

上一篇文章我和大家一起解读了HashMap的原理源码,各位童鞋可以点击链接查看线性表数据结构解读(五)哈希表结构-HashMap
这次我们一起来看一下LinkedHashMap,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。就LinkedHashMap而言,它继承了HashMap,底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
- 第一种和队列一样默认是按插入顺序排序,先进来的是最老的元素,放在队头,将来会被先移出去,最后进来的是新的元素。
- 第二种,基于访问排序,那么调用get方法后,会将每次访问的元素移至队尾,将来移除的时候移除的是队头,最先访问的元素最后才被移除,不断访问可以形成按访问顺序排序的链表。
下图是我在小黑板手绘的双链回环循环链表
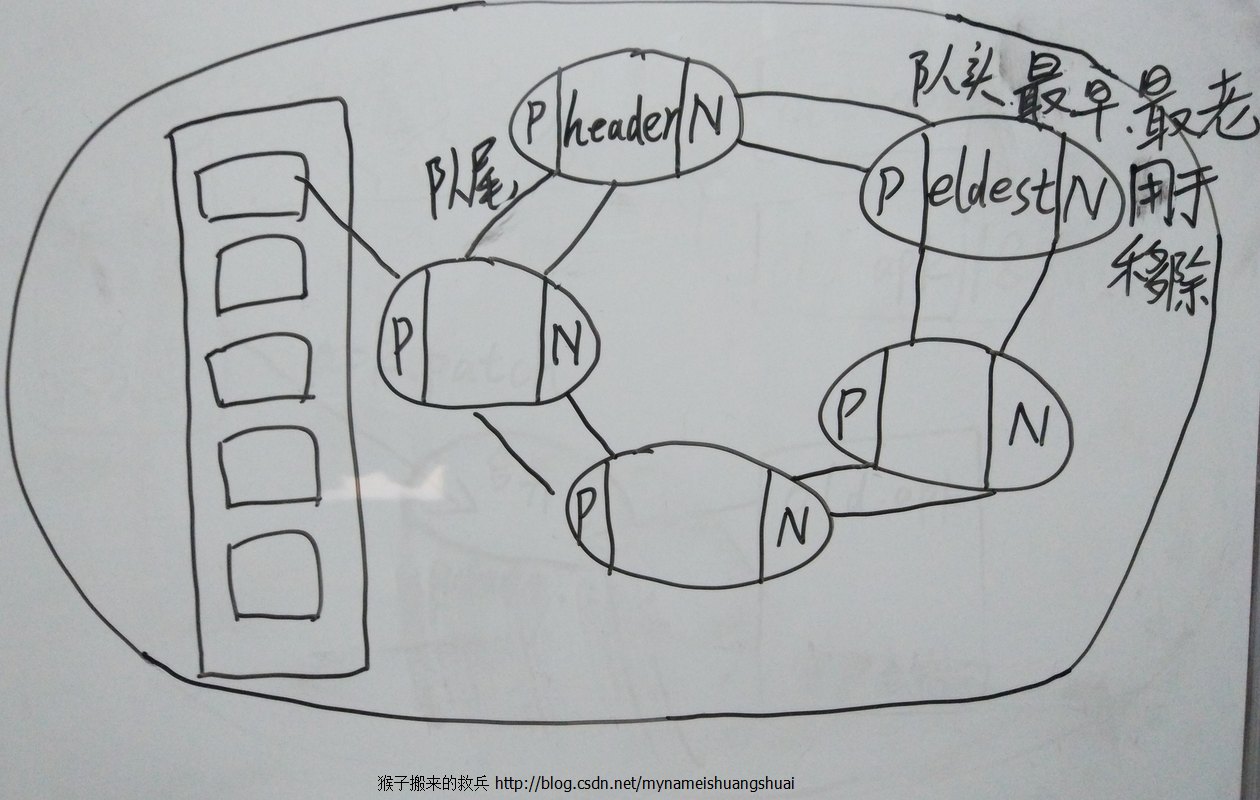
下面我们一起来分析一下LinkedHashMap的源码:
初始化及构造方法
/**
* 双链回环循环链表
*/
public class LinkedHashMap extends HashMap {
/**
* 双向链表的头结点
*/
transient LinkedEntry header;
/**
* true通过访问来排序,false通过插入排序
*/
private final boolean accessOrder;
/**
* Constructs a new empty {@code LinkedHashMap} instance.
