。
LruCache.trimToSize(int maxSize)
public void trimToSize(int maxSize) {
/*
* 这是一个死循环,
* 1.只有 扩容 的情况下能立即跳出
* 2.非扩容的情况下,map的数据会一个一个删除,直到map里没有值了,就会跳出
*/
while (true) {
K key;
V value;
synchronized (this) {
// 在重新调整容量大小前,本身容量就为空的话,会出异常的。
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(
getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
// 如果是 扩容 或者 map为空了,就会中断,因为扩容不会涉及到丢弃数据的情况
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
// 拿到键值对,计算出在容量中的相对长度,然后减去。
size -= safeSizeOf(key, value);
// 添加一次收回次数
evictionCount++;
}
/*
* 将最后一次删除的最少访问数据回调出去
*/
entryRemoved(true, key, value, null);
}
}简单描述:会判断之前
size是否大于maxSize。是的话,直接跳出后什么也不做。不是的话,证明已经溢出容量了。由makeTail图已知,最近经常访问的数据在最末尾。拿到一个存放 key 的 Set,然后一直一直从头开始删除,删一个判断是否溢出,直到没有溢出。
最后看看:
覆写 entryRemoved 的作用
entryRemoved被LruCache调用的场景:
- put 发生 key 冲突时被调用,evicted=false,key=此次 put 的 key,oldValue=被覆盖的冲突 value,newValue=此次 put 的 value。
- trimToSize 的时候,只会被调用一次,就是最后一次被删除的最少访问数据带回来。evicted=true,key=最后一次被删除的 key,oldValue=最后一次被删除的 value,newValue=null(此次没有冲突,只是 remove)。
- remove的时候,存在对应 key,并且被成功删除后被调用。evicted=false,key=此次 put的 key,oldValue=此次删除的 value,newValue=null(此次没有冲突,只是 remove)。
- (get后半段,查询丢失后处理情景,不过建议忽略) get 的时候,正常的话不实现自定义
create的话,代码上看 get 方法只会走一半,如果你实现了自定义的create(K key)方法,并且在 你 create 后的值放入 LruCache 中发生 key 冲突时被调用,evicted=false,key=此次 get 的 key,oldValue=被你自定义 create(key)后的 value,newValue=原本存在 map 里的 key-value。解释一下第四点吧:
<1>.第四点是这样的,先 get(key),然后没拿到,丢失。
<2>.如果你提供了 自定义的
create(key)方法,那么 LruCache 会根据你的逻辑自造一个 value,但是当放入的时候发现冲突了,但是已经放入了。<3>.此时,会将那个冲突的值再让回去覆盖,此时调用上述4.的 entryRemoved。因为 HashMap 在数据量大情况下,拿数据可能造成丢失,导致前半段查不到,你自定义的
create(key)放入的时候发现又查到了(有冲突)。然后又急忙把原来的值放回去,此时你就白白create一趟,无所作为,还要走一遍entryRemoved。综上就如同注释写的一样:
/**
* 1.当被回收或者删掉时调用。该方法当value被回收释放存储空间时被remove调用
* 或者替换条目值时put调用,默认实现什么都没做。
* 2.该方法没用同步调用,如果其他线程访问缓存时,该方法也会执行。
* 3.evicted=true:如果该条目被删除空间 (表示 进行了trimToSize or remove) evicted=false:put冲突后 或 get里成功create后
* 导致
* 4.newValue!=null,那么则被put()或get()调用。
*/
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {
}LruCache局部同步锁
在
get,put,trimToSize,remove四个方法里的entryRemoved方法都不在同步块里。因为entryRemoved回调的参数都属于方法域参数,不会线程不安全。本地方法栈和程序计数器是线程隔离的数据区
总结
LruCache重要的几点:
- LruCache 是通过 LinkedHashMap 构造方法的第三个参数的
accessOrder=true实现了LinkedHashMap的数据排序基于访问顺序 (最近访问的数据会在链表尾部),在容量溢出的时候,将链表头部的数据移除。从而,实现了 LRU 数据缓存机制。- LruCache 在内部的get、put、remove包括 trimToSize 都是安全的(因为都上锁了)。
- LruCache 自身并没有释放内存,将 LinkedHashMap 的数据移除了,如果数据还在别的地方被引用了,还是有泄漏问题,还需要手动释放内存。
- 覆写
entryRemoved方法能知道 LruCache 数据移除是是否发生了冲突,也可以去手动释放资源。maxSize和sizeOf(K key, V value)方法的覆写息息相关,必须相同单位。( 比如 maxSize 是7MB,自定义的 sizeOf 计算每个数据大小的时候必须能算出与MB之间有联系的单位 )
本文标题:LruCache源码解析
文章作者:Hpw123
发布时间:2016-12-31, 12:25:00
最后更新:2016-12-31, 15:57:19
原始链接:hpw123.coding.me/2016/12/31/…
许可协议: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。
RecyclerView源码解析 Glide源码分析