*/
public LinkedHashMap() {
init();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, false);
}
public LinkedHashMap(
int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
}
public LinkedHashMap(Map map) {
this(capacityForInitSize(map.size()));
constructorPutAll(map);
@Override
void init() {
header = new LinkedEntry();
}
/**
* 继承HashMap的Entry元素,又保存了其上一个元素before和下一个元素after的引用
*/
static class LinkedEntry extends HashMapEntry {
LinkedEntry nxt;
LinkedEntry prv;
/** Create the header entry */
LinkedEntry() {
super(null, null, 0, null);
nxt = prv = this;
}
/** Create a normal entry */
LinkedEntry(K key, V value, int hash, HashMapEntry next,
LinkedEntry nxt, LinkedEntry prv) {
super(key, value, hash, next);
this.nxt = nxt;
this.prv = prv;
}
}
/**
* 拿到最老的元素
* Returns the eldest entry in the map, or {@code null} if the map is empty.
* @hide
*/
public Entry eldest() {
LinkedEntry eldest = header.nxt;
return eldest != header ? eldest : null;
}
}addNewEntry方法
/**
* 重写了HashMap中的添加新元素方法
*/
@Override
void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry header = this.header;
LinkedEntry eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {
remove(eldest.key);
}
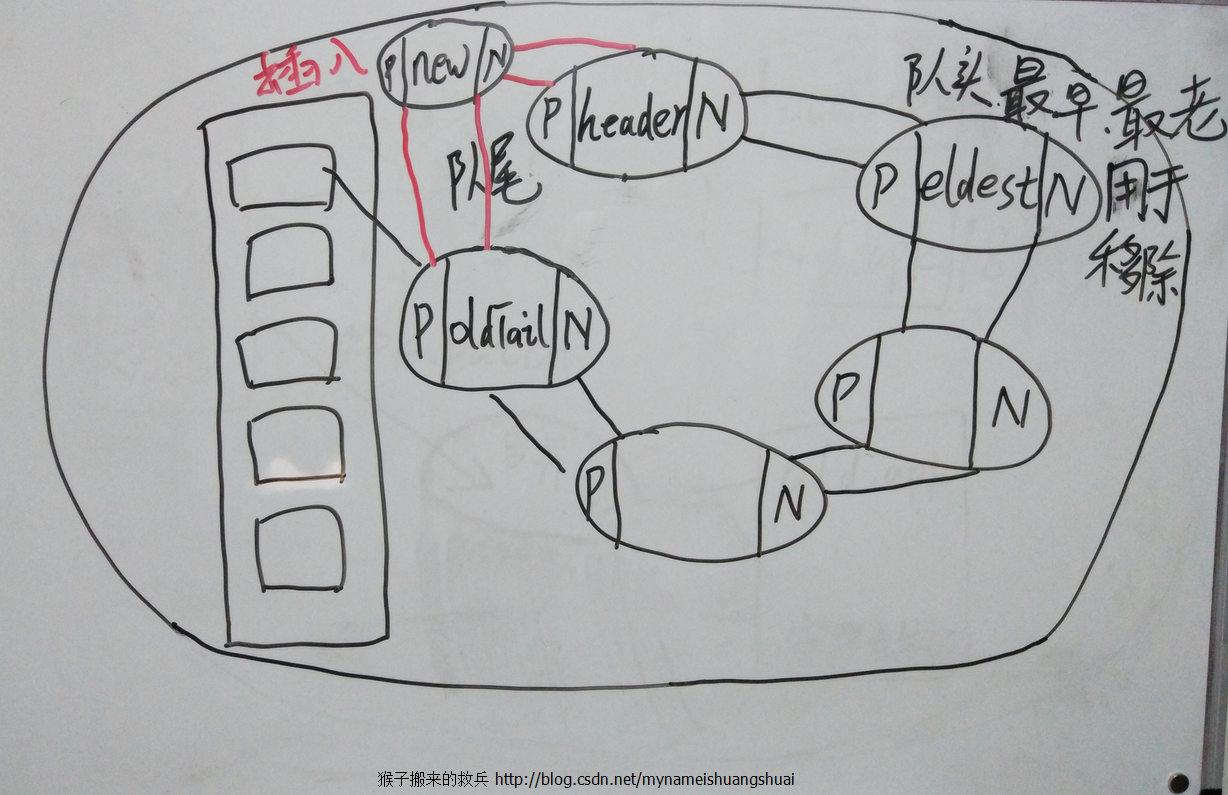
LinkedEntry oldTail = header.prv;
LinkedEntry newTail = new LinkedEntry(
key, value, hash, table[index], header, oldTail);
table[index] = oldTail.nxt = header.prv = newTail;
}下图是我在小黑板手绘的插入方法实现原理图,注意其中指针的变化:
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}get方法
/**
* Returns the value of the mapping with the specified key.
* @param key the key.
* @return the value of the mapping with the specified key, or {@code null}
* if no mapping for the specified key is found.
*/
@Override public V get(Object key) {
if (key == null) {
HashMapEntry e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry[] tab = table;
for (HashMapEntry e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry) e);
return e.value;
}
}
return null;
}下面博文,我将为大家带来LinkedHashMap的最佳实践:LruCache缓存算法的解析,敬请查阅LinkedHashMap最佳实践:LruCache
